文章目录
大家好,我是景天,今天我们继续探讨DRF,Django的web框架Django Rest_Framework(二)
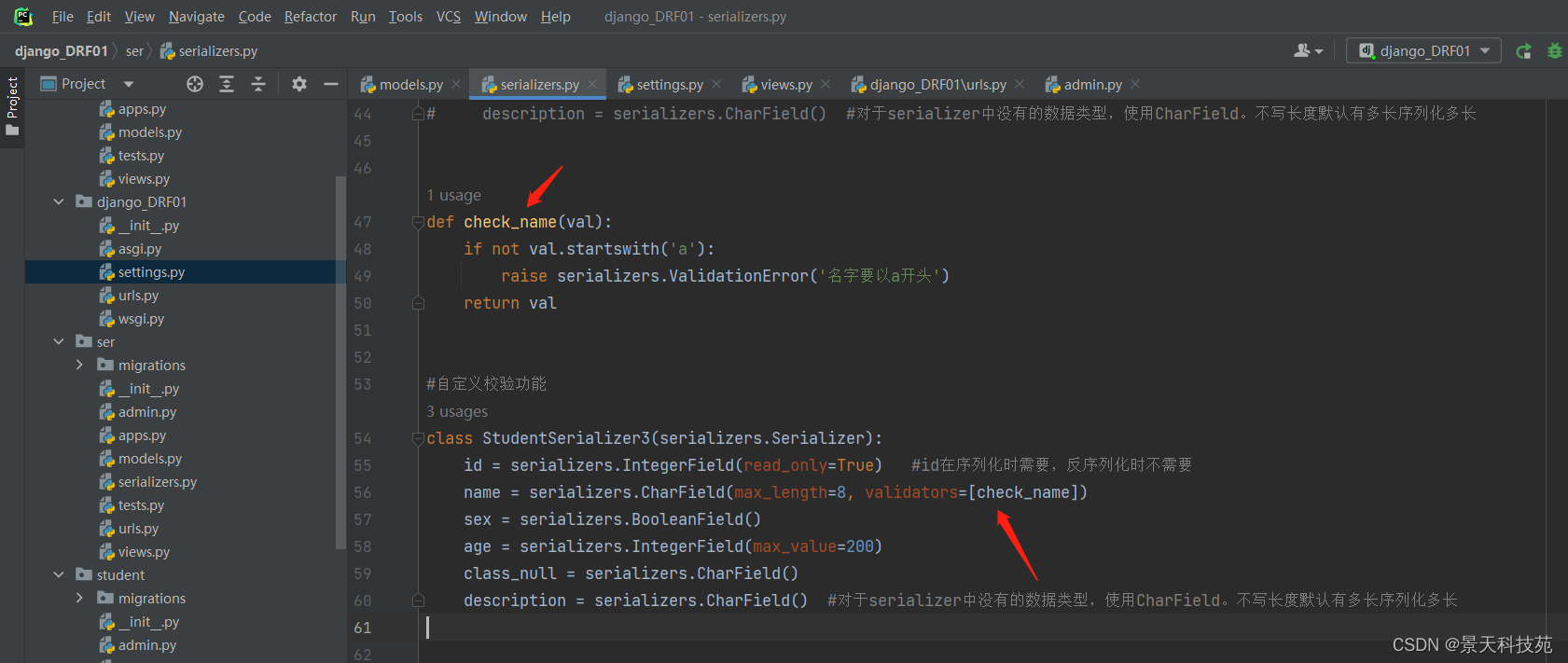
1.自定义校验功能
(1)validators
在字段中添加validators选项参数,也可以补充验证行为,该参数的值是个函数,并且用中括号包裹
需要先在序列化器类外定义个函数,用来设置校验规则
比如我们想实现校验用户提交的名字以a开头
首先定义一个函数check_name,传个参数用于校验,在序列化器的哪个字段加上validators 引用该函数,就会把该字段传给函数进行校验
serialisers.ValidationError用来自定义报错信息
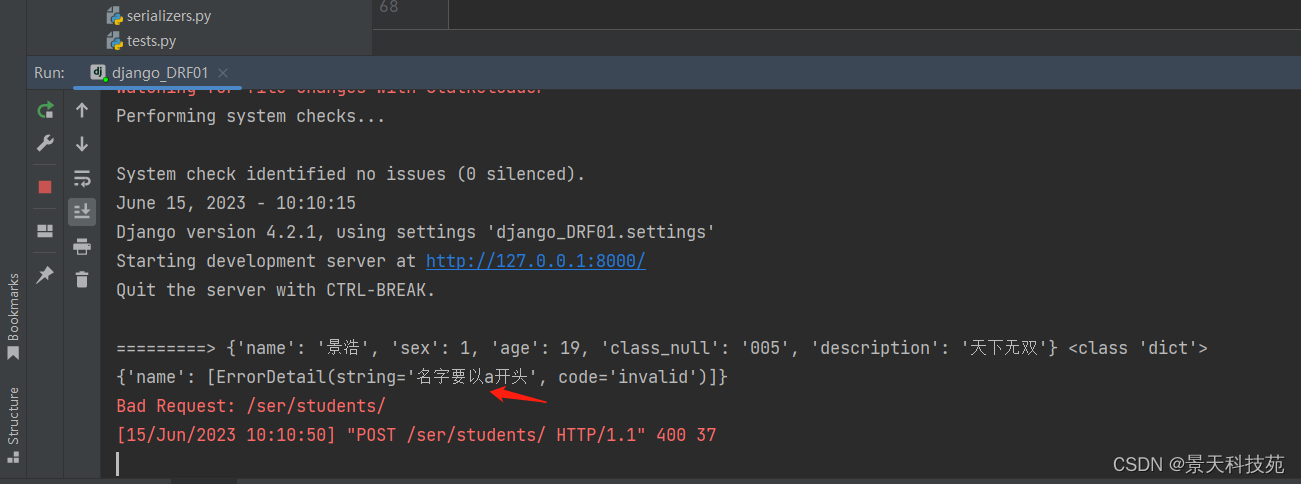
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
当验证失败时,可以直接通过声明 raise_exception=True 让django直接跑出异常,那么验证出错之后,直接就再这里报错,程序中断了就
在序列器里面通过validators参数调用函数,用中括号包裹函数,函数只需要写函数名
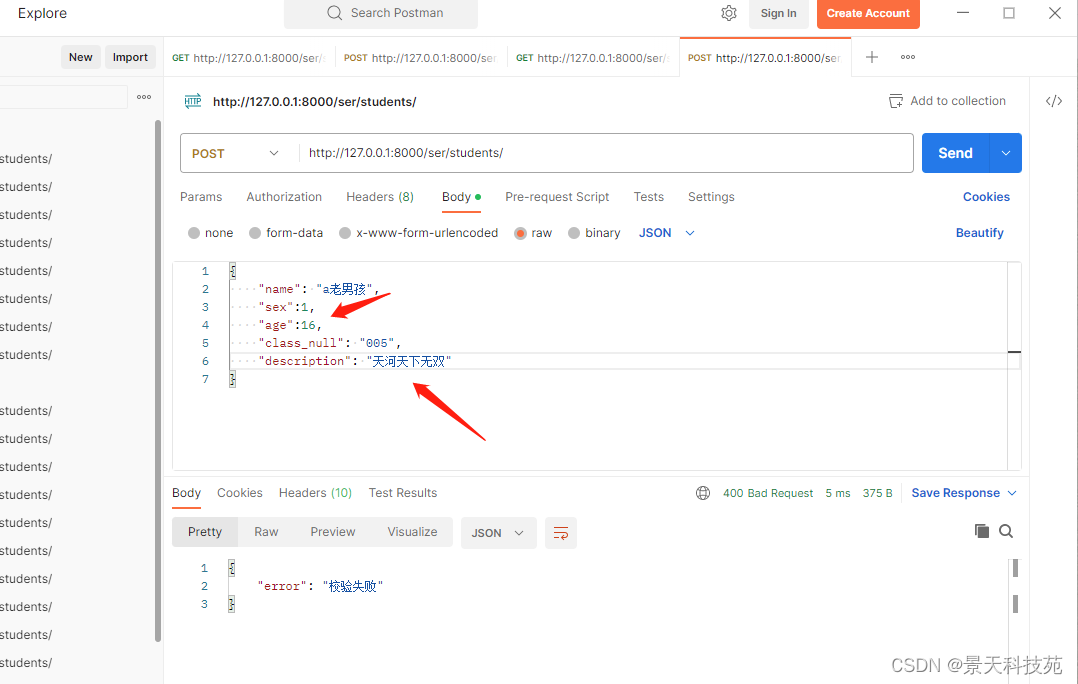
postman进行post请求

校验失败,符合要求
校验规则执行顺序:
对字段类型校验->validators列表中的校验规则从前往后依次验证->从后往前依次验证min_length,max_value等其他规则->校验器内部单字段校验规则(局部钩子校验)->校验器内部多字段联合校验规则(全局钩子)
(2)局部钩子:单字段校验
序列化器中可以自定义单个字段的验证方法 def validate_<字段名>(用户提交的字段数据):
方法名必须是 validate_字段名
对<field_name>字段进行验证
校验完成一定要将数据返回,不然validated_data获得该字段的值为空
序列化器类中定义
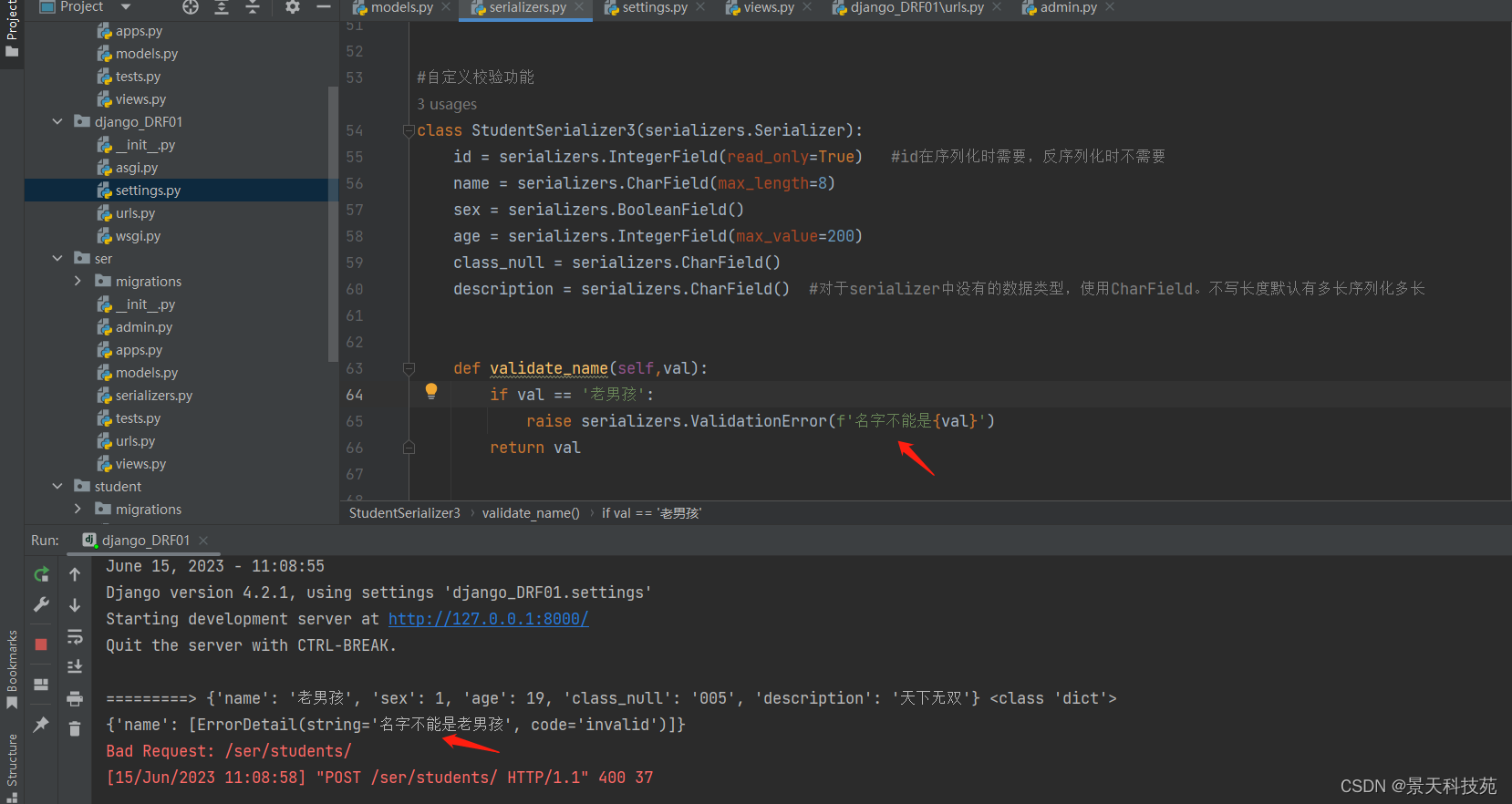
def validate_name(self,val):
if val == ‘老男孩’:
raise serializers.ValidationError(f’名字不能是{val}’)
return val
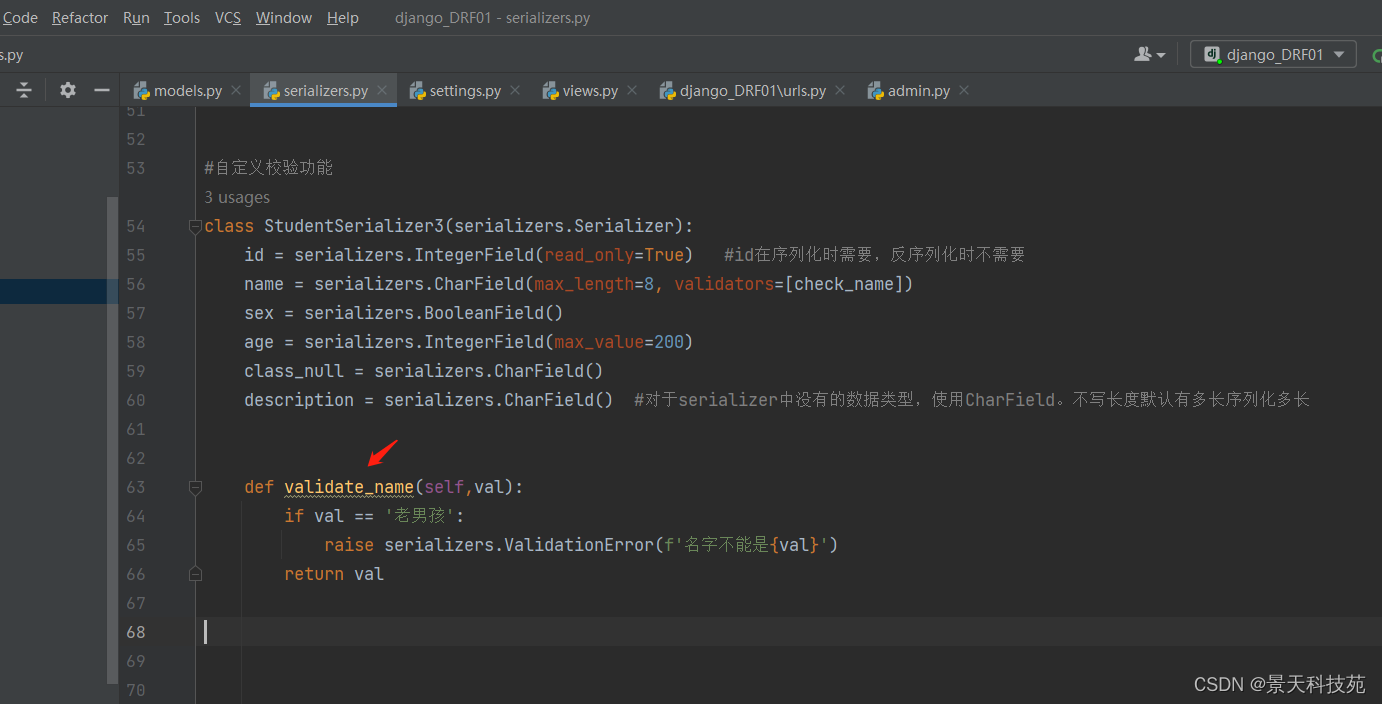
