作为领域驱动战略设计的重要元素,限界上下文对领域驱动架构有着直接的影响。在领域驱动的架构设计过程中,识别限界上下文与上下文映射都是一个重要的过程。限界上下文可以作为逻辑架构与物理架构的参考模型,而上下文映射则非常直观地体现了系统架构的通信模型。
限界上下文的架构范围
这里,需要再一次澄清 Eric Evans 提出的“限界上下文”概念:限界上下文究竟是仅仅针对领域模型的边界划分,还是对整个架构(包括基础设施层以及需要使用的外部资源)垂直方向的划分? 正如前面对 Eric Evans 观点的引用,他在《领域驱动设计》一书中明确地指出:“根据团队的组织、软件系统的各个部分的用法以及物理表现(代码和数据库模式等)来设置模型的边界”,显然,限界上下文不仅仅作用于领域层和应用层,它是架构设计而非仅仅是领域设计的关键因素。
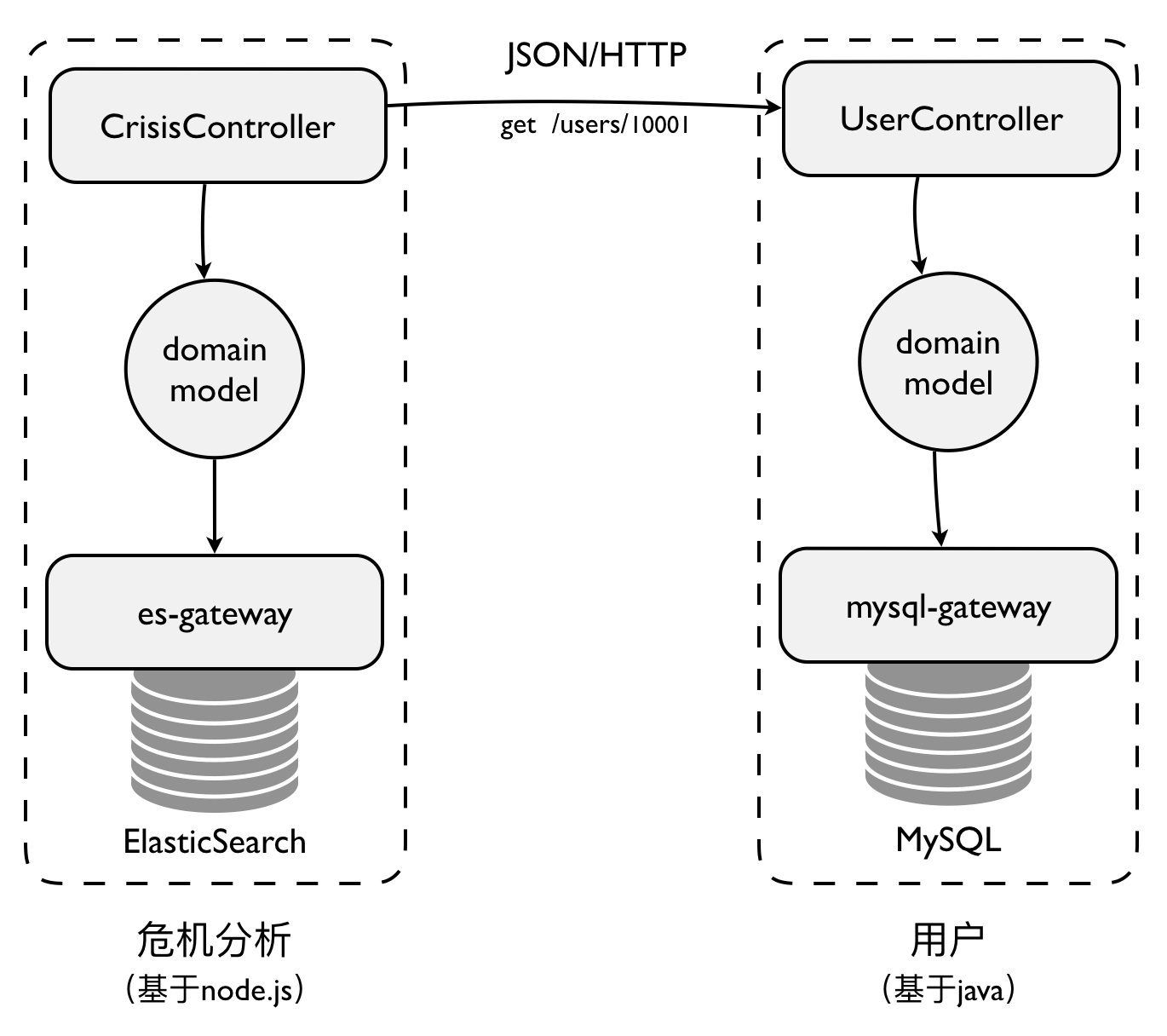
限界上下文体现的是一个垂直的架构边界,主要针对后端架构层次的垂直切分。例如,订单上下文的内部就包含了应用层、领域层和基础设施层,每一层的模块都是面向业务进行划分,甚至可能是一一对应的。
