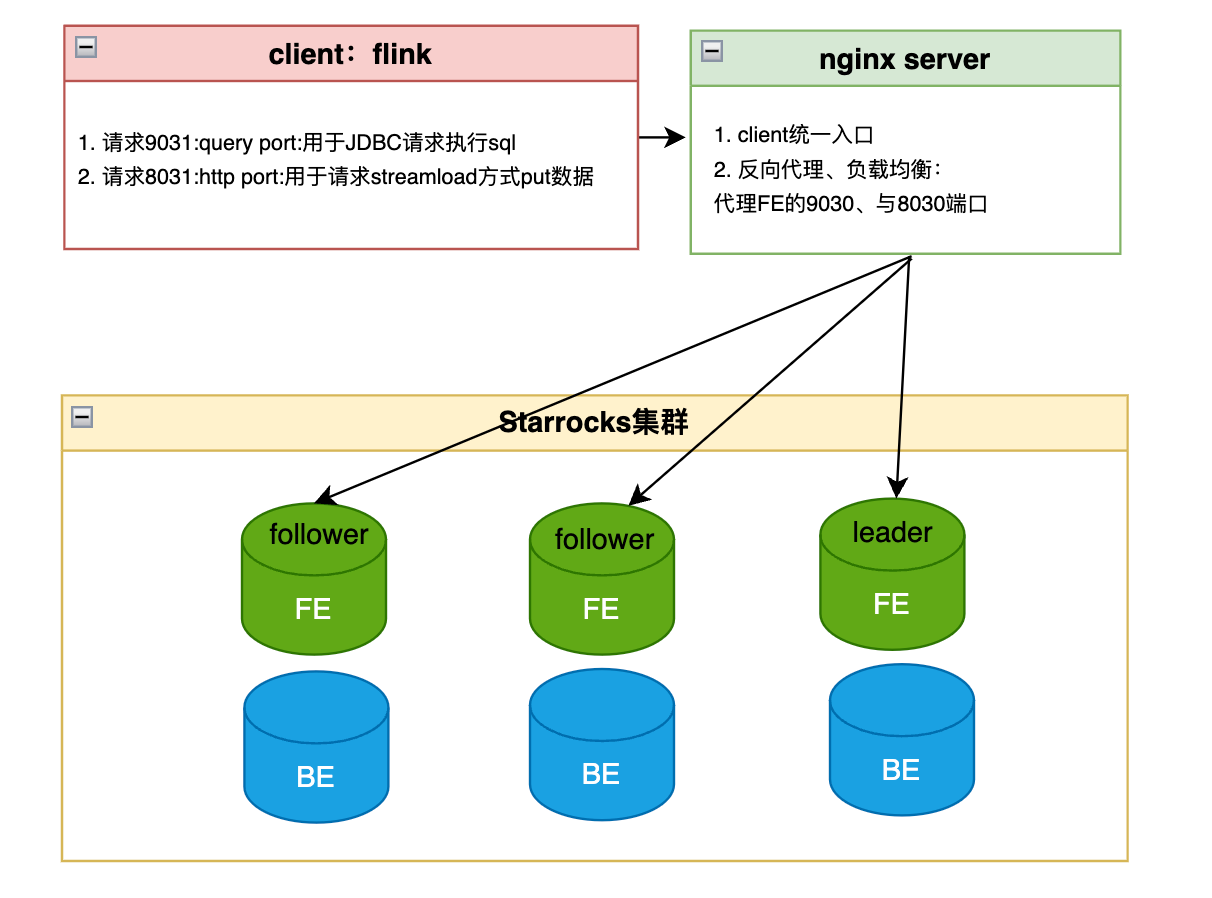
本文介绍: 基于starRocks官方文档,对其内容进行一定解析,方便大家理解和使用。若无特殊标注,startRocks版本是3.2。下面的章节和官方文档保持一致。
背景说明
基于starRocks官方文档,对其内容进行一定解析,方便大家理解和使用。
若无特殊标注,startRocks版本是3.2。
下面的章节和官方文档保持一致。
参考文档
StarRocks
查询加速
CBO统计信息
采用 Cascades 框架。简单描述,就是判断预估来优化重型SQL的执行策略。具体内容,可以自行了解。
CBO 统计信息 | StarRocks
同步物化视图
同步物化视图和异步物化视图比较。
从下图比较中可以看到,同步物化视图的功能比较简单,基本上是两个场景,分别是map映射和简单聚合。
map映射:实现字段间转换,例如时间戳转换为日期,string转int
简单聚合:计数器类的函数,单表groupby维度信息,计算sum、max、min等可以直接比较的函数
同步物化视图支持的函数:
异步物化视图
和同步物化视图进行比较,比较内容参考从上。
Colocate Join
使用 Lateral Join 实现列转行
Query Cache
索引
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)
![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)