提交post请求

由报错信息可知,validators校验优先级高于 局部钩子
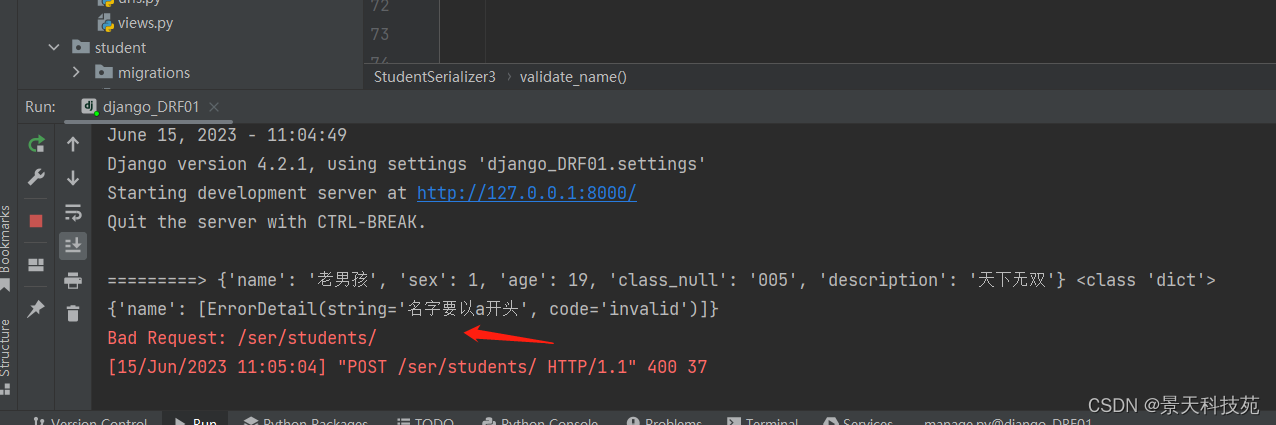
把validators去掉,再请求
可见局部钩子校验生效
(3)全局钩子:多字段校验
validate
在序列化器中需要同时对多个字段进行比较验证时,可以定义validate方法来验证
#方法名时固定的,用于验证多个字段,参数就是实例化序列化器类时的data参数
对多个字段全部校验,如果全部校验都通过,将数据data返回
查看接收到的数据,python3.6以后dict字典默认是有序字典
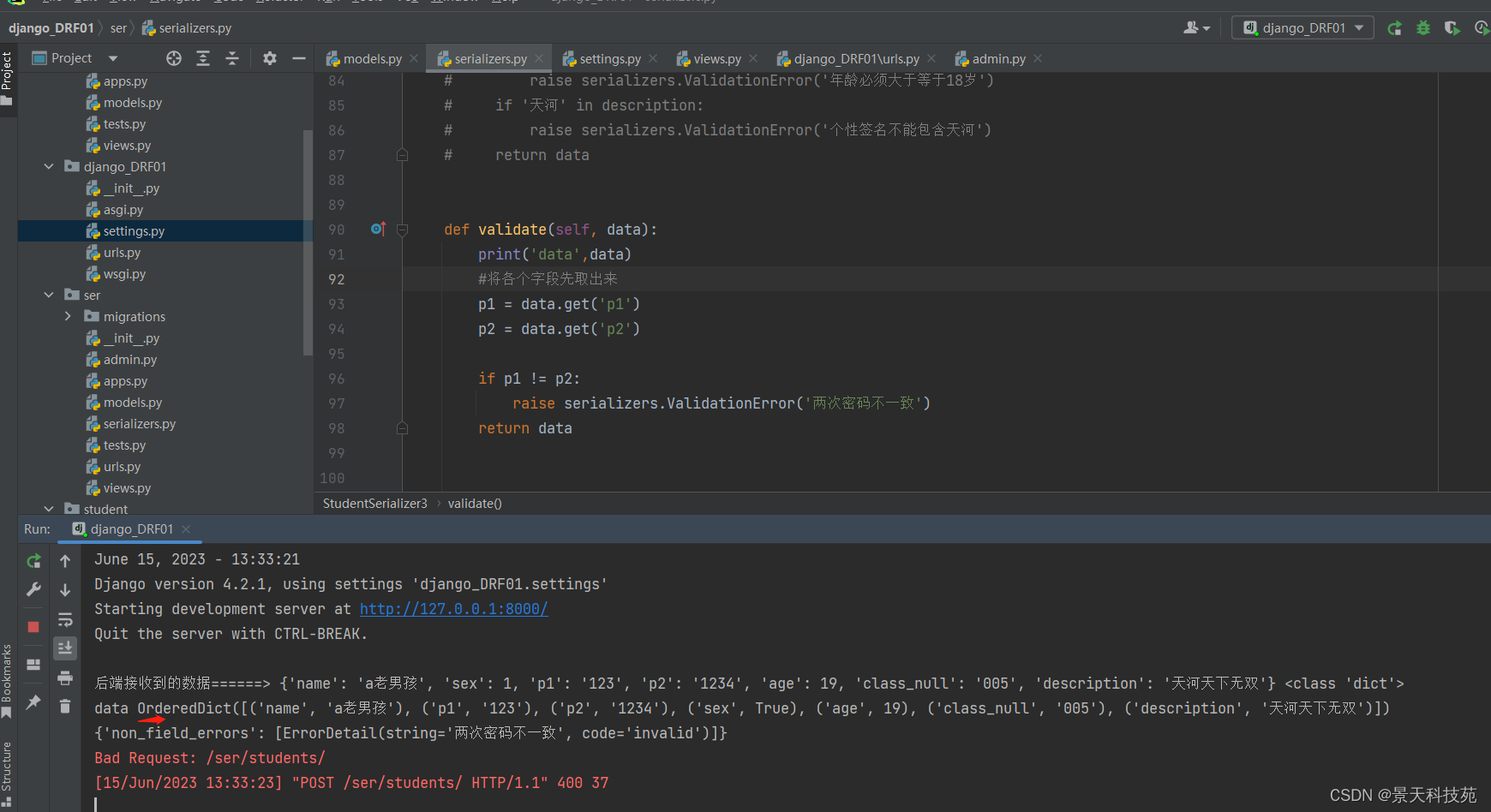
#全局钩子,多字段同时校验
# 方法名时固定的,用于验证多个字段,参数就是实例化序列化器类时的data参数
# 先通过data将数据取出来,data就是request.data用户提交上来的字典类型数据 OrderedDict
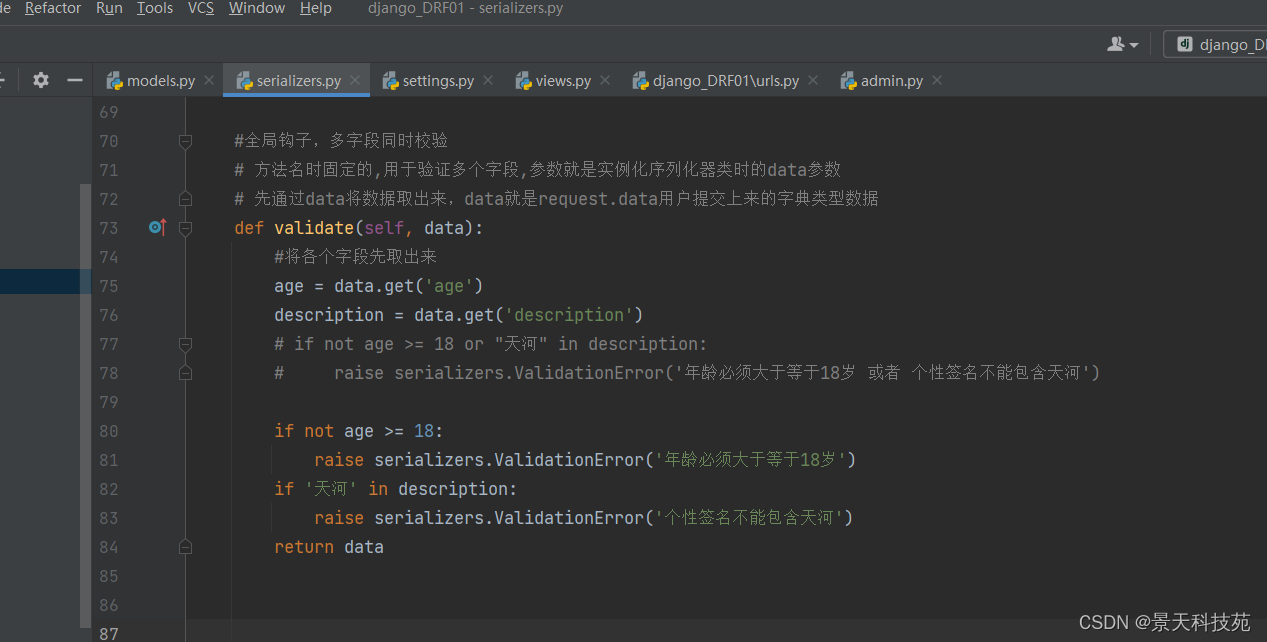
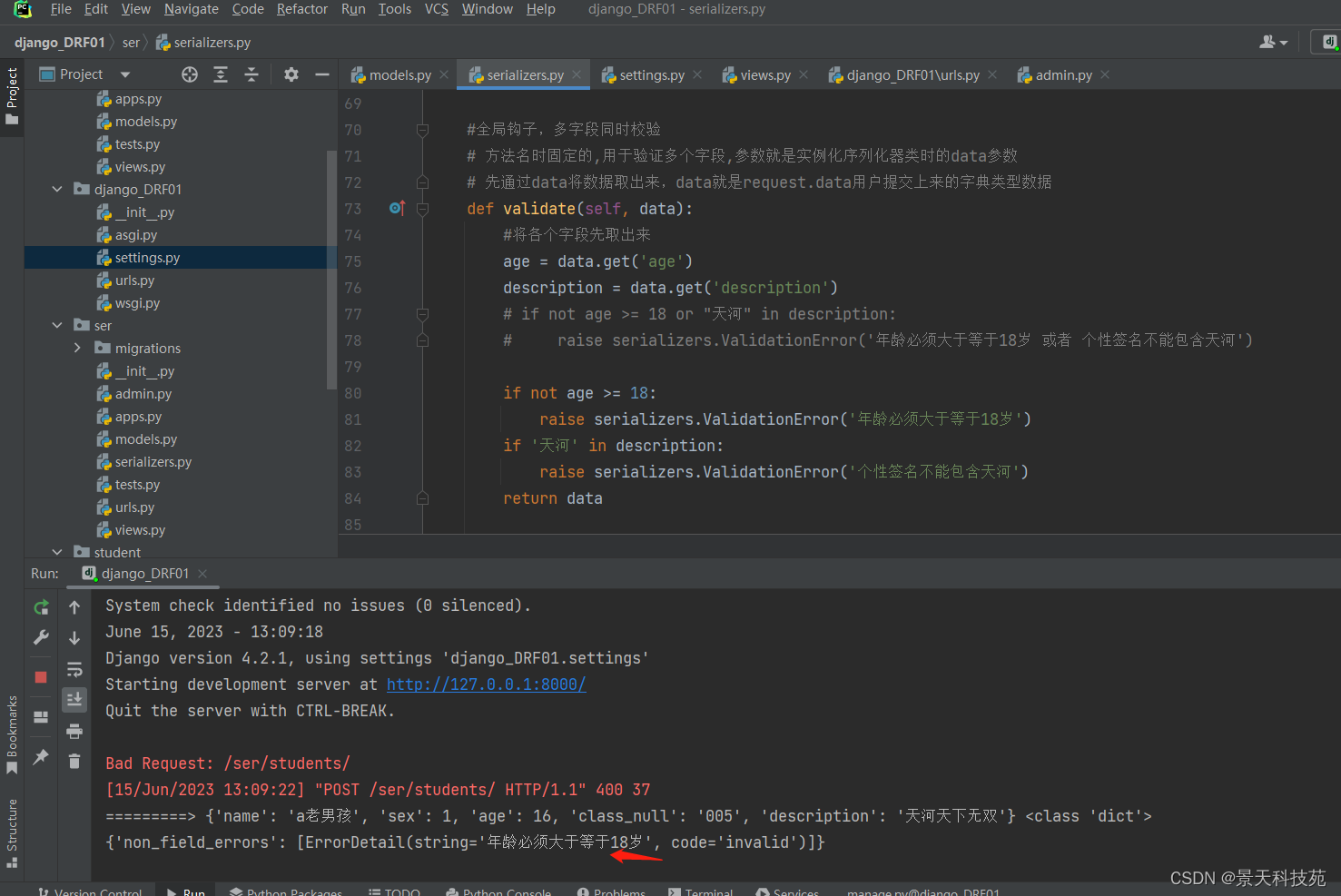
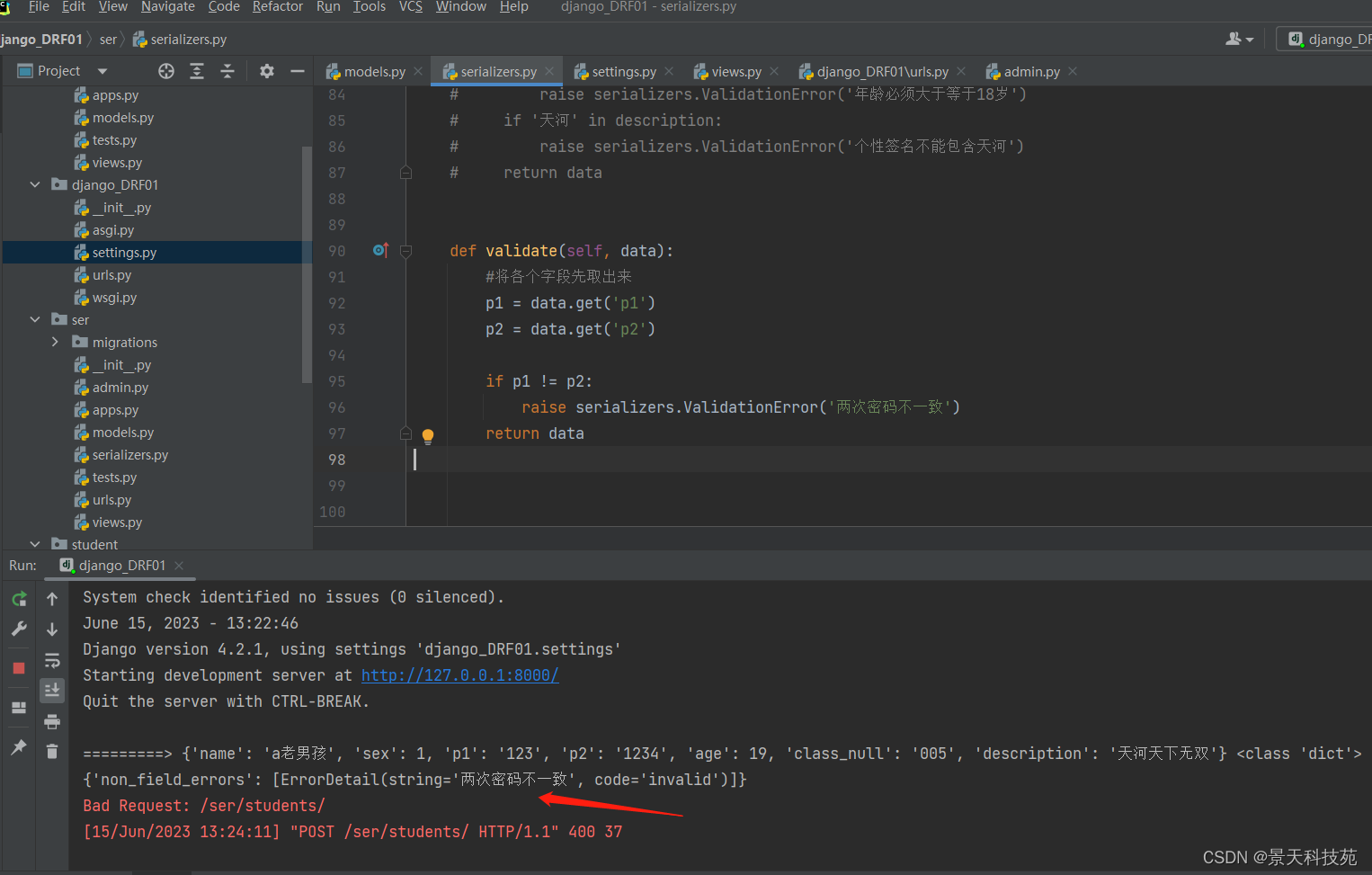
def validate(self, data):
#将各个字段先取出来
age = data.get('age')
description = data.get('description')
# if not age >= 18 or "天河" in description:
# raise serializers.ValidationError('年龄必须大于等于18岁 或者 个性签名不能包含天河')
if not age >= 18:
raise serializers.ValidationError('年龄必须大于等于18岁')
if '天河' in description:
raise serializers.ValidationError('个性签名不能包含天河')
return data
可以单个字段分别判断,也可以放在一个判断条件里面判断
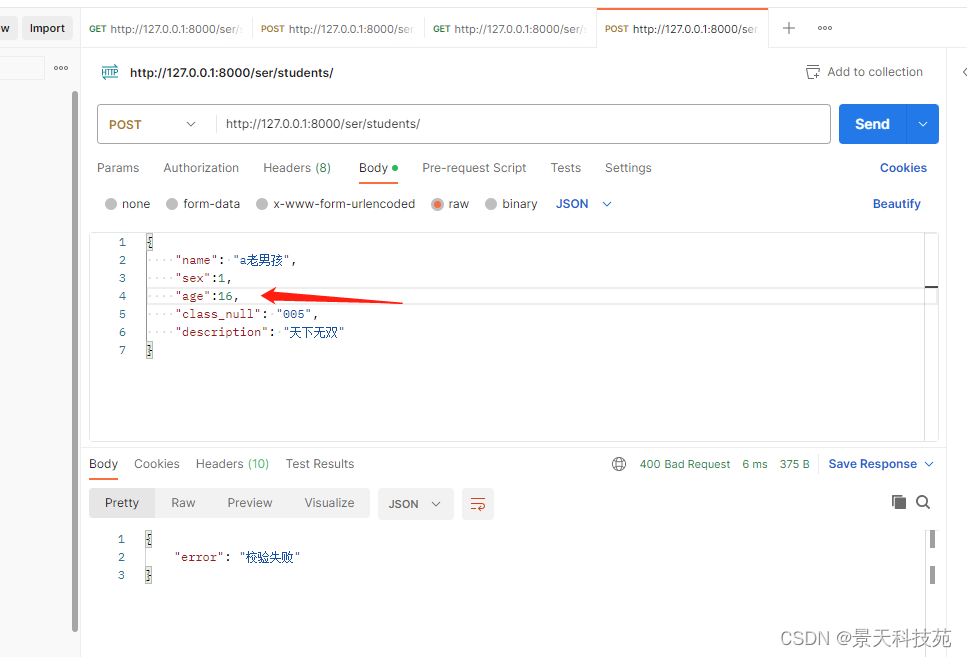
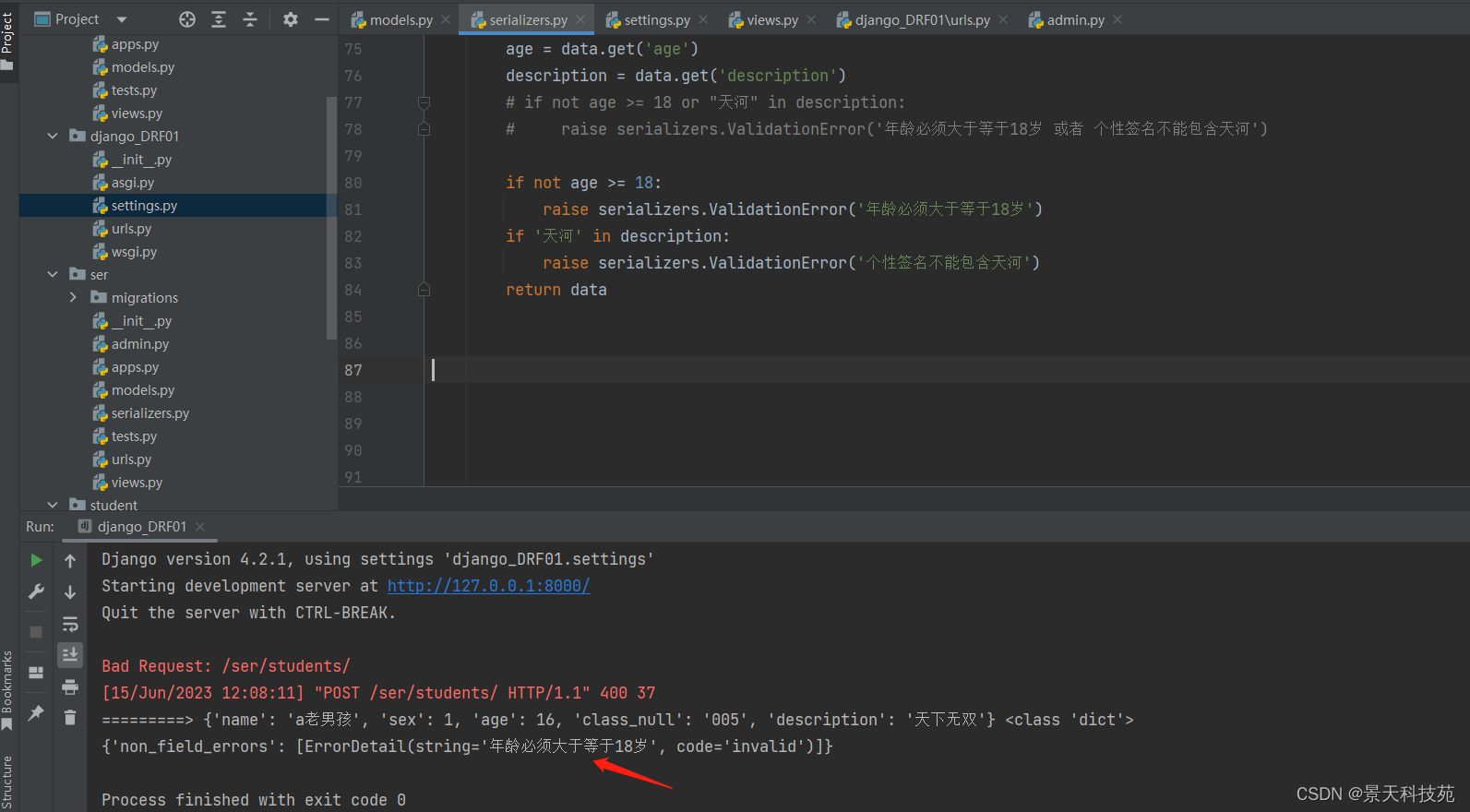
多个字段验证时,有一个字段验证不通过,下面的字段就不再验证,抛出异常
经典实用场景:用户输入的密码和确认密码是否相同校验,前面的参数校验,局部钩子都无法实现,因为都是单字段校验