对于基础设施层需要访问的外部资源,以及为了访问它需要重用的框架或平台,与技术决策和选型息息相关,仍然属于架构设计的考量范围,但它们不属于限界上下文的代码模型。例如,订单上下文需要访问数据库和消息队列。在技术决策上,我们需要确定是选择 NoSQL 数据库还是关系数据库,消息队列是采用 Pull 模式还是 Push 模式。在技术选型上,我们需要确定具体是哪一种数据库和消息队列中间件,同时还需要确定访问它们的框架。对资源的规划与设计也属于限界上下文的设计范围,例如,如何设计数据表、如何规划消息队列的主题。在进行这一系列的技术选型和决策时,依据的其实是该限界上下文的业务场景与质量属性,这些架构活动自然就属于该限界上下文的范畴。我们还需要决定框架的版本,这些框架并不属于系统的代码库,但需要考虑它们与限界上下文代码模型的集成、构建与部署。
限界上下文的通信边界
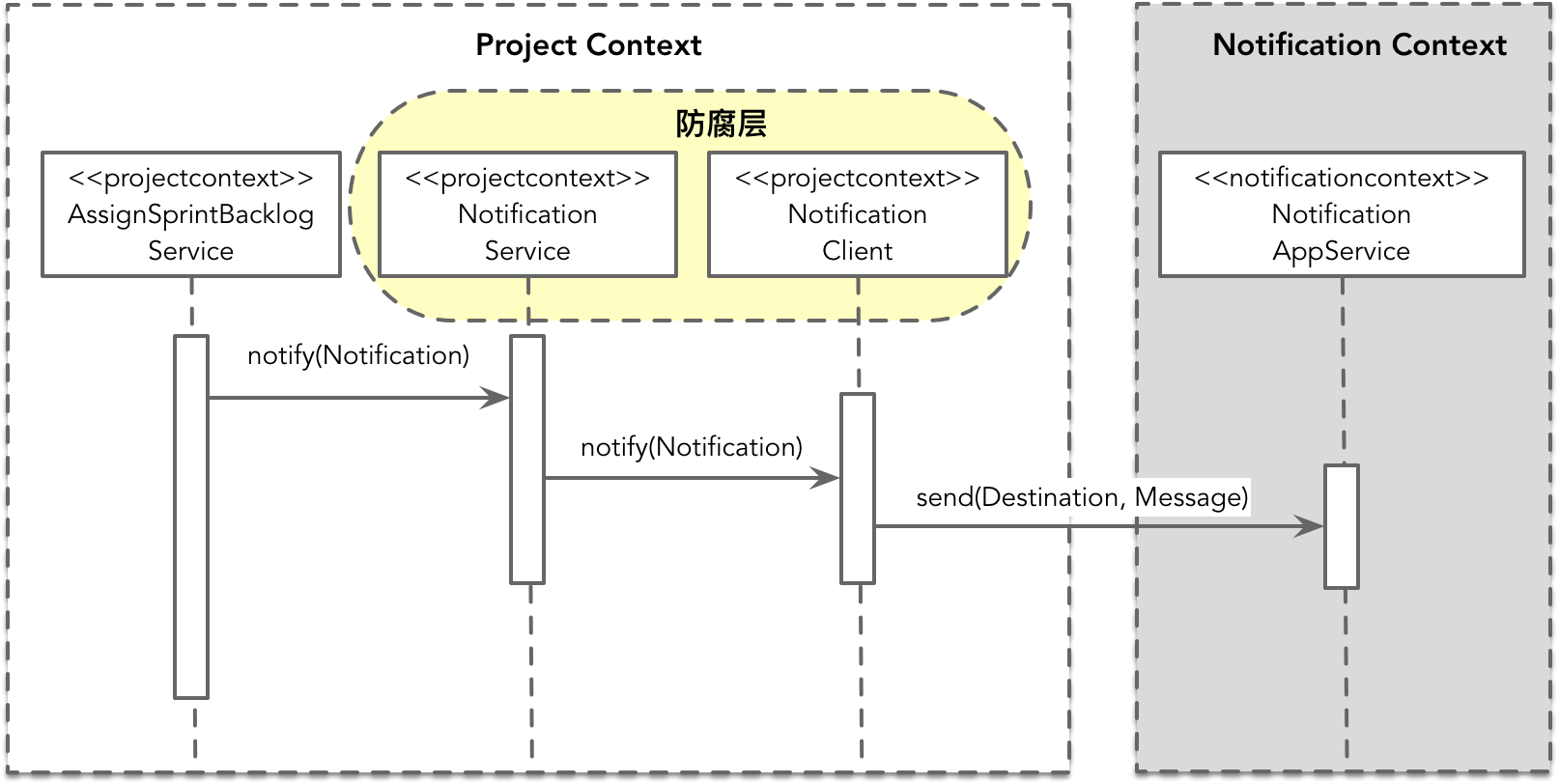
我们对整个业务系统按照限界上下文进行了划分。划分时,限界上下文之间是否为进程边界隔离,直接影响架构设计。此为限界上下文的通信边界,以进程为单位分为进程内与进程间两种边界。之所以这么分类,是因为进程内与进程间在如下方面存在迥然不同的处理方式:
除此之外,通信边界的不同还影响了系统对各个组件(服务)的重用方式与共享方式。