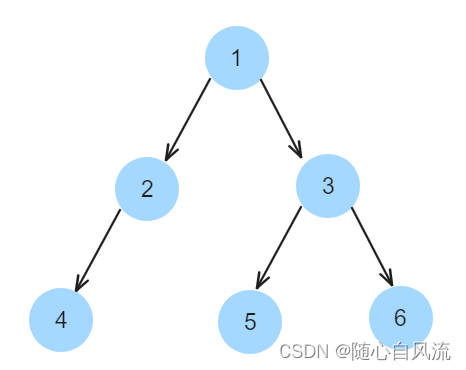
本文介绍: 【决策树】:决策树是一种描述对样本数据进行分类的树形结构模型,由节点和有向边组成。其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。理解:它是一个树状结构,其中每个节点代表一个特征属性的判断,每个分支代表这个判断的结果,而每个叶节点(叶子)代表一种类别或回归值。包含整个数据集,并通过某个特征属性进行判断。从根节点出发的每个路径,代表在某个特征属性上的判断结果。在决策路径上的非叶节点,表示对某个特征属性的判断。
📕参考:ysu老师课件+西瓜书
1.决策树的基本概念

【决策树】:决策树是一种描述对样本数据进行分类的树形结构模型,由节点和有向边组成。其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
关于决策树要掌握的概念:
决策树的优缺点:
优点:
2.决策树的生成过程
2.1 特征变量的选择
2.1.1 信息增益
2.1.2 信息增益比

2.1.3 Gini指数

2.2 决策树的生成
2.2.1 ID3——信息增益

2.2.2 C4.5——信息增益比
2.2.3 CART——Gini指数

2.3 决策树的剪枝
2.3.1 预剪枝
2.3.2 后剪枝
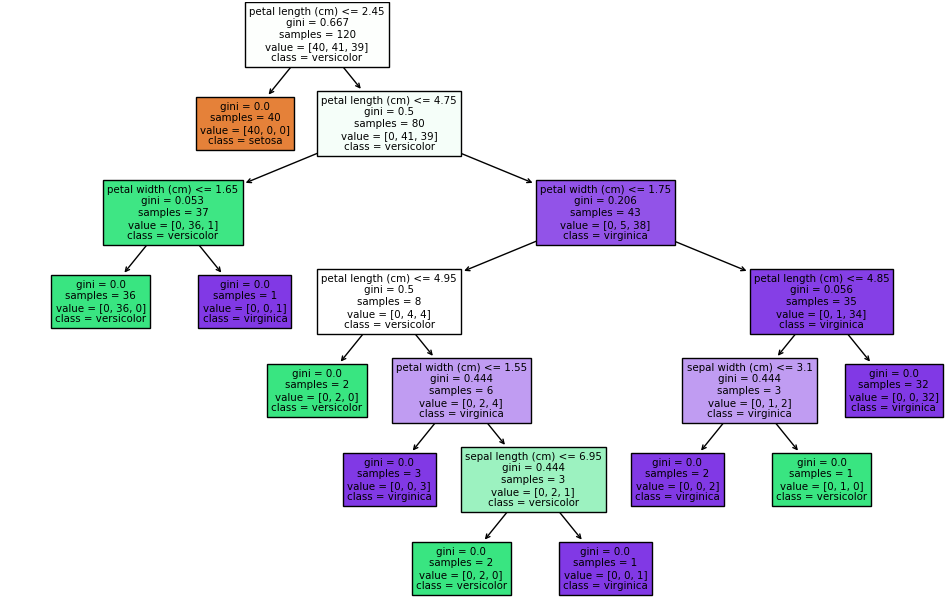
3.代码实践
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。