多字段联合校验validate在这里就能发挥作用
字段反序列化校验和模型类存入数据库的数据都是独立的,虽然名字一样可以用来校验,但它们互相独立,彼此互不影响
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
保存和校验是两码事,校验是为了更好的保存
所以我们在序列化器添加两个字段,分别表示第一次输入密码,第二次输入密码
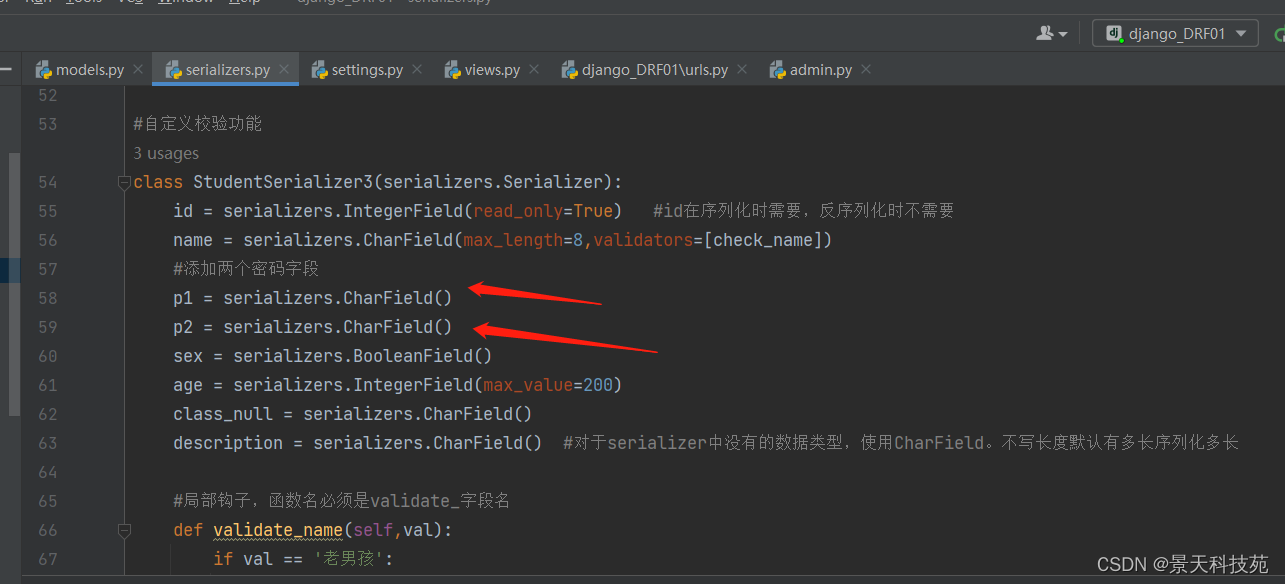
定义校验规则
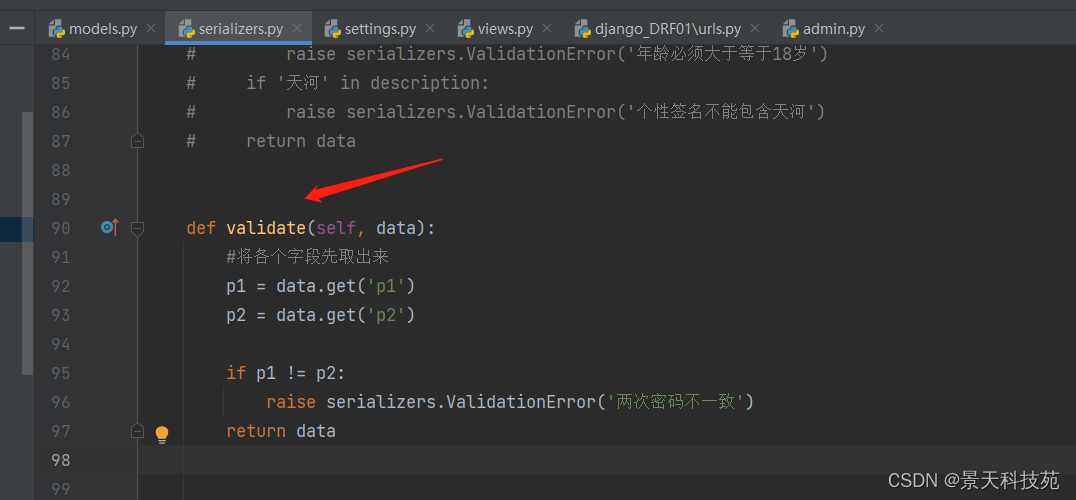
提交请求
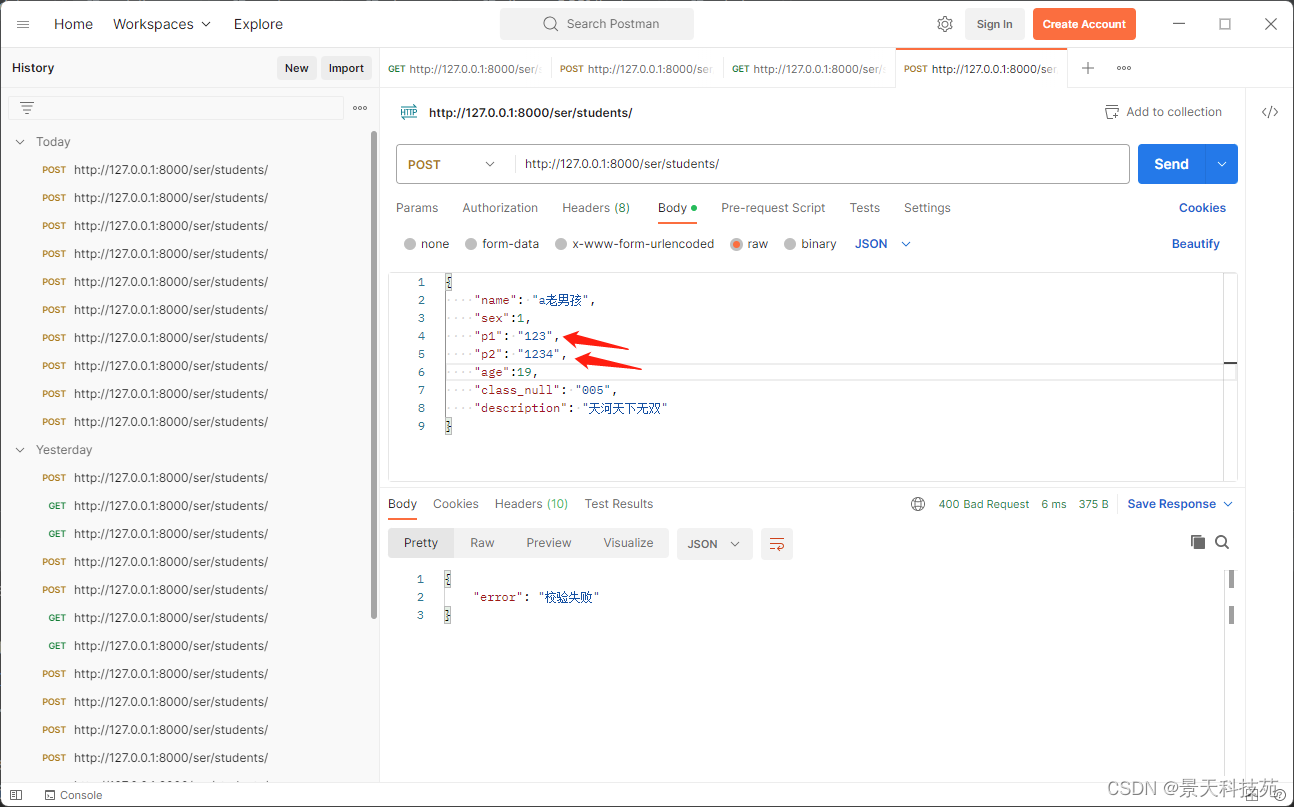
校验结果,检验不成功,会在non_field_errors中显示我们raise出的错误信息
2.raise_exception 参数
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递**raise_exception=True**参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
放在这里面的参数
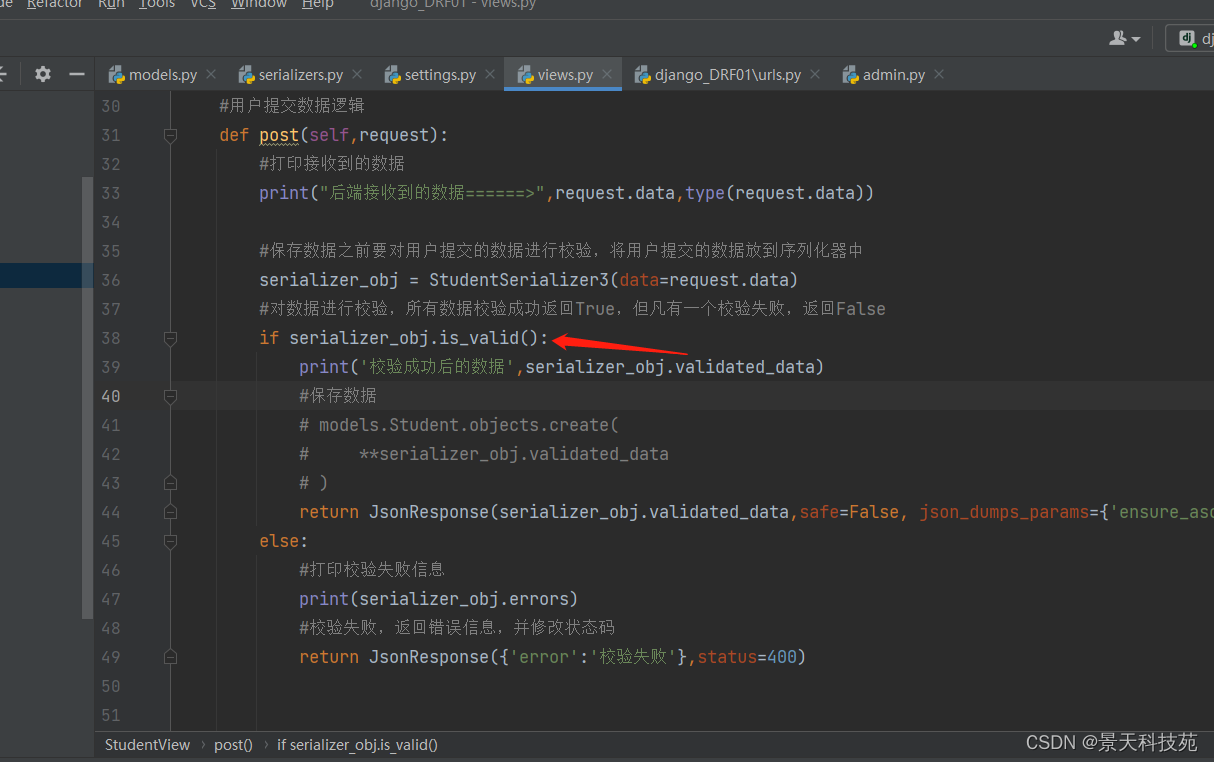
#添加上这个参数后,当验证失败时,可以直接通过声明 raise_exception=True 让django直接跑出异常,那么验证出错之后,直接就再这里报错,程序就中断了,不往下走了
如下,当校验有异常时,程序就不再往下走,打印status都没有执行
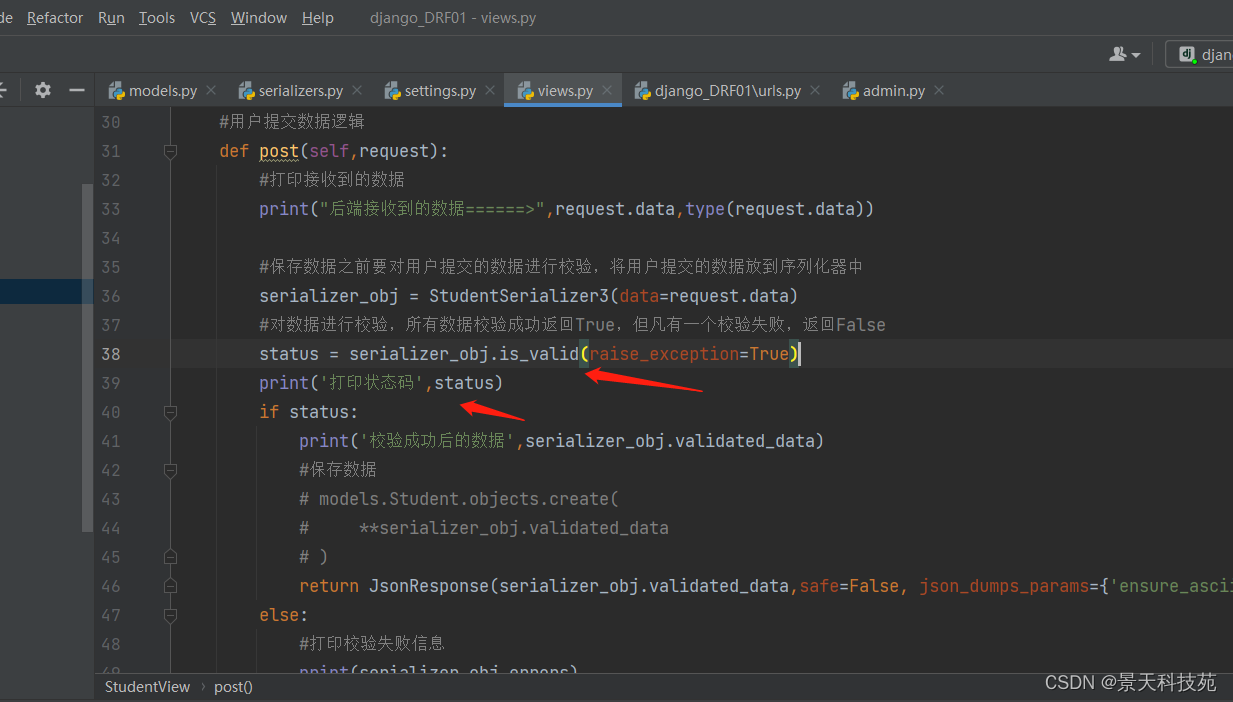
将错误信息响应给前端 non_field_errors 展示我们抛出的报错信息

REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应
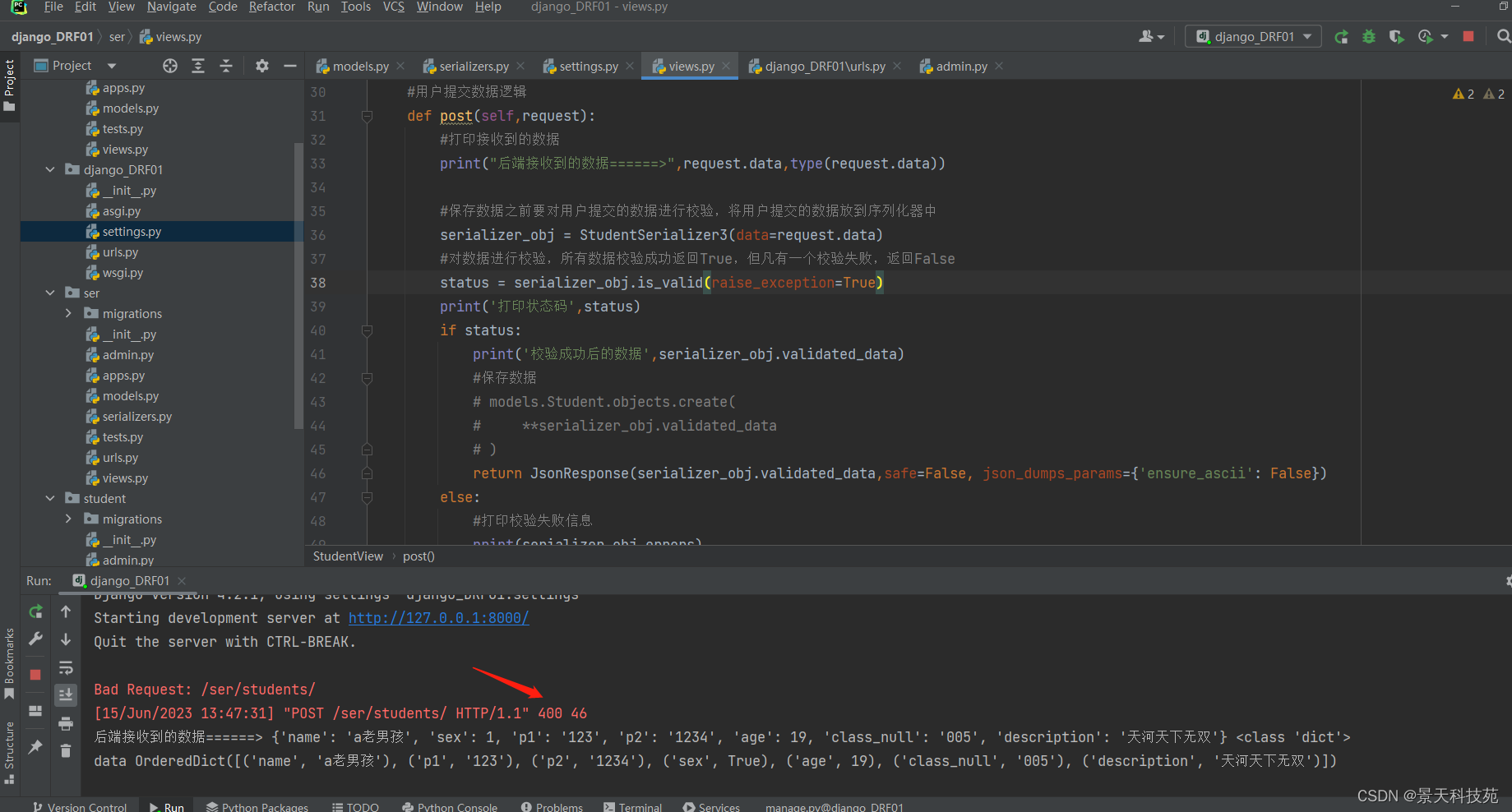
这个raise_exception的作用是,视图函数那里,错误响应信息不用我们自己写了。植物药写响应正常数据就可以了
遇到校验不通过,raise_exception 会直接将错误信息响应给前端,错误状态码也被修改成了400
3.context参数
除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据, 调用序列化器的时候传该参数,传给定义序列化器的时候使用 如
