一、前言
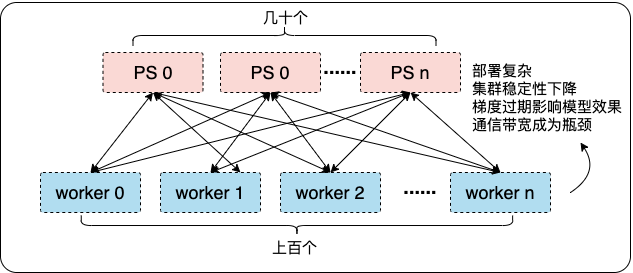
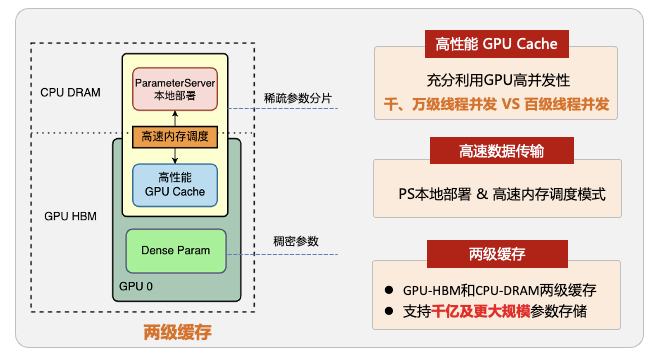
京东广告训练框架随着广告算法业务发展的特点也在快速迭代升级,回顾近几年大致经历了两次大版本的方案架构演变。第一阶段,随着2016年Tensorflow训练框架的开源,业界开始基于Tensorflow开源框架训练更复杂的模型。模型对特征规模和参数规模需求不断提升,大规模稀疏模型具有更强的表征能力,逐渐成为算法的主流趋势。但是Tensorflow在大规模稀疏参数的训练机制不完备,因此第一次最大能力升级是通过自研高性能参数服务器,支持超大规模TB级稀疏参数模型的建模能力以及基于此架构支持在线学习的能力。 第二阶段,随着用户行为序列建模、多模态建模、多目标等算法技术的发展,模型变得既宽且深,计算算力、通信性能和存储容量逐渐成为瓶颈。基于之前的方案虽然有可能通过扩大训练集群规模满足训练需求,但是在节点拓扑的复杂度、参数通信性能、集群稳定性和模型效果等多个方面都存在较大的问题。随着更先进的NVIDIA A100 等训练GPU硬件资源的出现,基于高性能GPU算力构建的新一代软硬深度结合的训练方案成为第二次架构演变的主要方向。接下来,本文将针对大规模稀疏场景,结合模型的发展趋势,详细介绍各阶段的训练方案。
二、持续演进的大规模稀疏场景训练方案
2.1 基于分布式参数服务器的TB级大规模稀疏场景训练方案
2.1.1 Tensorflow在大规模稀疏场景的局限性
随着业务规模和算法能力不断发展,训练样本规模扩展到百亿级,训练参数规模达到千亿级,为了提高模型训练效率和规模,业界通常采用数据并行和模型并行方式来进行分布式训练。由于Tensorflow采用静态Embedding机制来存储稀疏参数,限制了参数规模,对训练的效率和效果并不友好:
◦静态存储局限性:词表空间过小,hash冲突加剧;词表空间过大,浪费内存资源,难以支持大规模参数存储。
◦在线学习不支持:针对在线学习场景,无法淘汰不重要的特征,也无法单独释放该特征Embedding的内存,参数更新时效性成为瓶颈。
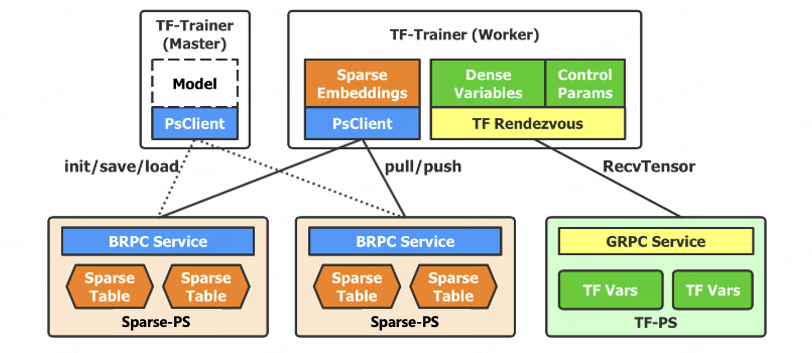
2.1.2 自研高性能参数服务器
为了解决静态Embedding的问题,我们通过自研动态Embedding的高性能参数服务器,将不同的Embedding映射到不同的内存空间,优化存储空间,支持大规模稀疏参数的高效存储,并考虑高并发读写场景,针对稀疏参数设计高性能二级检索方案,优化数据结构,减少并发读写冲突。