本文介绍: Mnist分类任务流程详解,完整代码,输出结果
一.Mnist分类任务流程详解
1.1.引入数据集
Mnist数据集是官方的数据集,比较特殊,可以直接通过%matplotlib inline自动下载,博主此处已经完成下载,从本地文件中引入数据集。
设置数据路径
from pathlib import Path
# 设置数据路径
# PATH = Path("data/minst")
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
# PATH.mkdir(parents=True, exist_ok=True) # 父目录不存在时创建父目录
'''
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
'''
读取数据
import pickle
import gzip
# 读取数据
'''
gzip.open的作用是解压gzip文件
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
# rb表示以二进制格式打开一个文件用于只读
# 打开PATH路径的文件用以接下来的操作
# 保存数据的文件类型为pickle,所以用pickle.load打开文件,文件此处设置的别名为f
with open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
as.posix()的作用:
#返回使用斜杠(/)分割路径的字符串
#将所有连续的正斜杠、反斜杠,统一修改为单个正斜杠
#相对路径 './' 替换为空,'../' 则保持不变。
'''测试引入数据集是否成功
from matplotlib import pyplot
import numpy as np
# 测试数据集是否导入成功
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)

1.2.数据类型转换
数据需要转换成tensor类型才能参与后续建模训练
import torch
# 通过map映射,将x_train等数据全都转为torch.tensor类型。tensor类型才能参与后续建模训练
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
测试数据类型是否转换成功
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())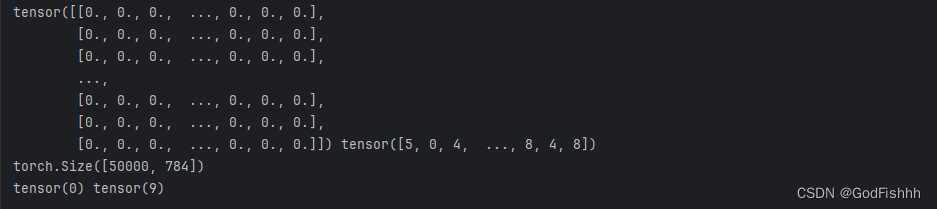
数据均为tensor类型,转换成功
1.3.设置损失函数
import torch.nn.functional as F
# 设置损失函数,此处使用的损失函数为交叉熵
loss_func = F.cross_entropy
测试损失函数
手动设置初始权重和偏置值进行测试,真实情况下系统会自动帮我们初始化
bs = 64
xb = x_train[0:bs] # a mini-batch from x ,xb是x_train中0~64项的数
yb = y_train[0:bs]
# 实际操作中模型会自动定义权重参数,不用我们手动设置
# 因为输入数据是784x1个像素点,而最后得到的是十个类别,所以权重矩阵的大小为784x10。
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
# bias矩阵的大小取决于最后的类别数量,此处的bias矩阵为10x1
bias = torch.zeros(10, requires_grad=True)
def model(xb):
return xb.mm(weights) + bias # .mm()是矩阵相乘 .mul()则是对应位相乘
# 损失函数是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,此处model(xb)得到的是经过权重计算的预测值,yb是真实值。给损失函数传入的参数即为预测值和真实值。
print(loss_func(model(xb), yb))
1.4.神经网络构造
此处所选用的是传统神经网络完成Minist分类任务
from torch import nn
# 创建一个模型类,注意一定要继承于nn.Module(取决于你要创建的网络类型)
class Mnist_NN(nn.Module):
def __init__(self):
# 调用父类的构造函数
super().__init__()
# 创建两个隐层 由784->128->256->10
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
# 创建输出层,由256->10,即最后输出十个类别
self.out = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
# torch框架需要自己定义前向传播,反向传播由框架自己实现
# 传入的x是一个batch x 特征值
def forward(self, x):
# x经过第一个隐层
x = F.relu(self.hidden1(x))
# x经过dropout层
x = self.dropout(x)
# x经过第二个隐藏
x = F.relu(self.hidden2(x))
# x经过dropout层
x = self.dropout(x)
# x经过输出层
x = self.out(x)
return x
测试构造的神经网络
net = Mnist_NN()
print(net)
查看网络中构建好的权重和偏置项
for name, parameter in net.named_parameters():
print(name, parameter,parameter.size())1.5.使用TensorDataset和DataLoader简化数据
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