serializer = AccountSerializer(account, context={‘request’: request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
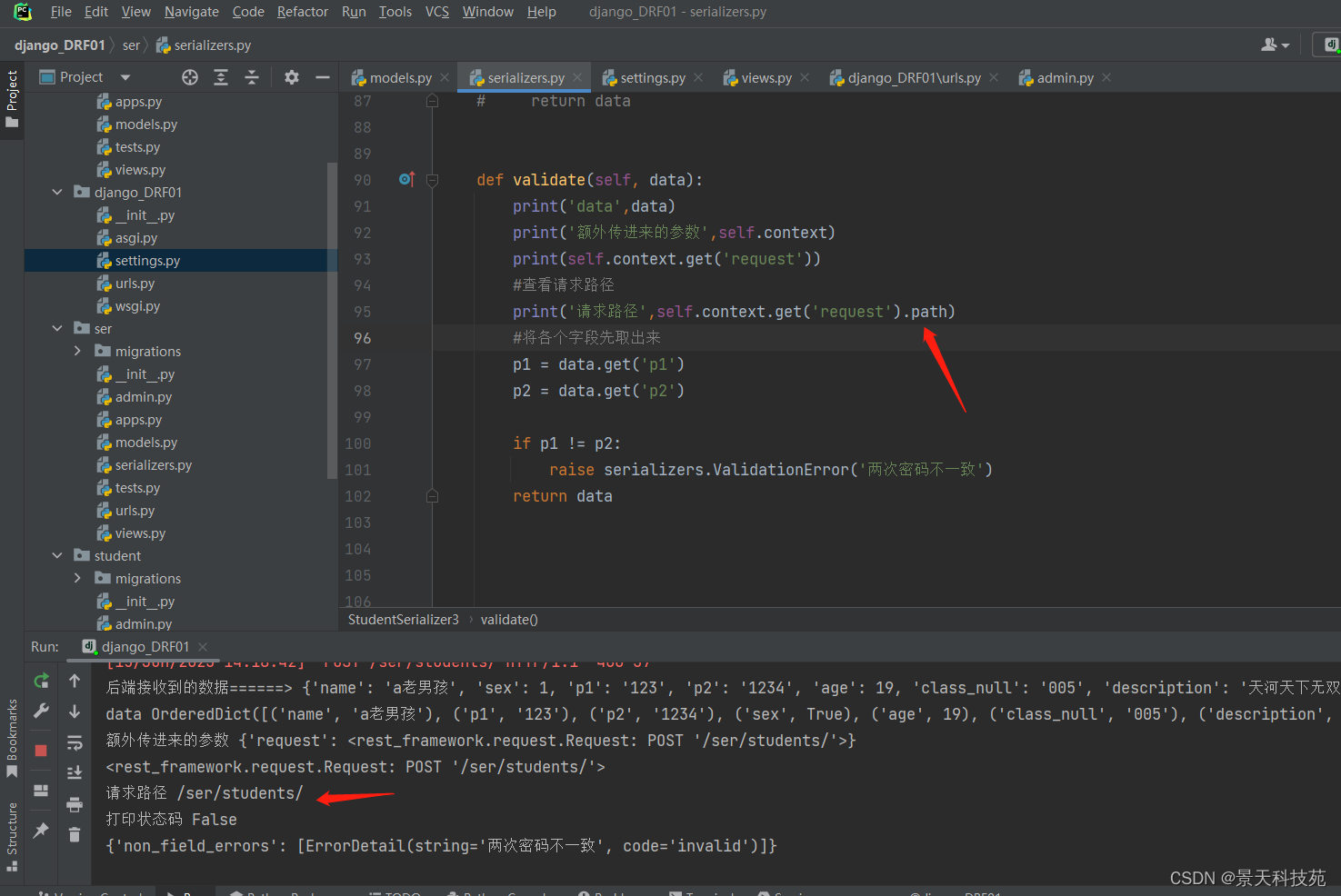
比如,我们想在全局钩子校验时,想获取用户的请求路径。正常情况下我们是没办法的
现在,我们可以在调用序列化器的地方,通过context参数 把request 传进序列化器对象,然后就可以在定义序列化器的时候使用request了
serializer_obj = StudentSerializer3(data=request.data, context={‘requset’: request})
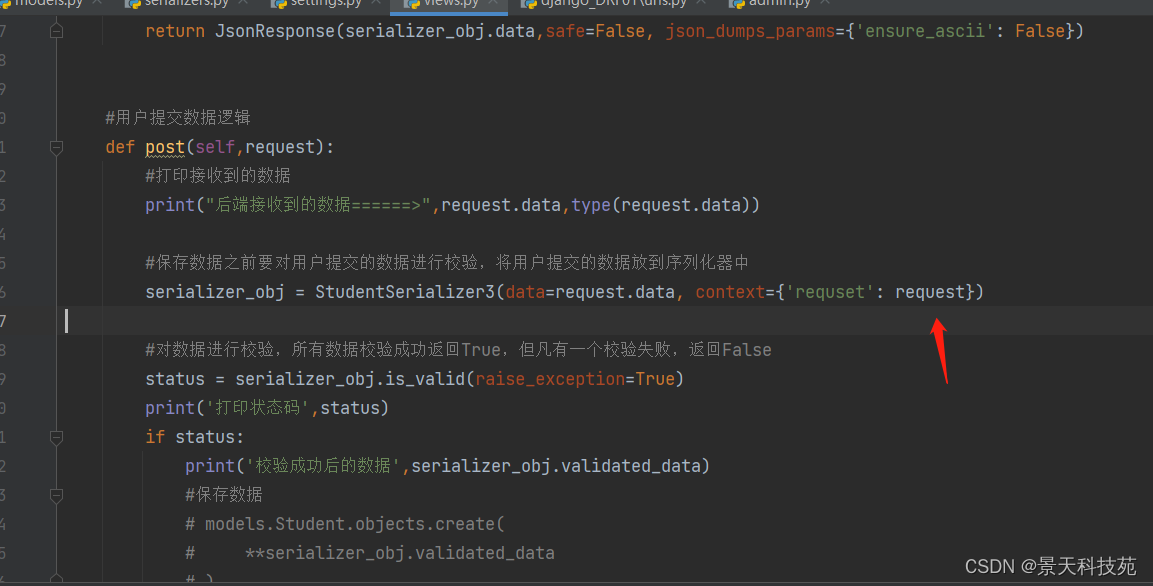
通过context属性获取
print(‘额外传进来的参数’,self.context)
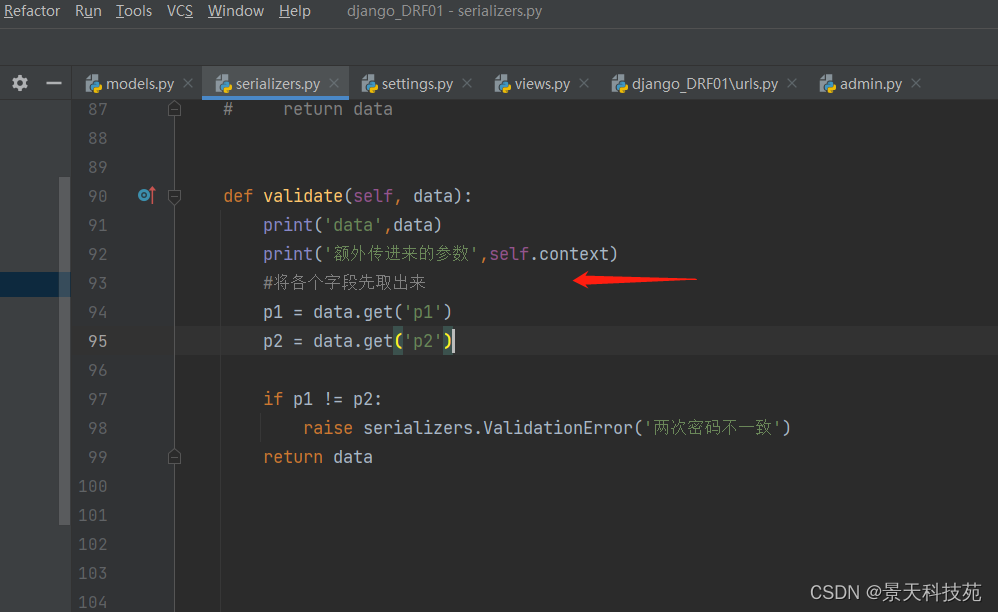
由于我们的视图类继承了rest_framework的APIView,所以此时的request不再是wsgi类的request,而是被rest_framework封装后的request
之前request的方法和属性都还保留着,只是扩展了一些新方法和属性
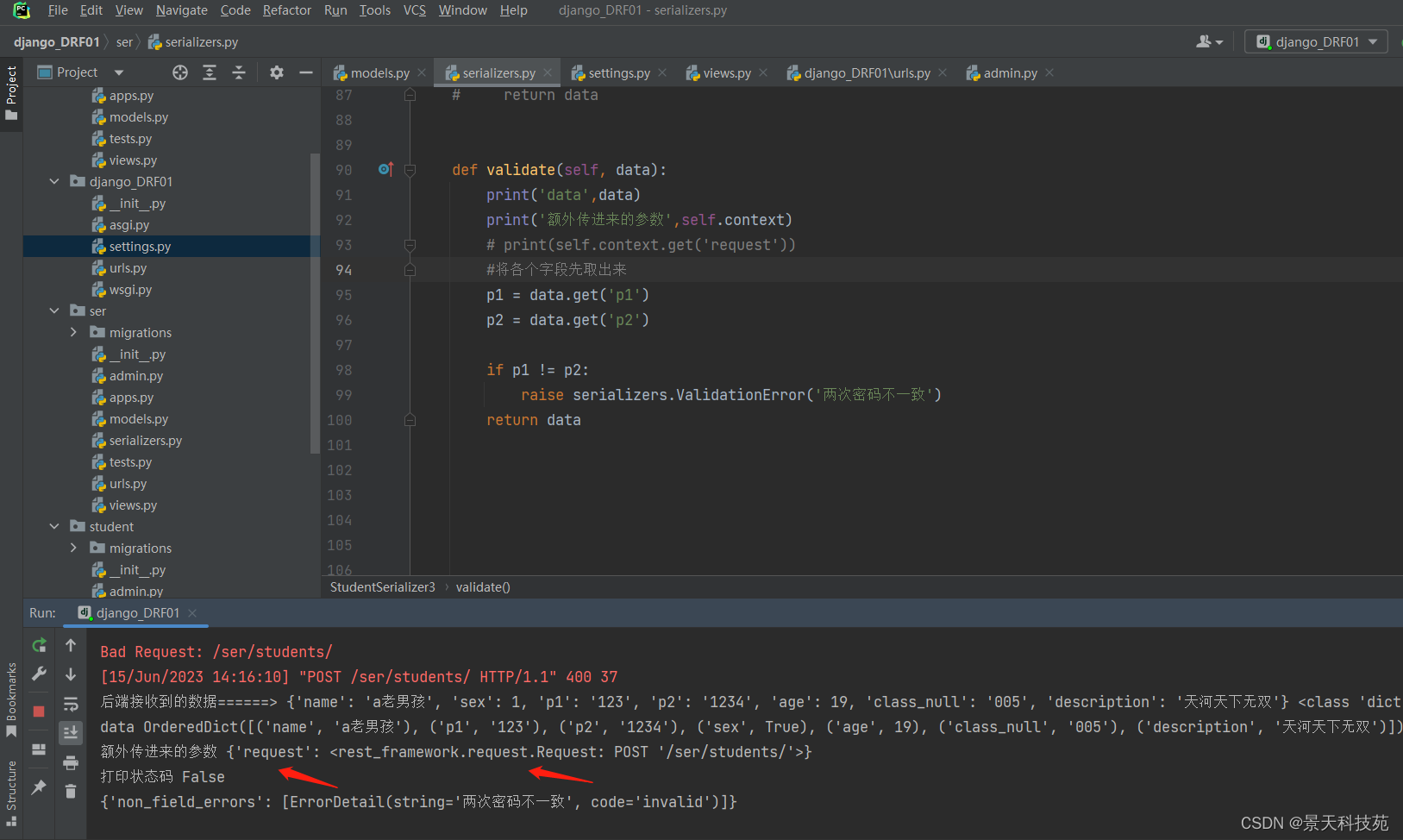
在定义序列化器时,可以以键取值的方式取到request,然后可以使用request渠道相关数据,对其他信息进行校验
self.context.get(‘request’)

查看请求路径
如果要添加其他多个参数,直接逗号,后面接着跟键值对
serializer = AccountSerializer(account, context={‘request’: request, ‘xxx’:xx})
自定义校验函数,通过validators引用函数的,就不能通过这个context来获取额外参数,因为这个函数定义在序列化器外面。无法通过self调用context参数
4.反序列化校验后保存,新增和更新数据
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象.
(1)保存数据方式1
#保存数据,方式1 直接调用模型类对象进行保存
