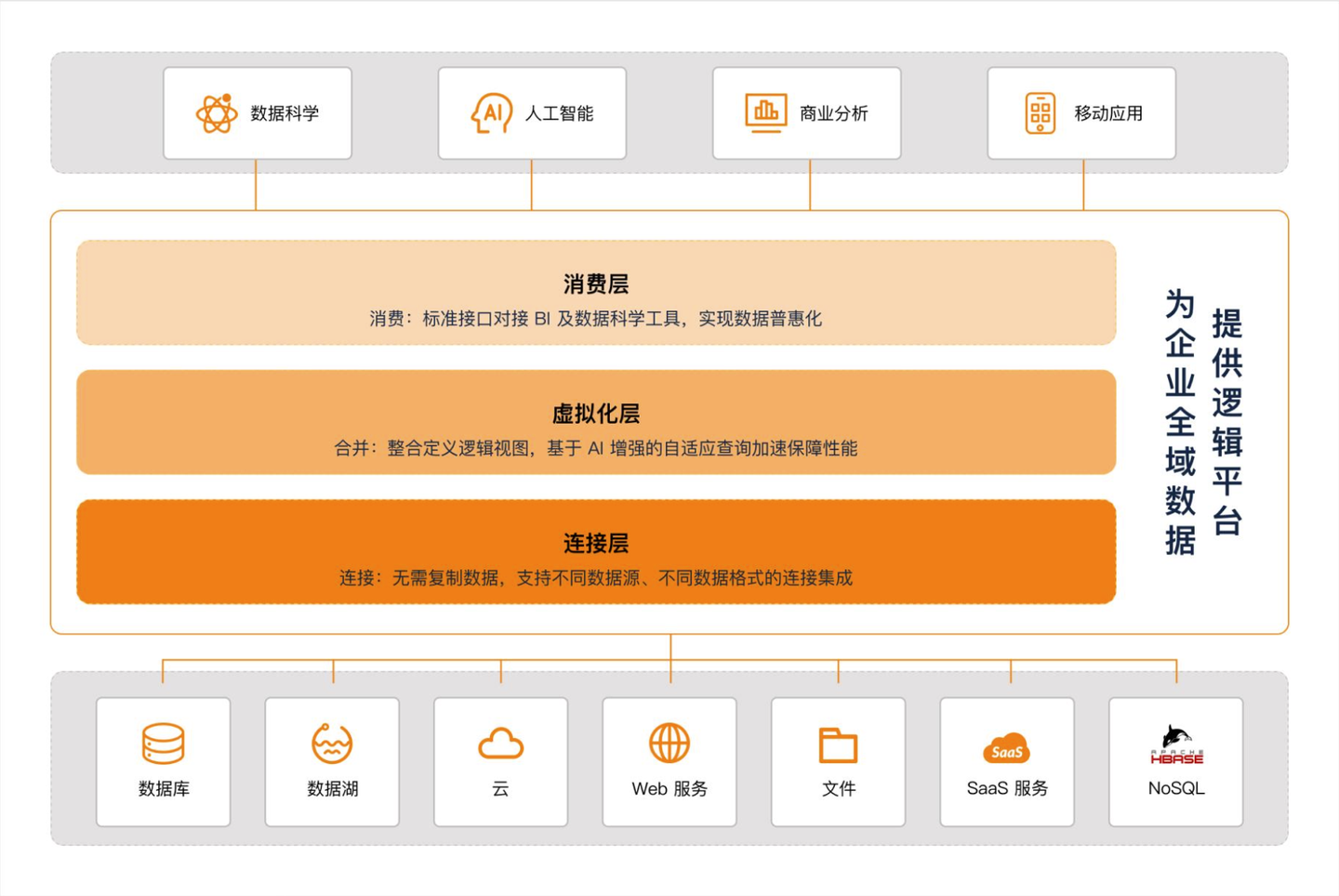
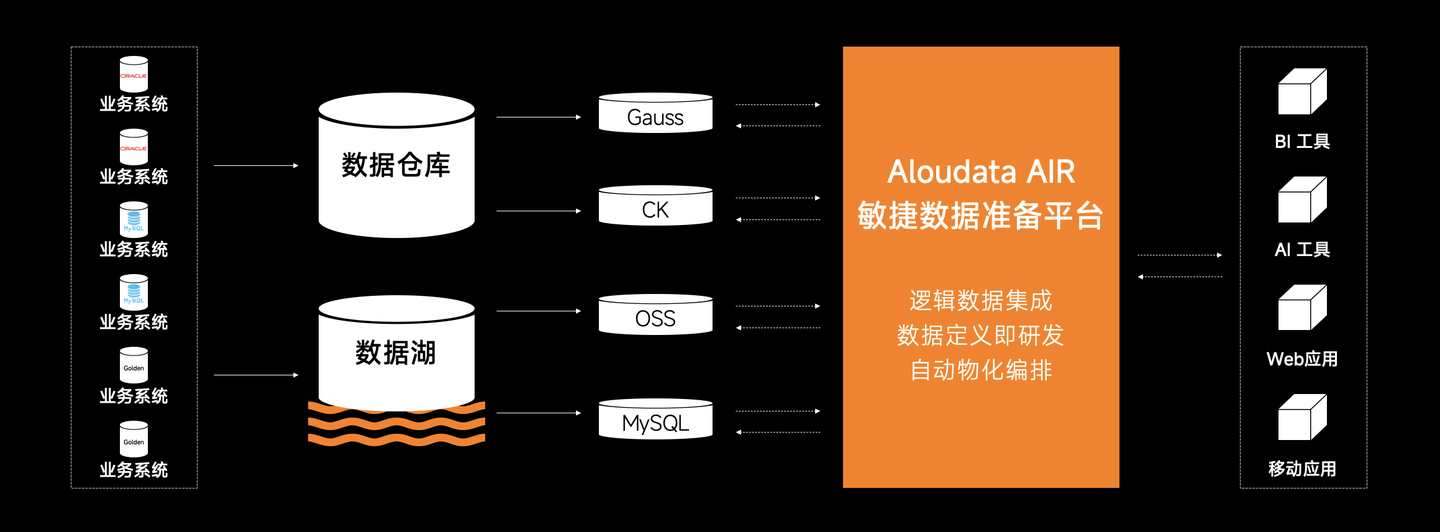
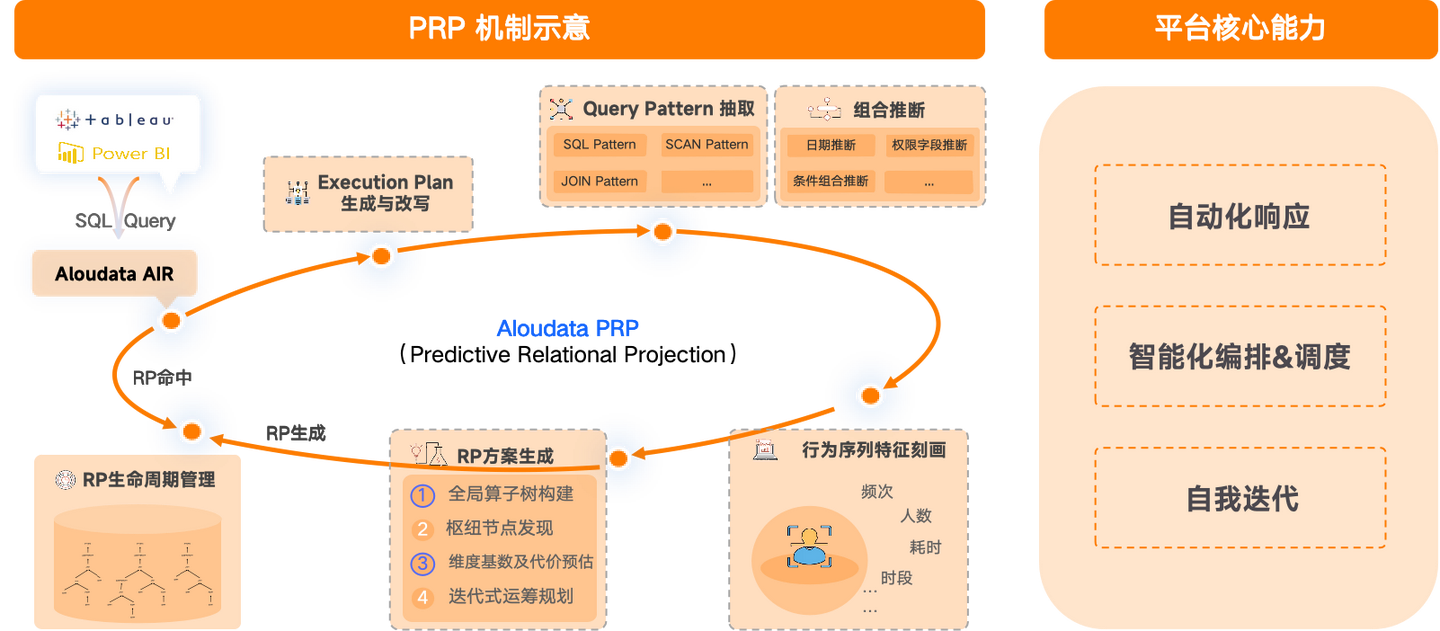
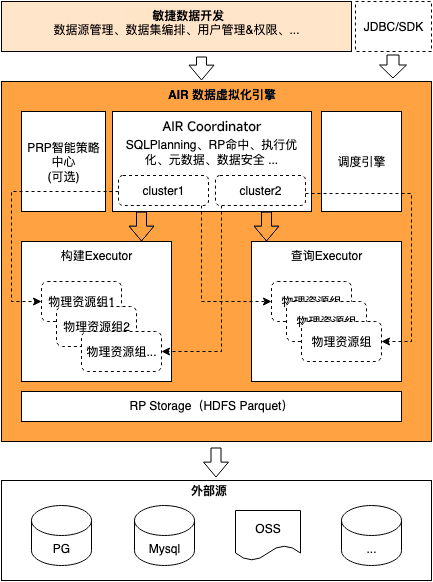
本文介绍: 数据虚拟化的关键在于它提供了一个统一的逻辑数据视图层,在不复制数据的情况下,将不同数据源、不同位置和不同格式的数据进行整合,它隐藏了底层数据存储位置、技术接口、功能特性等的技术复杂性和差异性,并通过逻辑视图层提供统一的数据服务,为多个