本文介绍: LLC可以提高性能,但是会引入安全漏洞,缓存分配的可预测变化可以充当侧信道,提出了一种安全的缓存分配策略,保护缓存免受基于时间的侧信道攻击。SCALE使用随机性实现动态可扩展的分区,添加噪音防止对手观察到分配中的可预测变化,利用差分隐私,并证明SCALE可以提供可量化和信息理论的安全保证。SCALE在具有多编程工作负载的16核平铺芯片多处理器上优于最先进的安全缓存解决方案,并将性能提高39%。静态分区不能满足应用程序 不断变化的需求,性能低于动态分区;
SCALE: Secure and Scalable Cache Partitioning
摘要
LLC可以提高性能,但是会引入安全漏洞,缓存分配的可预测变化可以充当侧信道,提出了一种安全的缓存分配策略,保护缓存免受基于时间的侧信道攻击。SCALE使用随机性实现动态可扩展的分区,添加噪音防止对手观察到分配中的可预测变化,利用差分隐私,并证明SCALE可以提供可量化和信息理论的安全保证。SCALE在具有多编程工作负载的16核平铺芯片多处理器上优于最先进的安全缓存解决方案,并将性能提高39%。
介绍
静态分区不能满足应用程序 不断变化的需求,性能低于动态分区;
动态分区方案包括:确定分区分配策略,以最大化聚合指标;维护分区的强制机制。
之前的工作集中于执行机制,不能满足理想执行机制的要求:支持细粒度分区、可扩展性、位置感知分区,以在安全的同时减少片上访问延迟。
动态安全的确定分配具有挑战性,分配需要有关应用程序缓存需求的信息,有两种保护分配的方式:
安全分析表示,SCALE为配置范围的分配变化提供强大可量化的信息理论安全保障,同时为较大的变化提供了较弱的保证和较低的信道带宽。此外,SCALE还支持安全和非安全应用程序的混合,可以抵抗分配策略侧信道攻击,同时保留UCP等非安全分配策略的大部分性能优势。
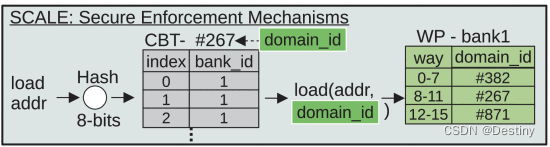
SCALE提出的安全执行机制建立在DELTA执行机制上。DELTA 结合了 bank 和 way 分区,以支持细粒度分区和位置感知数据映射。SCALE的adaptatipns可实现安全实施,减少处理共享数据相关的开销。SCALE的实施机制支持对缓存容量进行安全、细粒度和位置感知的分区。为了证明 SCALEs 分配策略对商用设计的适用性,我们结合一种与英特尔 CAT 安全版本相当的强制机制对其进行了评估。
背景和动机
A . 缓存策略
B. 缓存分配策略侧信道
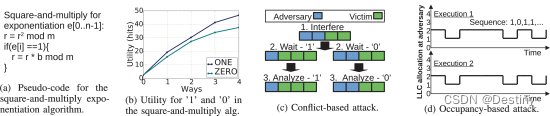
C. 威胁模型
SCALE:安全分区
A. 安全分配策略
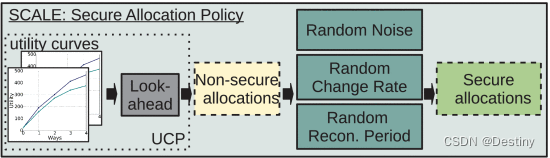




B. 安全执行机制
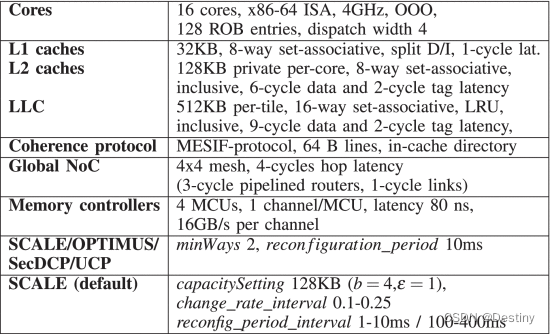
安全评估
效果评估
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