models.Student.objects.create(
**serializer_obj.validated_data
)
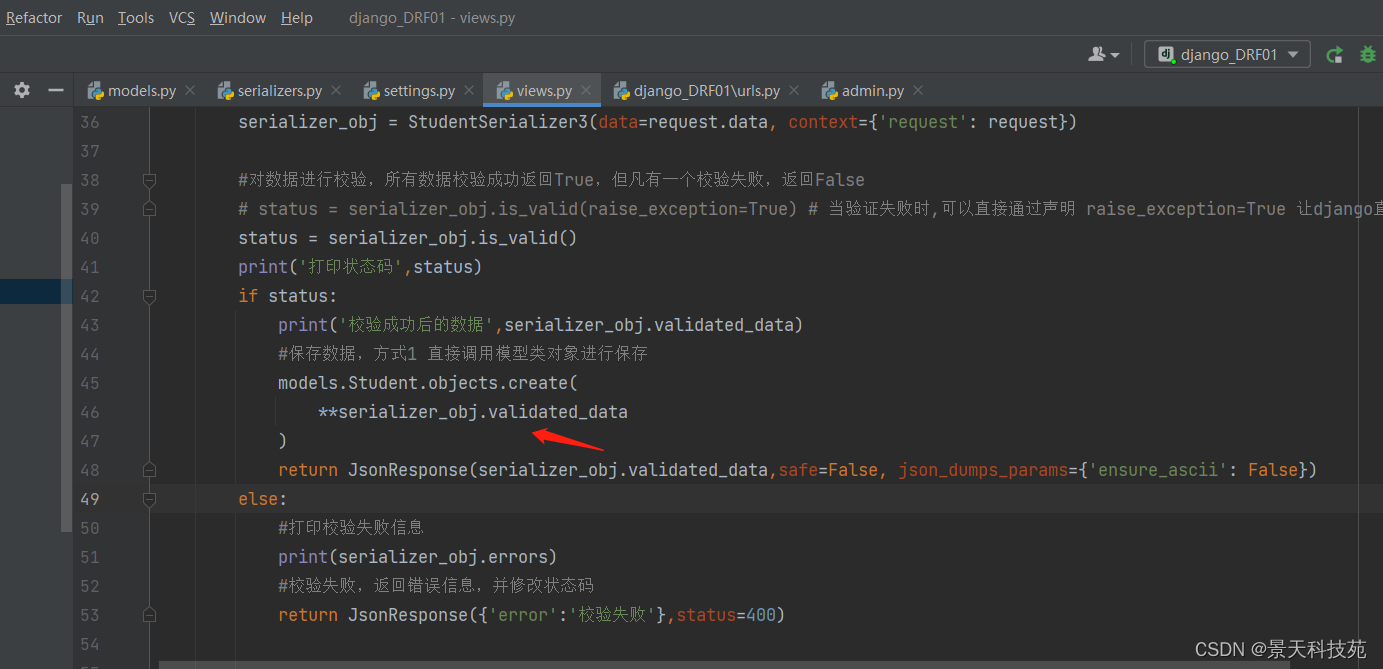
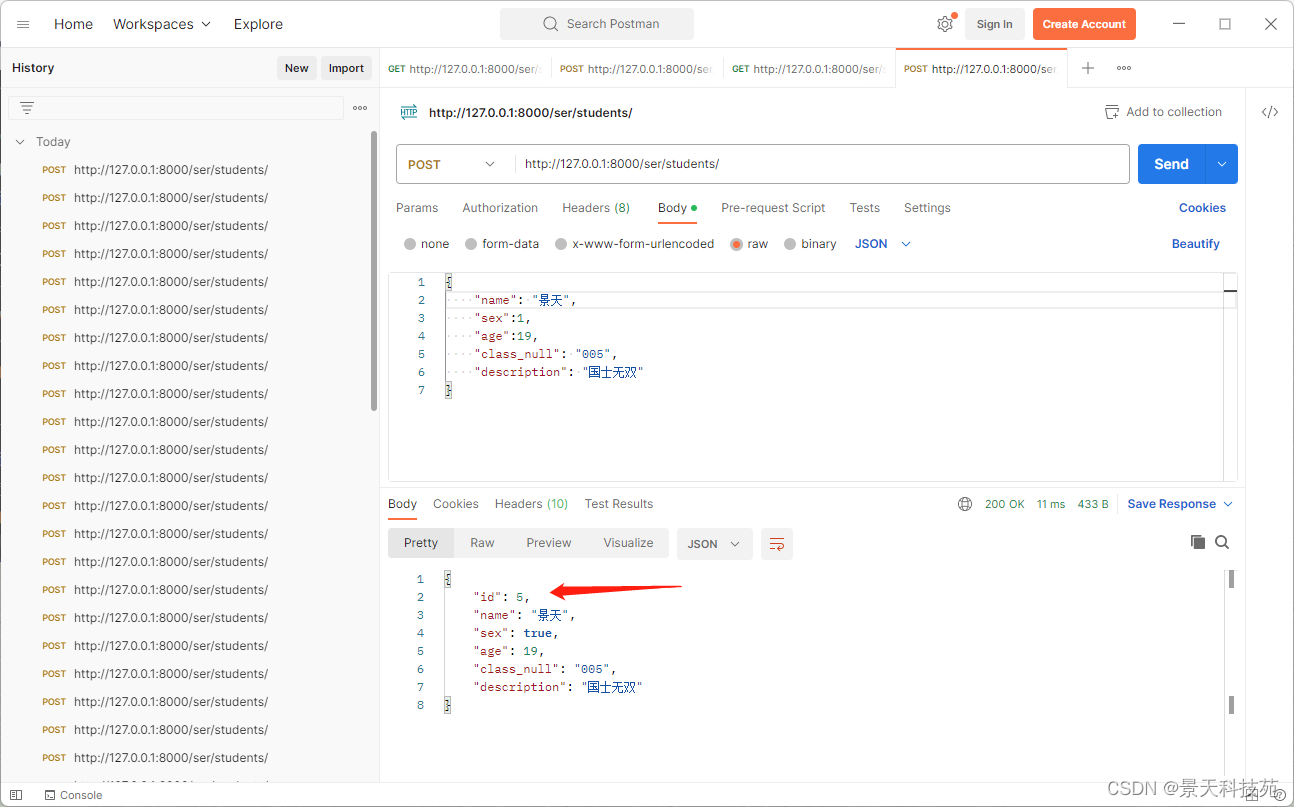
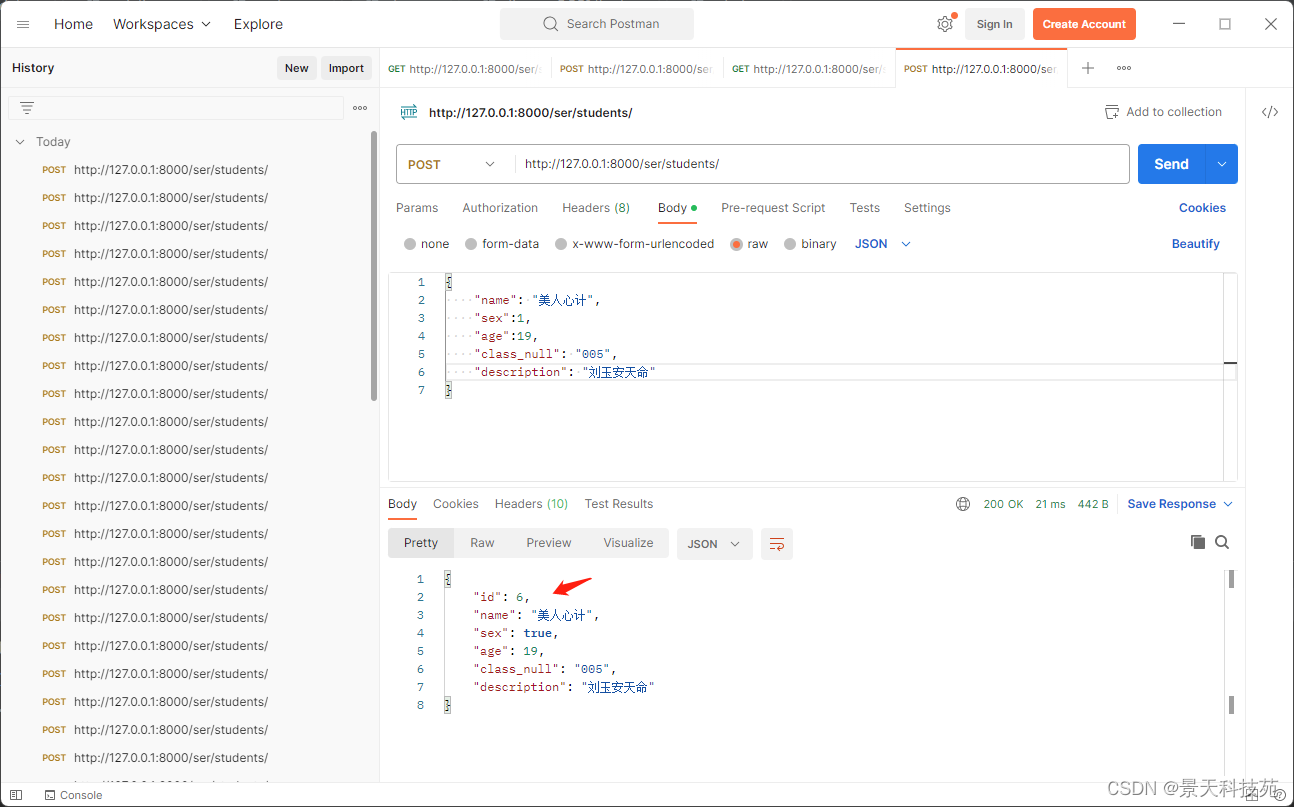
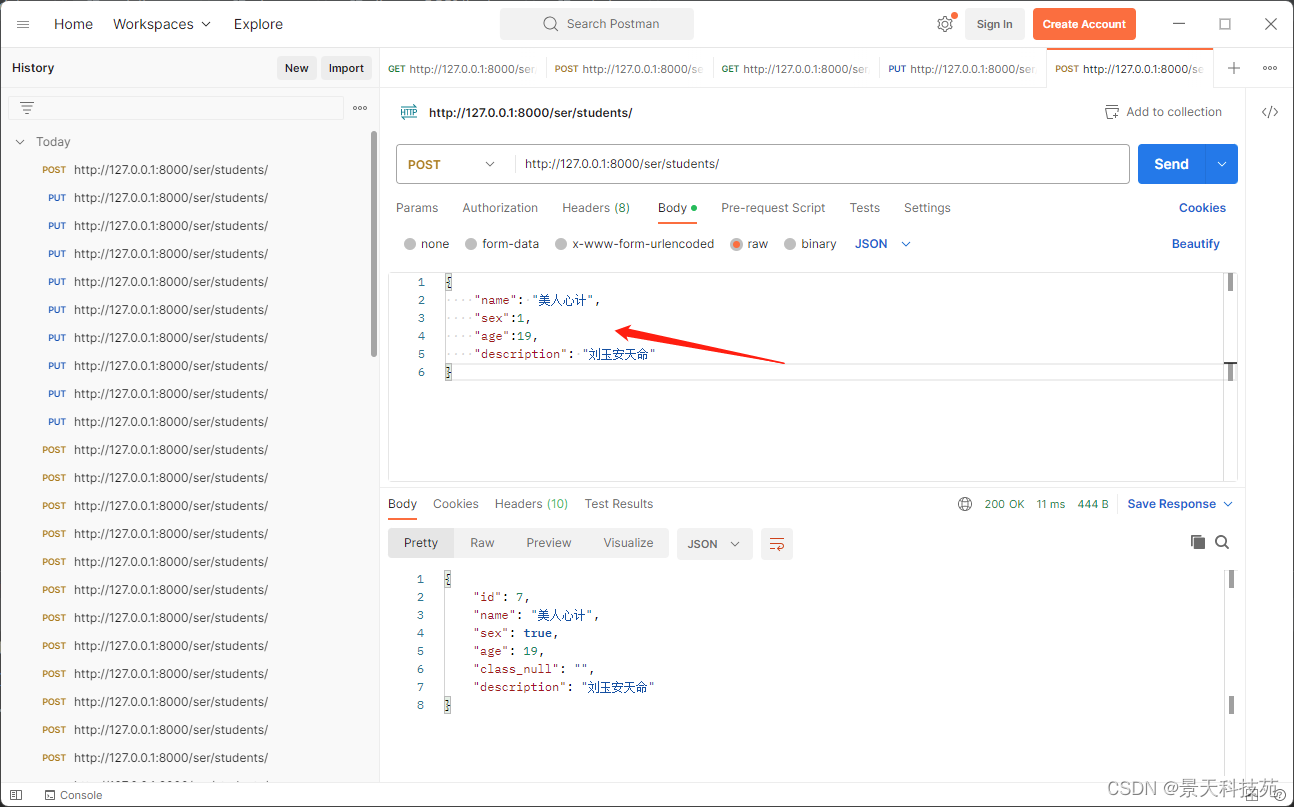
提交post请求
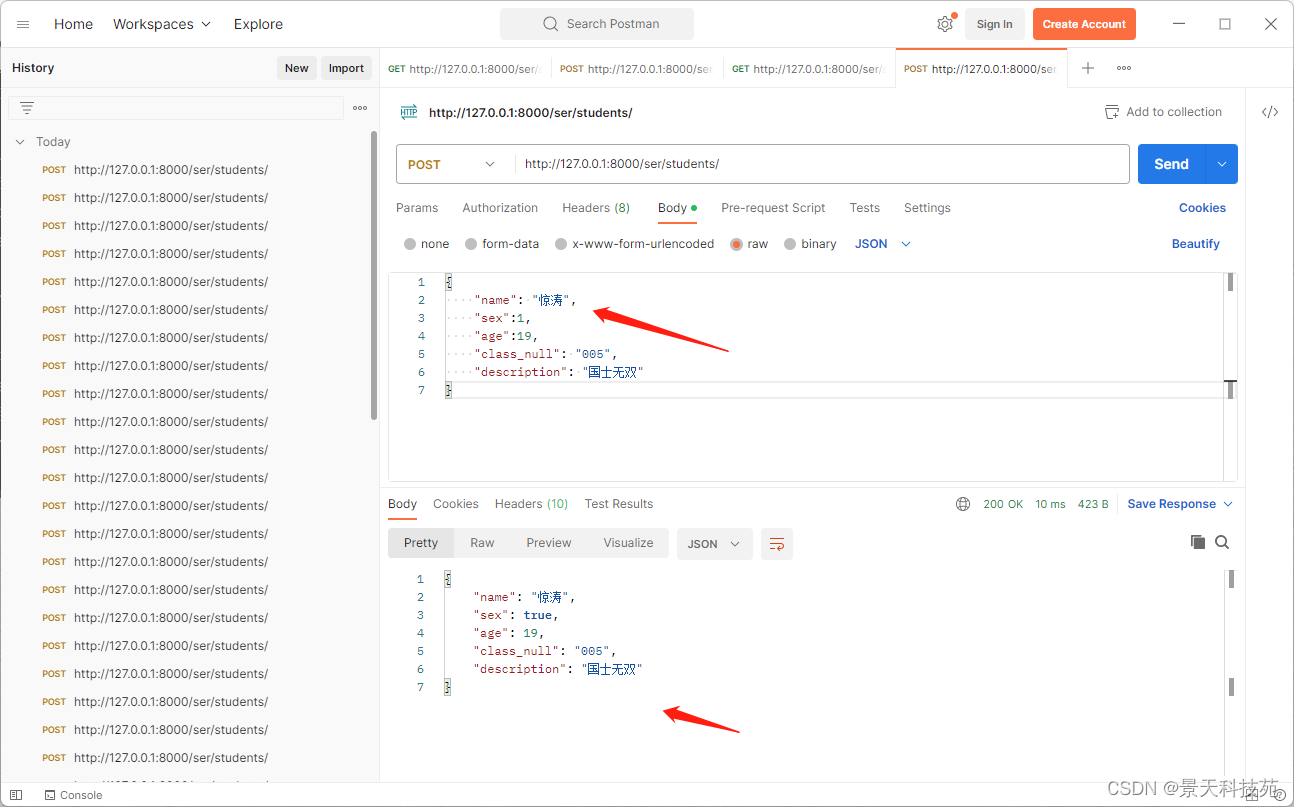
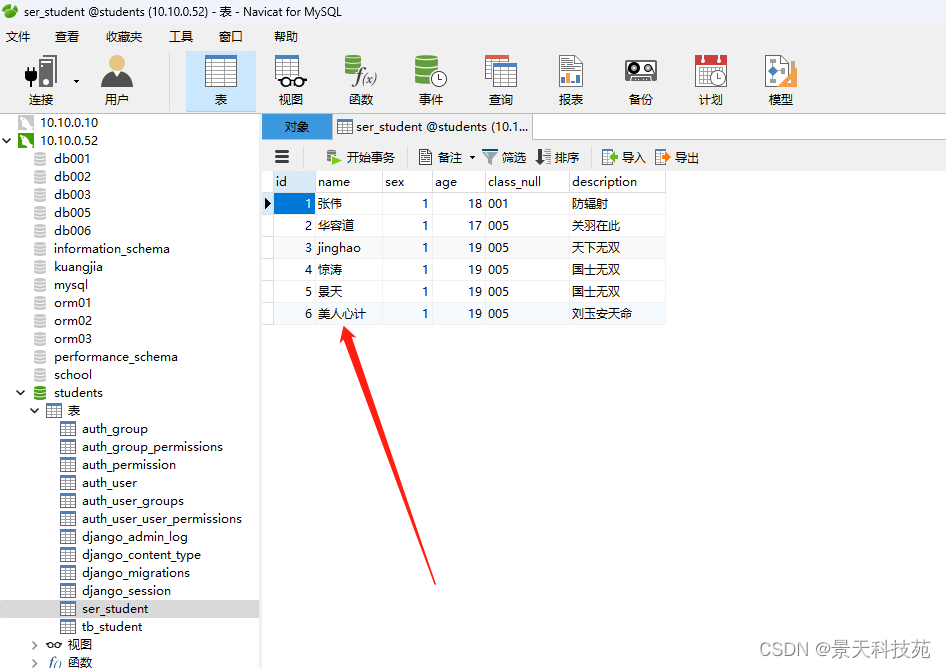
查看数据库,保存成功
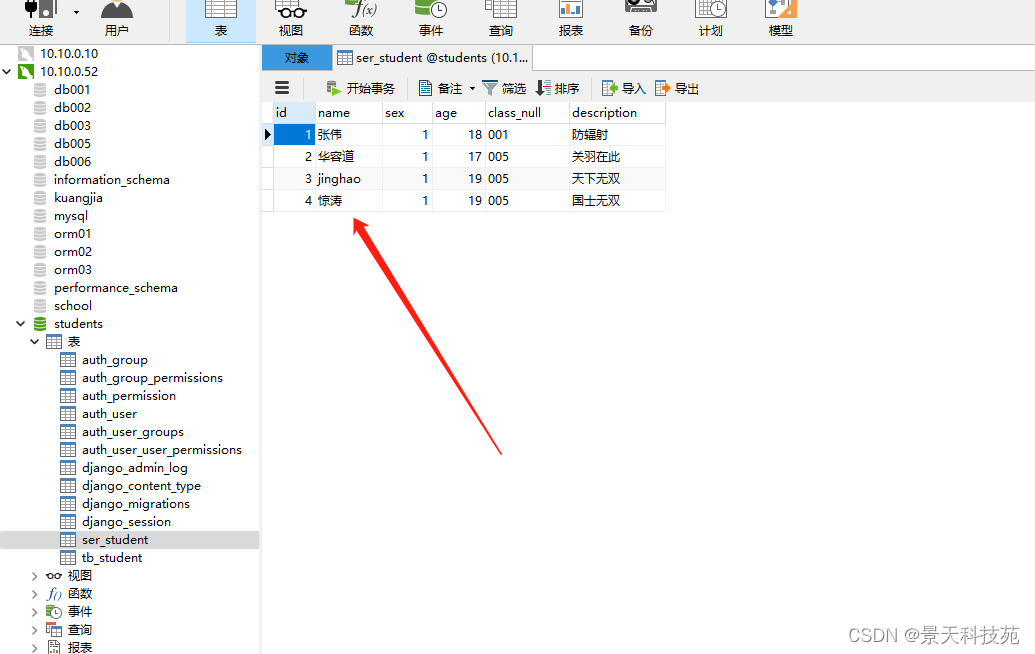
一般我们我们不是将反序列化,验证成功的数据返回,而是将保存成功的数据,再次序列化再返回,因为反序列化可能有些值没有,比如id值
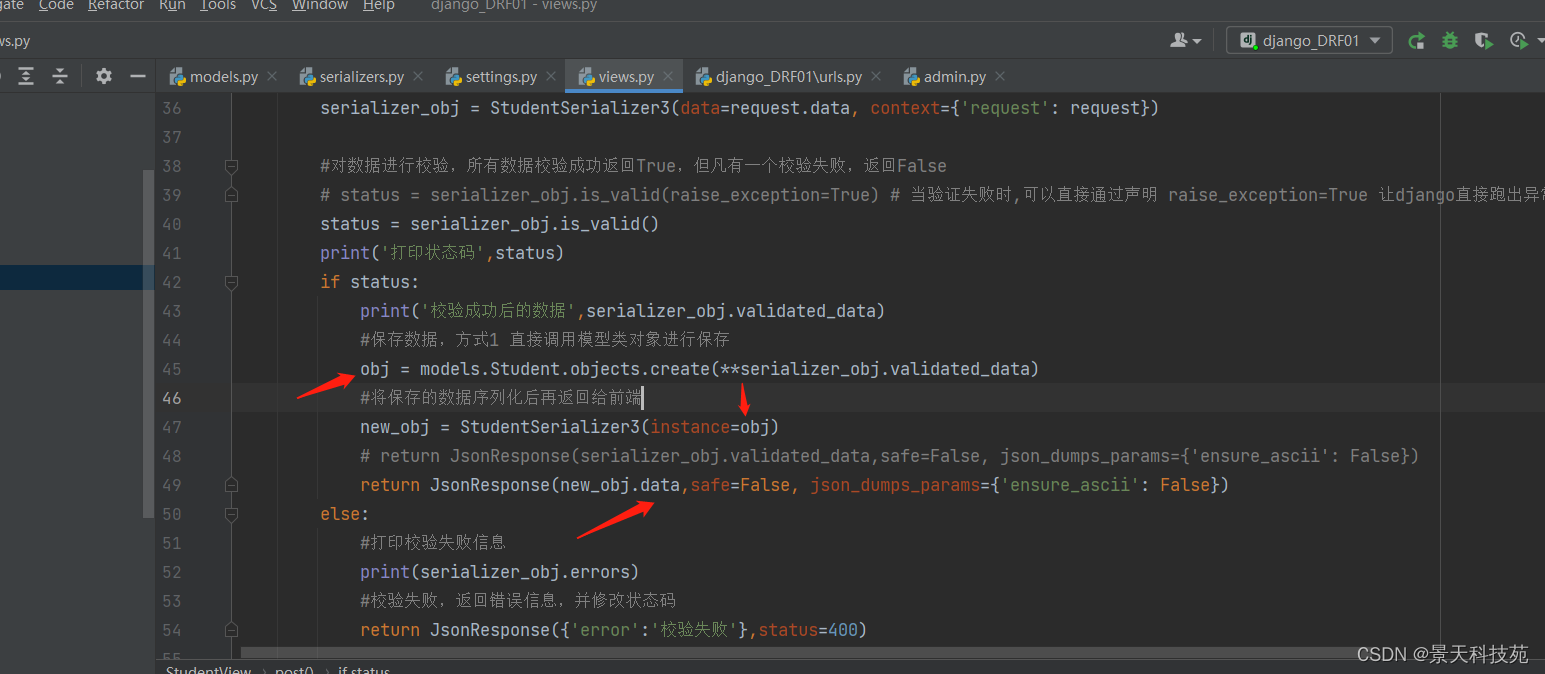
此时,返回给前端的就包含id值
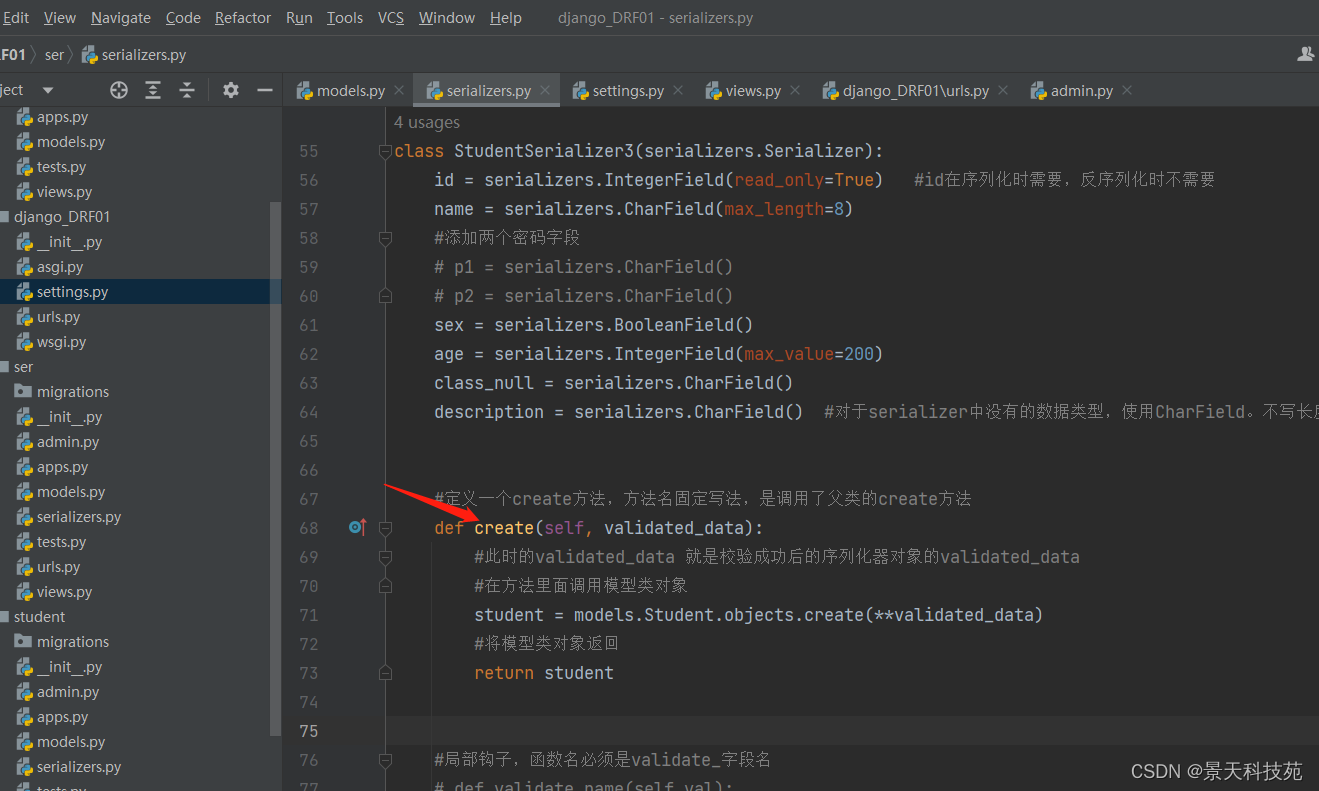
(2)数据保存方式2
还可以通过序列化器提供的create()和update()两个方法来实现数据保存。
序列化器类中会提供了两个方法: create 和 update,方法名是固定的
#定义一个create方法,方法名固定写法,是调用了父类的create方法
def create(self, validated_data):
#此时的validated_data 就是校验成功后的序列化器对象的validated_data
#在方法里面调用模型类对象
student = models.Student.objects.create(**validated_data)
#将模型类对象返回
return student
在视图函数中,通过序列化器对象调用save方法,保存数据
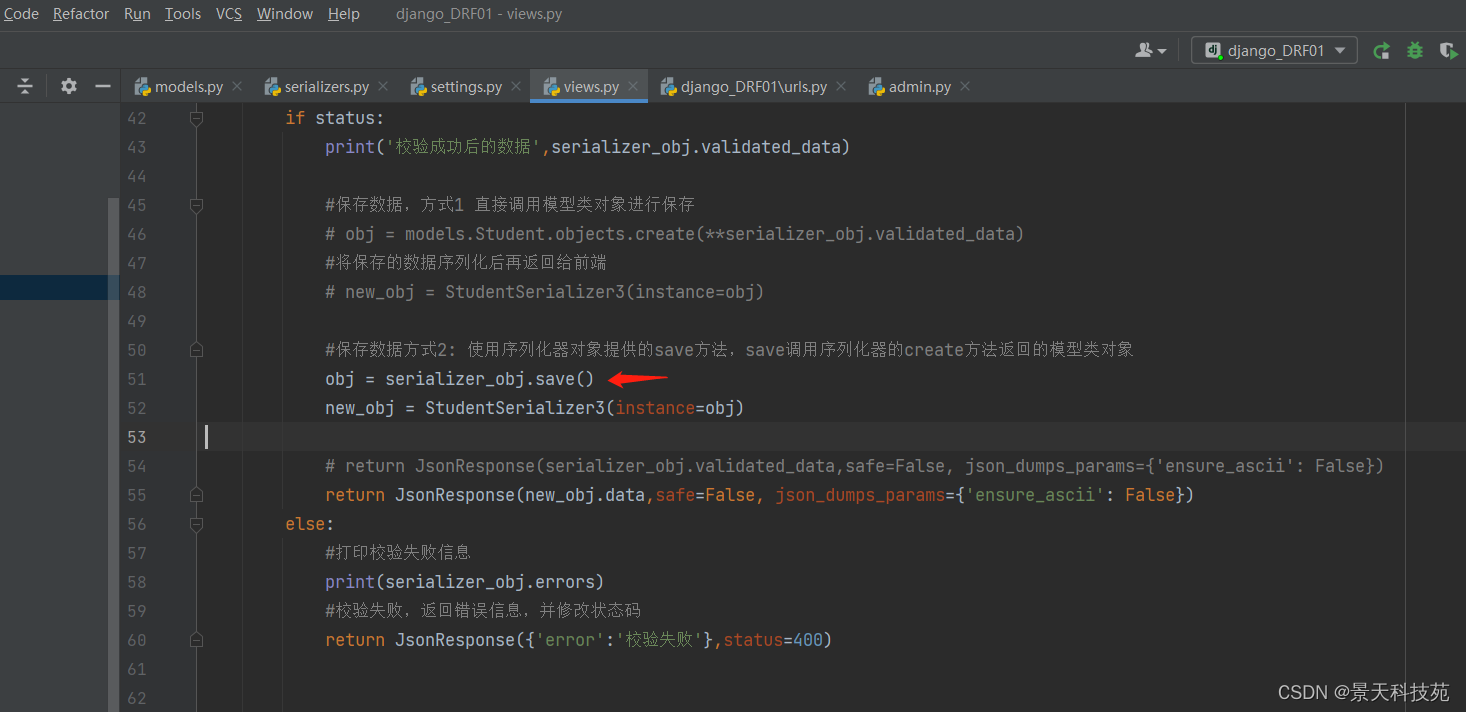
保存成功
(3)更新数据
postman模拟用户更新,发过来的数据包含id值,表示是更新数据的请求,使用put方法,json数据提交
1、更新数据方式1
默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新,partial默认为False
传递哪个字段进来,就校验哪个字段数据,没有传递过来的不校验
