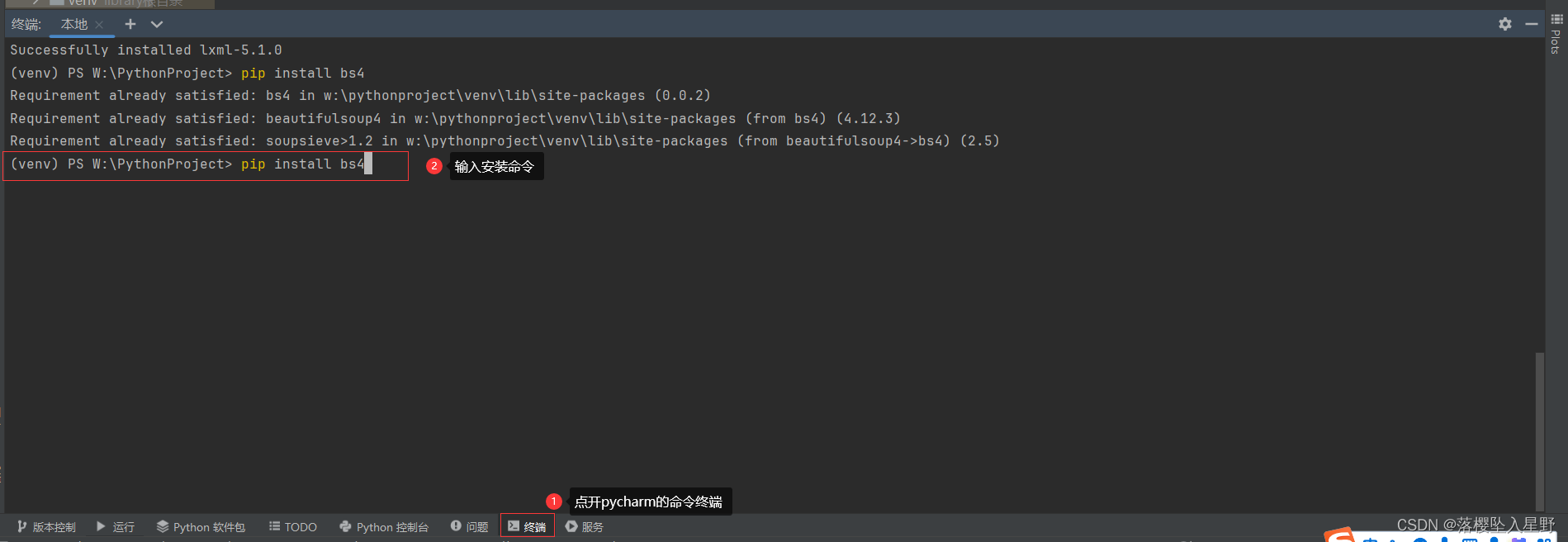
爬虫题目你敢试试吗?
引言
最近在做什么呢
建立一套完整的信息输入输出系统
在我上一次炒股的过程中
我深刻意识到
打工的我是麻木的
打工的我是闭塞的
打工的我是得过且过的

加上工作性质
也不可能跟别人有太多的交流
所以信息获取渠道基本为0
然
重新打工的我
决定要建立一套完善的信息获取来源系统
帮助我能够嗅到风口的味道

所以 我才发布了这篇文章
人民日报霸榜微信区、国足背后的利益下台?——每日信息输入
从今天
开始我的信息输入
然
这个只是一些新闻
还不足以体现经济市场
我还需要进一步下沉到市场中
遂
我找了张大妈这个平台
里面的电脑数码区
爬取里面的价格
获取其中动态

具体原因
什么值得买
有很多的电脑产品爆料
可以一定程度上面反应科技界的发展变化
比如 2023年年中 的硬盘降价 探寻原因 发现国产的存储在崛起
是一个很不错的题材

网站
最终我选定了这个网站,这也是我长久以来一直关注的
有时候价格不错的产品
我就会出手

https://faxian.smzdm.com/h3s0t0f163c5p1/#filter-block
思路
总体
爬取网址:https://faxian.smzdm.com/h3s0t0f163c5p1/#filter-block(什么值得买的12小时热榜、电脑数码专区)
爬取目标:

- 主图
- 平台
- 标题
- 价格
- 评论数
- 链接
初步目标是先爬取这些信息
后面再进一步整理
当然这些信息爬取出来之后
也是要做可视化处理的
不能是简单的数据
那样
就没什么意思了
我让AI给个框架
编写一个爬虫程序来抓取“什么值得买”网站的12小时热榜(电脑数码专区)信息
1. 项目初始化与依赖安装
- 创建一个新的Python项目目录。
- 使用
pip安装必要的库,如requests用于发送HTTP请求,beautifulsoup4或lxml用于解析HTML内容,以及pandas用于数据处理和存储。
pip install requests beautifulsoup4 pandas
2. 定义数据模型
- 定义一个数据类或字典结构来存储每条商品详情,包括主图URL、平台名称、标题、价格、评论数及链接。
class Product:
def __init__(self, main_img_url, platform, title, price, comments_count, link):
self.main_img_url = main_img_url
self.platform = platform
self.title = title
self.price = price
self.comments_count = comments_count
self.link = link
3. 网络请求模块
- 创建一个函数用于发送GET请求到目标网址,并返回网页内容。
import requests
def fetch_page_content(url):
headers = {...} # 添加合适的请求头,例如User-Agent等
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查响应状态码
return response.text
4. 页面解析模块
- 使用BeautifulSoup解析HTML内容,定位到包含商品信息的部分,并遍历提取所需字段。
from bs4 import BeautifulSoup
def parse_product_info(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
product_list = []
# 找到商品列表元素(具体CSS选择器需要根据实际HTML结构确定)
product_elements = soup.select('.product-list-item') # 假设这是商品容器的选择器
for item in product_elements:
# 提取每个商品的信息
main_img = item.find('img')['src'] # 主图URL
platform = item.find('.platform').text # 平台名称
title = item.find('.title').text # 标题
price = item.find('.price').text # 价格
comments_count = item.find('.comments-count').text # 评论数
link = item.find('.link')['href'] # 商品链接
# 将信息封装为Product对象并添加到产品列表中
product = Product(main_img, platform, title, price, comments_count, link)
product_list.append(product)
return product_list
5. 数据存储模块
- 将抓取到的商品信息保存到本地文件,可以选择CSV、JSON或者数据库等形式。
import pandas as pd
def save_to_csv(products):
df = pd.DataFrame([vars(p) for p in products]) # 将Product对象转为DataFrame
df.to_csv('smzdm_products.csv', index=False) # 存储为CSV文件
6. 主程序流程
- 组织整个爬虫流程,调用上述各模块方法。
if __name__ == '__main__':
target_url = "https://faxian.smzdm.com/h3s0t0f163c5p1/#filter-block"
# 获取网页内容
content = fetch_page_content(target_url)
# 解析内容获取商品信息
products = parse_product_info(content)
# 存储结果
save_to_csv(products)
请根据实际网页源代码调整CSS选择器以正确匹配所需的数据节点。

AI,还得是您呀!
结尾
我想着是要做完再发
还是这种形式
问了边做再发
最后
决定这一种
两个原因
- 我渴了
- 我希望能够吸引更多的人互动,参与进来
整体的代码明天发,最迟后天,看情况
那么

原文地址:https://blog.csdn.net/qq_39471885/article/details/135934907
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65083.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!