# TensorDataset获取数据,再由DataLoader打包数据传给GPU(包的大小位batch_size)
# 训练集一般打乱顺序,验证集不打乱顺序
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)1.6.模型训练
优化器设置
from torch import optim
def get_model():
model = Mnist_NN() # 使用先前创建的类构造一个网络
return model, optim.SGD(model.parameters(), lr=0.001)
# 返回值为模型和优化器
# 优化器的设置,optim.SGD(),参数分别为:要优化的参数、学习率
def loss_batch(model, loss_func, xb, yb, opt=None):
# 计算损失,参数为预测值和真实值
loss = loss_func(model.forward(xb), yb) # 预测值由定义的前向传播过程计算处
# 如果存在优化器
if opt is not None:
loss.backward() # 反向传播,算出更新的权重参数
opt.step() # 执行backward()计算出的权重参数的更新
opt.zero_grad() # torch会进行迭代的累加,通过zero_grad()将之前的梯度清空(不同的迭代之间应当是没有关系的)
return loss.item(), len(xb)常用优化器:
- 随机梯度下降(SGD, stochastic gradient descent)
- SGDM(加入了一阶动量)
- AdaGrad(加入了二阶动量)
- RMSProp
- Adam
模型训练
import numpy as np
#epoch和batch的关系,
#eg:有10000个数据,batch=100,则一个1epoch需要训练100个batch(1一个epoch就是训练整个数据一次)
# 定义训练函数,传入的参数分别为:迭代的次数、模型、损失函数、优化器、训练集、验证集
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
# 训练模式:
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt) # 得到由loss_batch更新的权重值
# 验证模式:
model.eval()
with torch.no_grad(): # 没有梯度,即不更新权重参数
# zip将两个矩阵配对,例如两个一维矩阵配对成一个二维矩阵,下述情况中即为一个losses对应一个nums -> [(losses,nums)]。zip*是解包操作,即将二维矩阵又拆分成一维矩阵,并返回拆分得到的一维矩阵。
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) # 计算平均损失:对应的损失值和样本数相乘的总和 / 总样本数
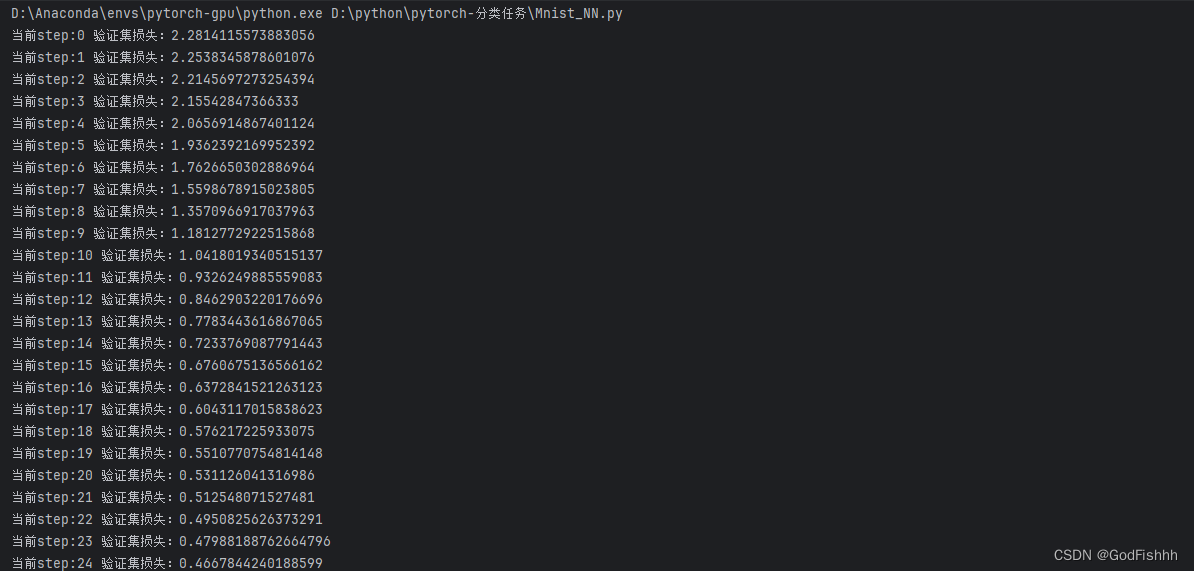
print('当前step:'+str(step), '验证集损失:'+str(val_loss))二.完整代码
from pathlib import Path
import pickle
import gzip
from matplotlib import pyplot
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
from torch import optim
import numpy as np
# 设置数据路径
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist.pkl"
# PATH.mkdir(parents=True, exist_ok=True)
'''
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
'''
# 读取数据
'''
gzip.open的作用是解压gzip文件
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
# rb表示以二进制格式打开一个文件用于只读
# 打开PATH路径的文件用以接下来的操作
# 保存数据的文件类型为pickle,所以用pickle.load打开文件,文件此处设置的别名为f
with open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
'''
as.posix()的作用:
#返回使用斜杠(/)分割路径的字符串
#将所有连续的正斜杠、反斜杠,统一修改为单个正斜杠
#相对路径 './' 替换为空,'../' 则保持不变。
'''
'''
# 测试数据集是否导入成功
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
'''
# 数据类型转换为torch
# 通过map映射,将x_train等数据全都转为torch.tensor类型。tensor类型才能参与后续建模训练
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
# 测试数据类型是否转换成功
'''
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
'''
# 设置损失函数
loss_func = F.cross_entropy
bs = 64
xb = x_train[0:bs] # a mini-batch from x ,xb是x_train中0~64项的数
yb = y_train[0:bs]
'''
# 手动初始化进行测试
# 实际操作中模型会自动定义权重参数,不用我们手动设置
# 因为输入数据是784x1个像素点,而最后得到的是十个类别,所以权重矩阵的大小为784x10。
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
# bias矩阵的大小取决于最后的类别数量,此处的bias矩阵为10x1
bias = torch.zeros(10, requires_grad=True)