# 更新学生的部分字段信息,当数据库允许为空,但是序列化器要求必须字段填写的时候,可以使用以下方式避开
serializer = StudentSerializer(instance=instance, data=data, partial=True)
视图类 先定义个put函数,用来接收put请求,更新数据
#后台写个put方法,来定义更新逻辑
def put(self,request):
#默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新
serializer_obj = StudentSerializer3(data=request.data, partial=True)
if serializer_obj.is_valid():
print('校验成功的数据',serializer_obj.validated_data)
#序列化器中id设置了read_only=True 反序列化就不校验id, 所以校验成功的值validated_data中不包含id 只有通过校验的数据,才放到validated_data
# user_id = serializer_obj.validated_data.get('id')
#通过request.data用户提交的数据中拿到
user_id = request.data.get('id')
print('id',user_id)
obj = models.Student.objects.filter(id=user_id)
obj.update(**serializer_obj.validated_data)
new_obj = obj.first()
obj = StudentSerializer3(instance=new_obj)
return JsonResponse(obj.data,safe=False, json_dumps_params={'ensure_ascii': False})
else:
#打印校验失败信息
print(serializer_obj.errors)
#校验失败,返回错误信息,并修改状态码
return JsonResponse({'error':'校验失败'},status=400)
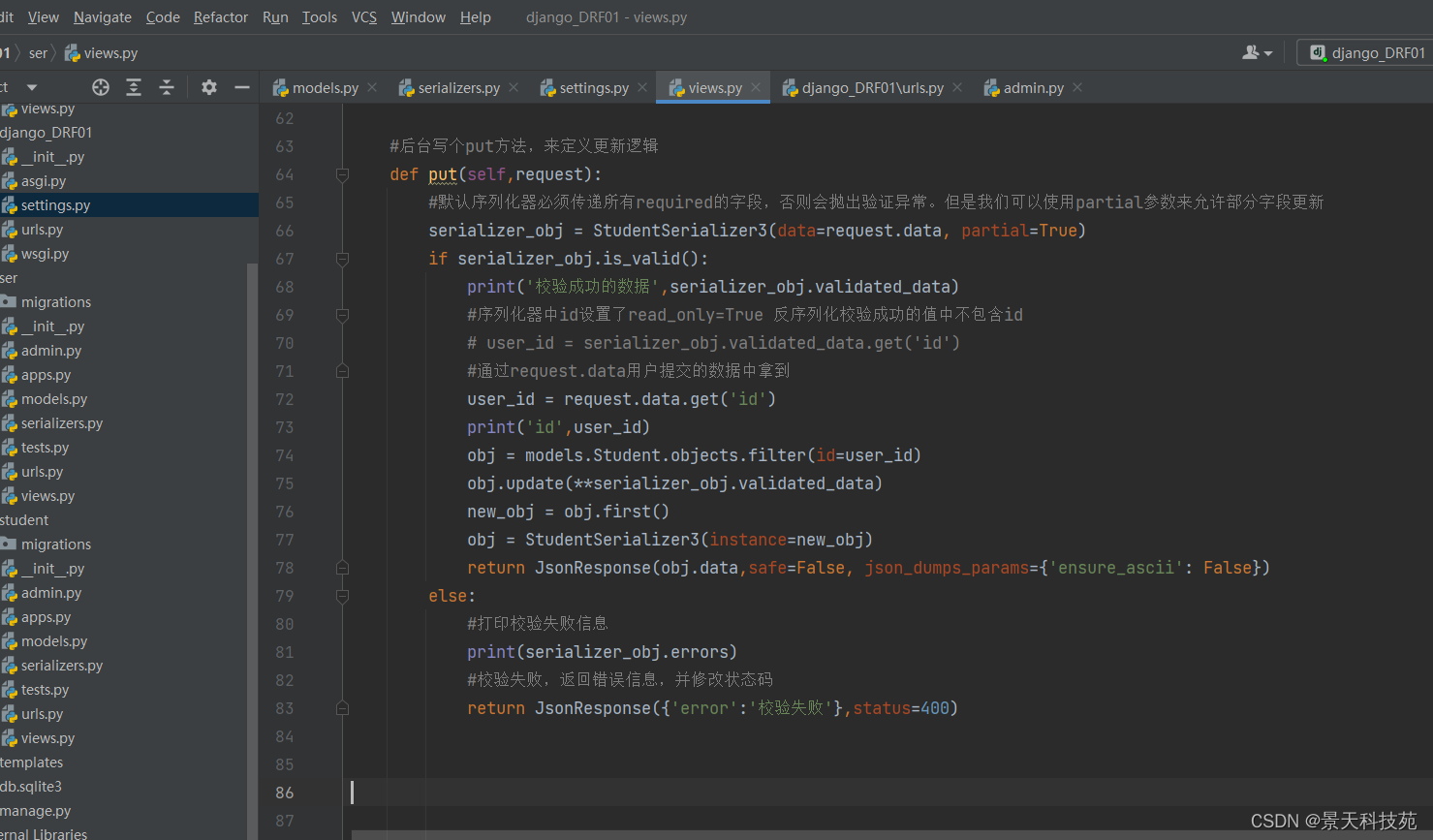
提交修改请求
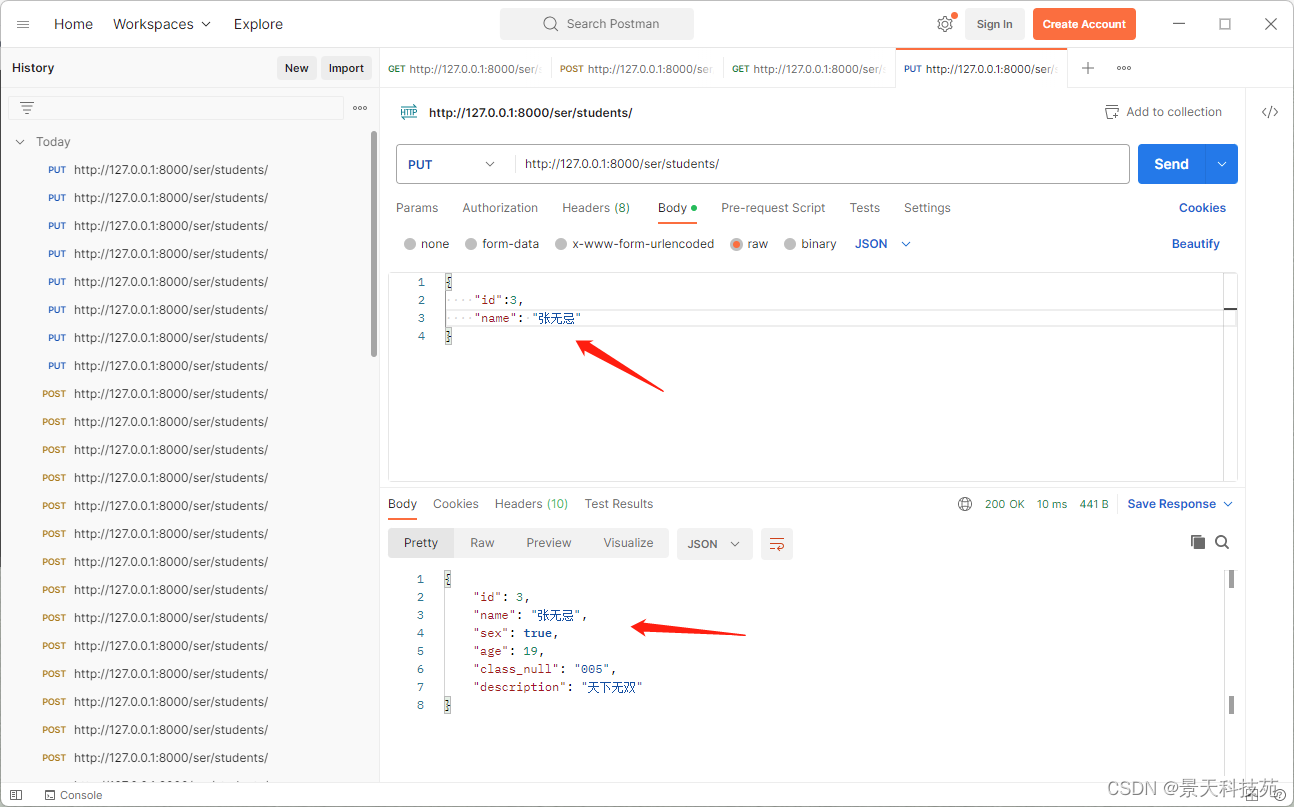