应用和用户提供支持,从而实现实时的数据访问,减少数据复制搬运成本,提高数据开发与变更的敏捷性。通过上游数据更新事件触发或对元数据的变更监听,可自动推断增量变更,以及自动分区推导,完成大规模数据的下游数据增量更新,免除业务人员对数据更新的关注。
【背景】
随着数字化转型的持续深入,某头部股份制银行把“依托数据洞察提升管理和营销的精准度、实现经营与服务的精细化与个性化”作为参与下一阶段数字化业务竞争的核动力。经过多年的探索,该头部股份制银行数字化技术与业务场景的融合逐渐进入了深水区。
一、源起:敏捷 BI 在各业务条线广泛推广
该行内部已建成一套以数据可视化、自助分析、数据接入等核心组件为一体的数据分析平台,通过赋能行内数据产品建设,服务各业务条线的日常用数。
其中,面向数据分析师的自助用数服务是核心能力,包含了自助制作业务报告、自助探索分析、数据轻加工、增强分析、办公用图表等主要场景。随着该行支撑的数据产品自助化场景逐步拓展,越来越多的用数环节由业务用户自己完成。目前,该行数据平台已经支撑行内批发、零售、财会、运营、风险等条线的数据产品建设,月服务用户超 数 万人。
二、挑战:海量数据规模下的报表查询性能问题
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