def model(xb):
return xb.mm(weights) + bias # .mm()是矩阵相乘 .mul()则是对应位相乘
# 损失函数是用来度量模型的预测值f(x)与真实值Y的差异程度的运算函数,此处model(xb)得到的是经过权重计算的预测值,yb是真实值。给损失函数传入的参数即为预测值和真实值。
print(loss_func(model(xb), yb))
'''
# 创建一个模型类,注意一定要继承于nn.Module(取决于你要创建的网络类型)
class Mnist_NN(nn.Module):
def __init__(self):
# 调用父类的构造函数
super().__init__()
# 创建两个隐层 由784->128->256->10
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
# 创建输出层,由256->10,即最后输出十个类别
self.out = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
# torch框架需要自己定义前向传播,反向传播由框架自己实现
# 传入的x是一个batch x 特征值
def forward(self, x):
# x经过第一个隐层
x = F.relu(self.hidden1(x))
# x经过dropout层
x = self.dropout(x)
# x经过第二个隐藏
x = F.relu(self.hidden2(x))
# x经过dropout层
x = self.dropout(x)
# x经过输出层
x = self.out(x)
return x
'''
# 测试构造的网络模型
net = Mnist_NN()
print(net)
打印权重和偏置项
for name, parameter in net.named_parameters():
print(name, parameter,parameter.size())
'''
# TensorDataset获取数据,再由DataLoader打包数据传给GPU
# 训练集一般打乱顺序,验证集不打乱顺序
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
# 优化器设置
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
# 优化器的设置,optim.SGD(),参数分别为:要优化的参数、学习率
def loss_batch(model, loss_func, xb, yb, opt=None):
# 计算损失,参数为预测值和真实值
loss = loss_func(model.forward(xb), yb) # 预测值由定义的前向传播过程计算处
# 如果存在优化器
if opt is not None:
loss.backward() # 反向传播,算出更新的权重参数
opt.step() # 执行backward()计算出的权重参数的更新
opt.zero_grad() # torch会进行迭代的累加,通过zero_grad()将之前的梯度清空(不同的迭代之间应当是没有关系的)
return loss.item(), len(xb)
# 模型训练
# epoch和batch的关系,
# eg:有10000个数据,batch=100,则一个1epoch需要训练100个batch(1一个epoch就是训练整个数据一次)
# 定义训练函数,传入的参数分别为:迭代的次数、模型、损失函数、优化器、训练集、验证集
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
# 训练模式:
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt) # 得到由loss_batch更新的权重值
# 验证模式:
model.eval()
with torch.no_grad(): # 没有梯度,即不更新权重参数
# zip将两个矩阵配对,例如两个一维矩阵配对成一个二维矩阵,下述情况中即为一个losses对应一个nums -> [(losses,nums)]。zip*是解包操作,即将二维矩阵又拆分成一维矩阵,并返回拆分得到的一维矩阵。
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums) # 计算平均损失:对应的损失值和样本数相乘的总和 / 总样本数
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
# 输出
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(25, model, loss_func, opt, train_dl, valid_dl)
# 准确率的计算
correct = 0
total = 0
for xb,yb in valid_dl:
outputs = model(xb)
_, predicted = torch.max(outputs.data,1) # 返回最大的值和对应的列索引(列索引在此处就是对应的类别) (, 0)则返回行索引
total += yb.size(0) # yb的样本数
correct += (predicted == yb).sum().item( ) # .sum()返回验证正确了的样本数,item()从tensor数据类型中取值,方便后续的画图等(tensor数据类型不好画图)
print('Accuracy of the network on the 10000 test image: %d %%' %(100*correct/total))三.输出结果
原文地址:https://blog.csdn.net/GodFishhh/article/details/135968118
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65107.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。