数据库已被修改
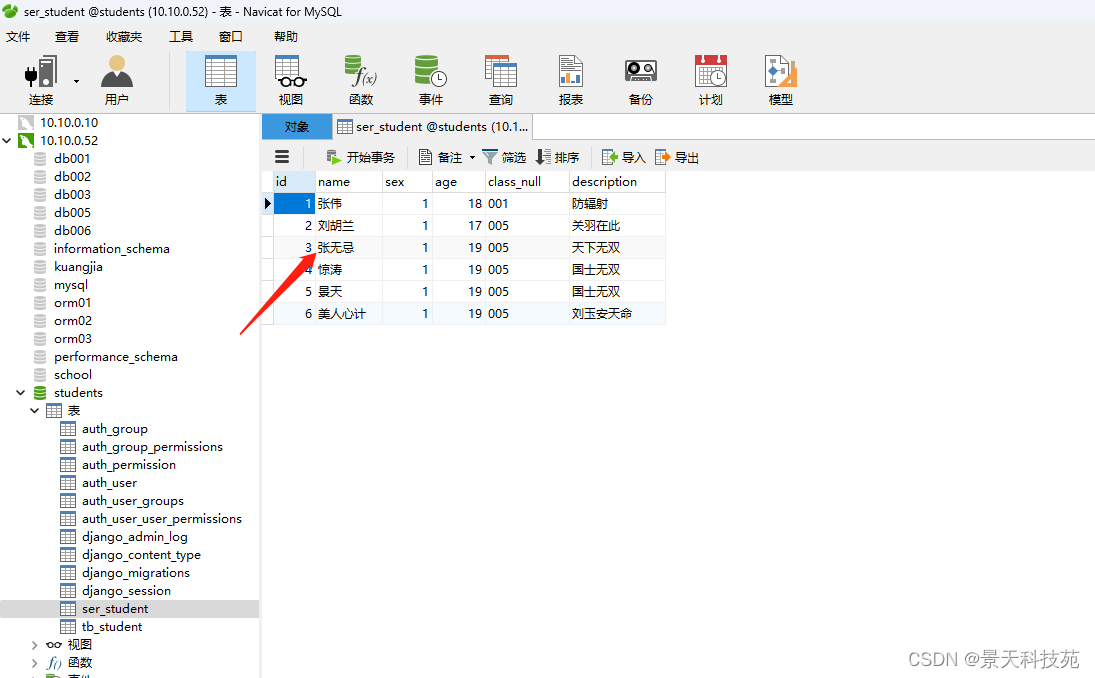
2、更新数据方式2
save方法更新
序列化器类中定义update方法
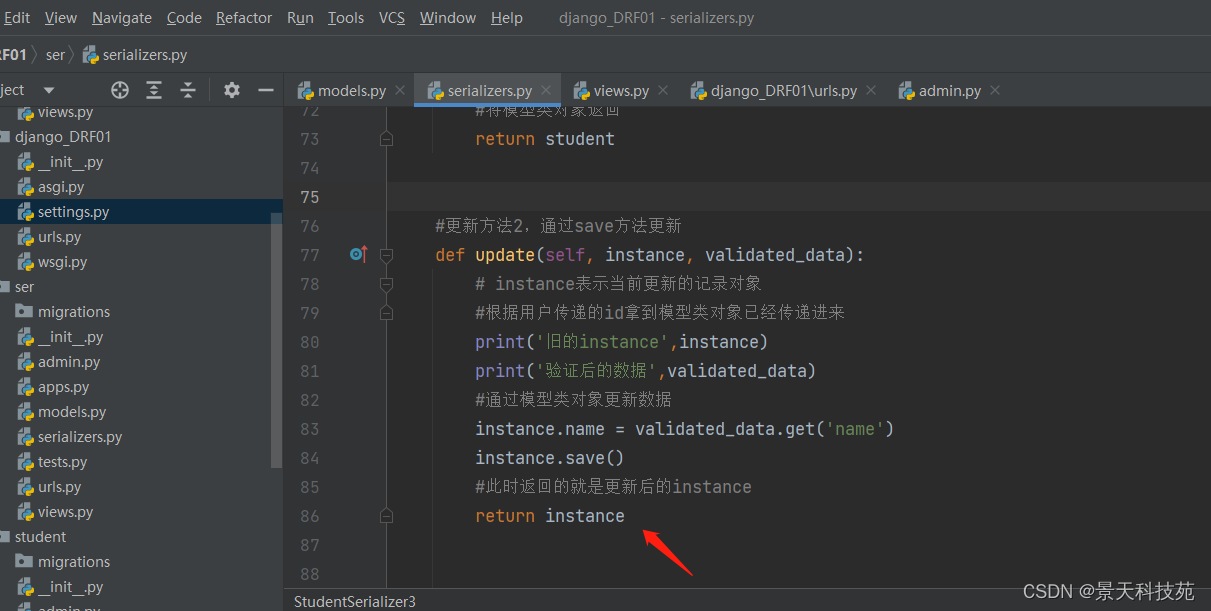
#更新方法2,通过save方法更新
def update(self, instance, validated_data):
# instance表示当前更新的记录对象,validated_data是用户提交数据验证成功后的字典类型数据
#根据用户传递的id拿到模型类对象已经传递进来
print('旧的instance',instance)
print('验证后的数据',validated_data)
#通过模型类对象更新数据
instance.name = validated_data.get('name')
#这个是orm通过模型类对象保存数据的方法
instance.save()
#此时返回的就是更新后的instance
return instance
视图类掉调用序列化器对象的save方法
#后台写个put方法,来定义更新逻辑
def put(self,request):
#默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新
#更新方式1
# serializer_obj = StudentSerializer3(data=request.data, partial=True)
#更新方式2
#先根据提交id将用户模型类对象拿出来
obj = models.Student.objects.filter(id=request.data.get('id')).first()
#将模型类对象作为参数传给序列化器, instance的值是模型类对象
serializer_obj = StudentSerializer3(data=request.data, partial=True, instance=obj)
if serializer_obj.is_valid():
print('校验成功的数据',serializer_obj.validated_data)
#更新数据方式1:
#序列化器中id设置了read_only=True 反序列化校验成功的值中不包含id
# user_id = serializer_obj.validated_data.get('id')
#通过request.data用户提交的数据中拿到
