本文介绍: 在微服务架构下,一个 k8s 集群中经常会部署多套业务,同时也意味着不同团队、不同角色、不同的业务会在同一集群中,需要将不同业务的数据在不同的空间进行管理和查看。
简介
在微服务架构下,一个 k8s 集群中经常会部署多套业务,同时也意味着不同团队、不同角色、不同的业务会在同一集群中,需要将不同业务的数据在不同的空间进行管理和查看。
在传统的主机环境下,这个是可以通过不同的主机部署 DataKit 时配置不同的工作空间 token 轻松实现,但是在 k8s 环境下使用 DaemonSet 方式部署,同一个 DaemonSet 无法灵活的进行多套 DataKit 配置,且在配置变更时需要重启 DataKit,当 DataKit 达到一定规模影响非常大。
因此,观测云提供的 DataWay Sinker 功能,便成为了以上问题的最佳解决方案。
方案介绍
方案流程
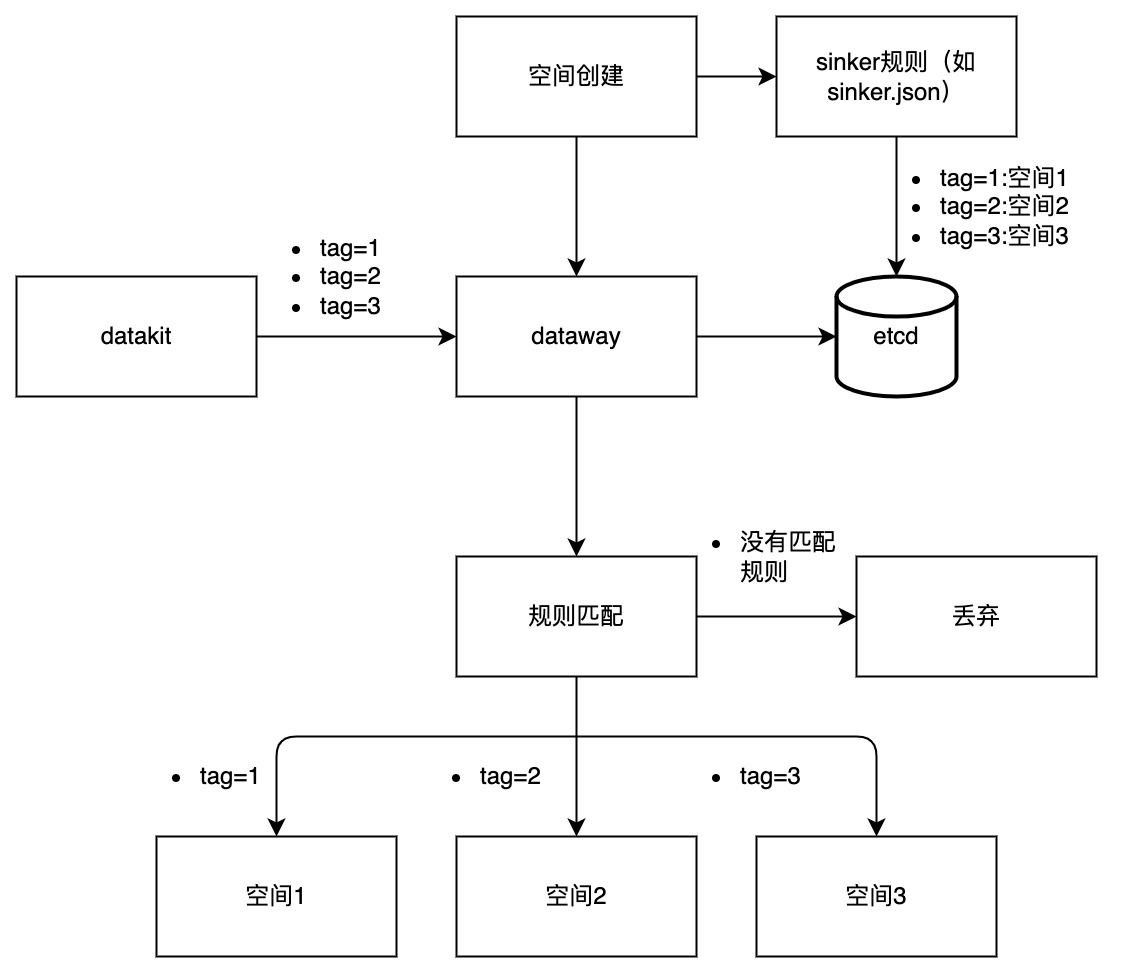
通过上图不难看出,该方案最重要的部分在于进行数据 TAG(标签)管理。数据分流是否达到预期、是否准确、是否实用都取决于 TAG 标签的合理使用以及规划管理。而 TAG 的管理和使用恰好是观测云平台的核心能力之一。
方案实践
实践背景

步骤一:安装 Dataway
步骤二:编辑分流规则
步骤三:修改 DataKit 配置
最终效果

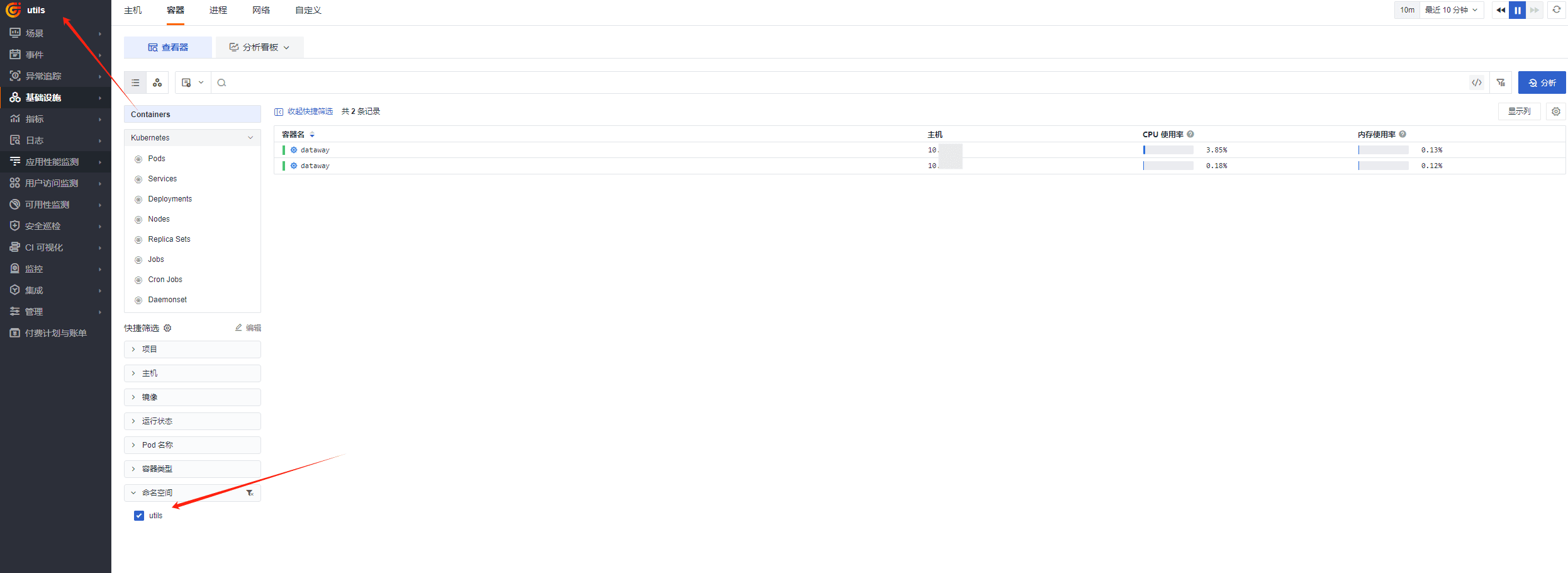
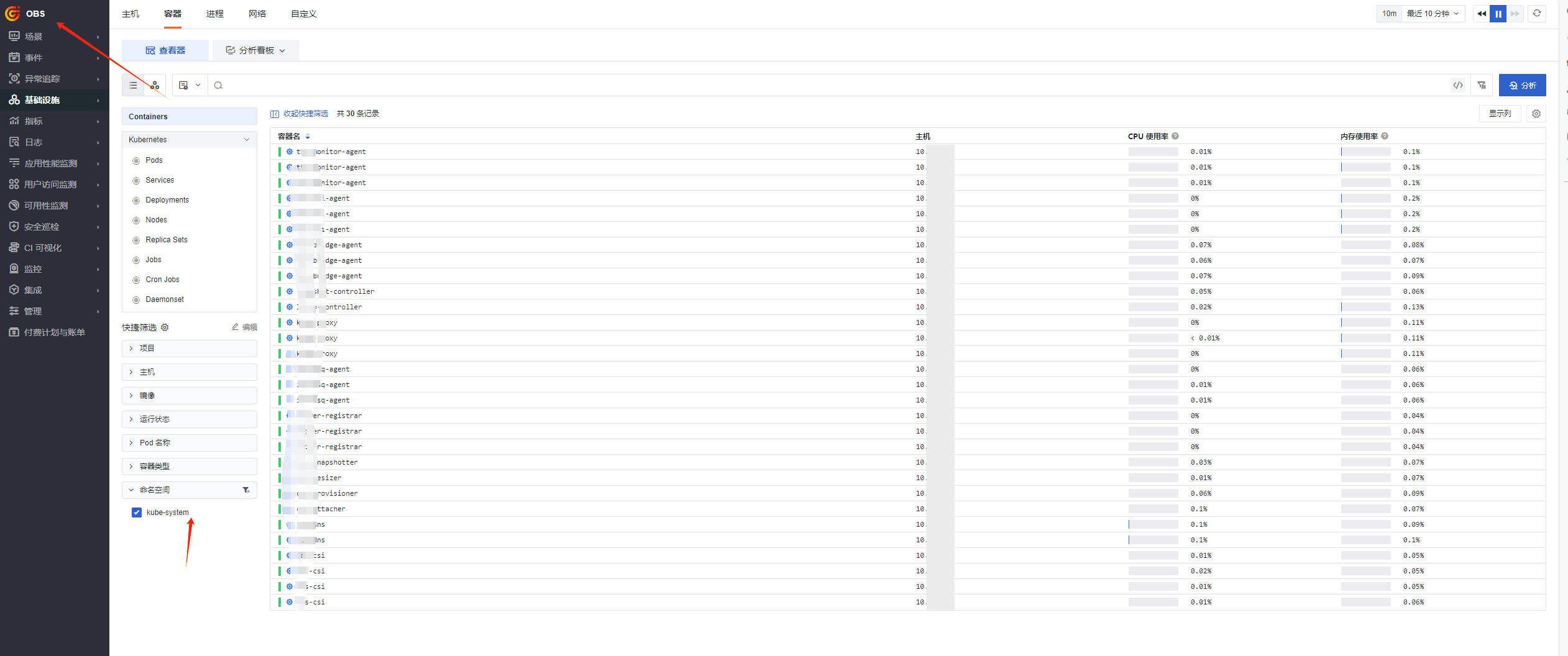
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