# user_id = request.data.get('id')
# print('id',user_id)
# obj = models.Student.objects.filter(id=user_id)
# obj.update(**serializer_obj.validated_data)
# new_obj = obj.first()
# obj = StudentSerializer3(instance=new_obj)
#更新数据方式2:
#因为实例化序列化器对象时,传递了instance对象,所以此时执行save方法,调用的是序列化类中的update方法
#如果不传递instance模型类对象,执行save方法,调用的就是序列化类中的create方法
obj = serializer_obj.save()
new_obj = StudentSerializer3(instance=obj)
return JsonResponse(new_obj.data,safe=False, json_dumps_params={'ensure_ascii': False})
else:
#打印校验失败信息
print(serializer_obj.errors)
#校验失败,返回错误信息,并修改状态码
return JsonResponse({'error':'校验失败'},status=400)
提交put更新请求
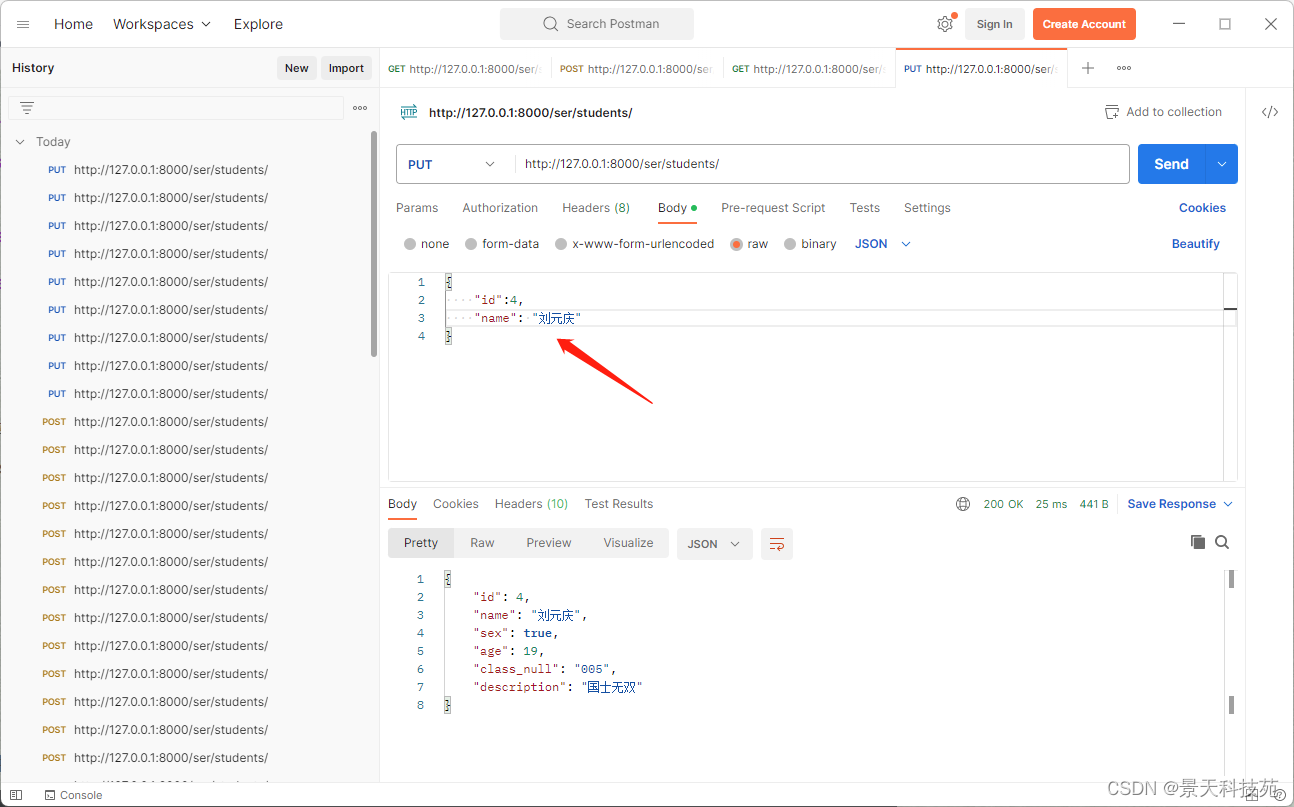
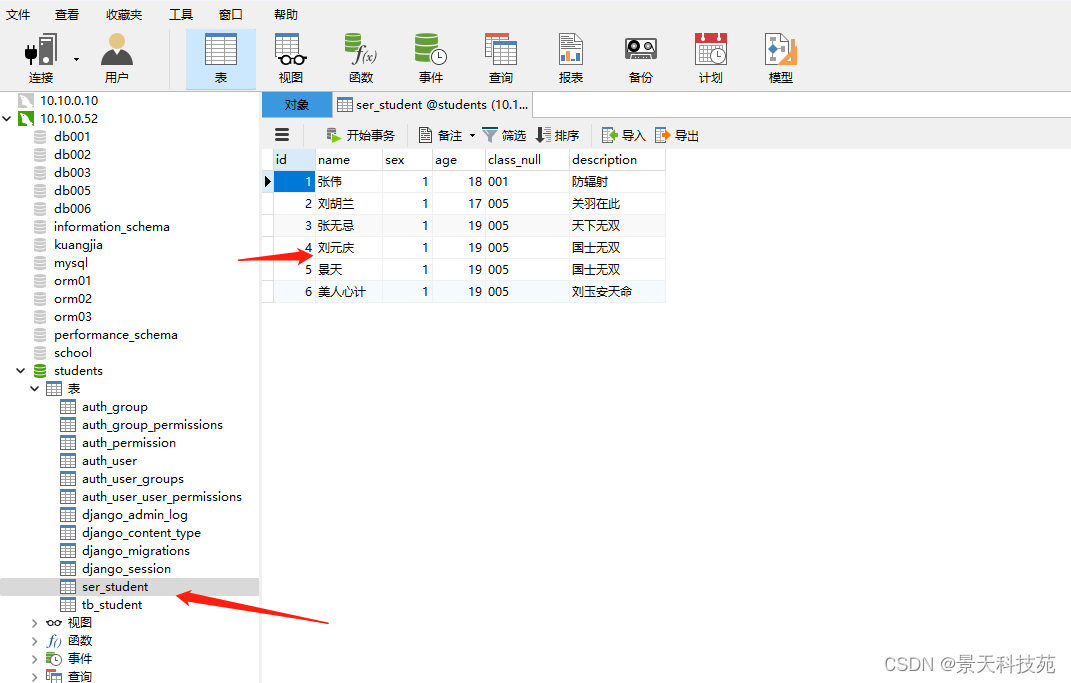
修改成功
5.ORM中的CharField
ORM中的对于CharField,TextField等字符串类型数据,虽然默认字段都有非空约束
但是ORM在保存数据时,如果未传值,会向该字段插入空字符串
ORM认为,字符串类型和null不是一个类型
null也是空字符串,‘‘也是空字符串,对于未传值的字段设为’’,而不是null。所以没有违反非空约束,没有报错
所以,如果数据库字段设置为非空约束,那么数据校验时,必须让它传值,默认就是必须传值 required=True allow_blank = False 也是默认的
而不应该设为 required= False 允许传值
校验条件设置了允许不传值
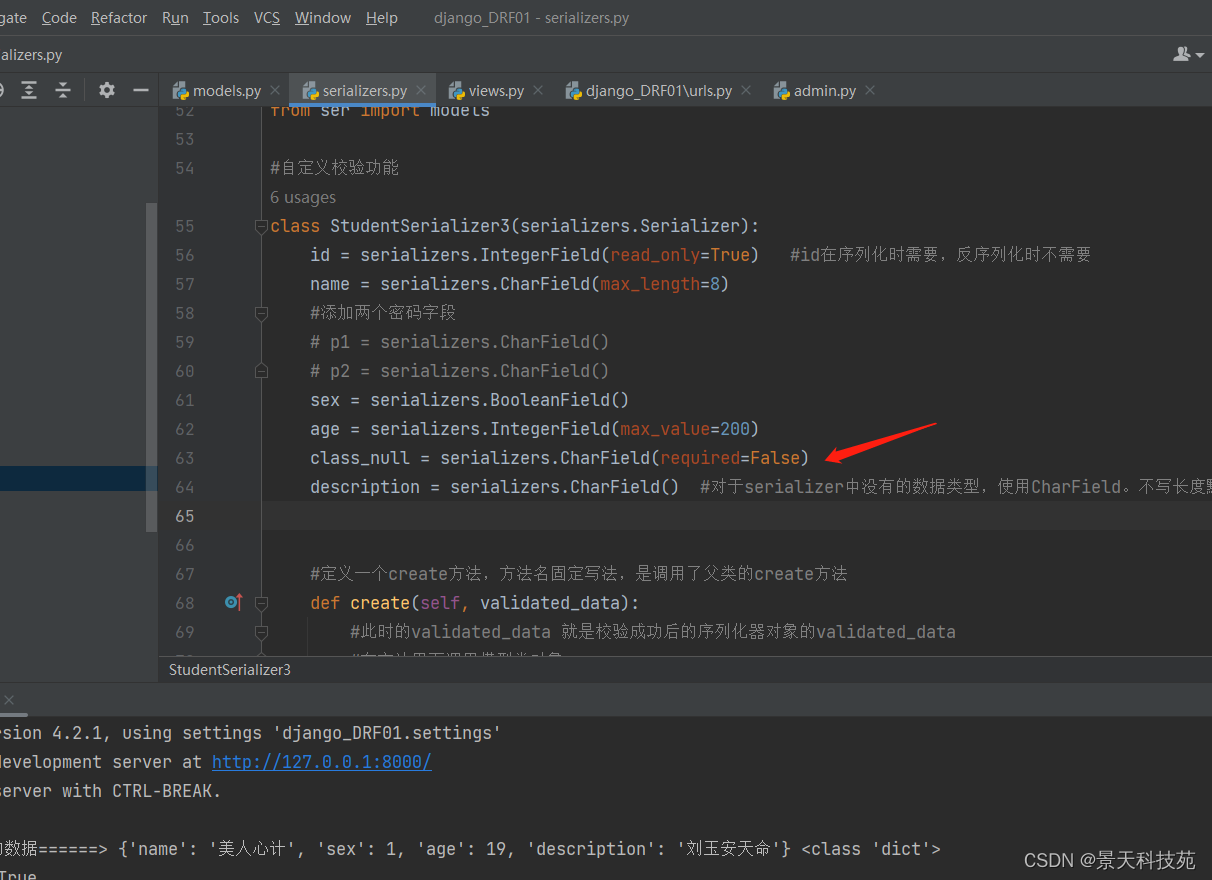
提交post添加记录请求,不传该字段
可以看到响应回来的该字段是空字符串
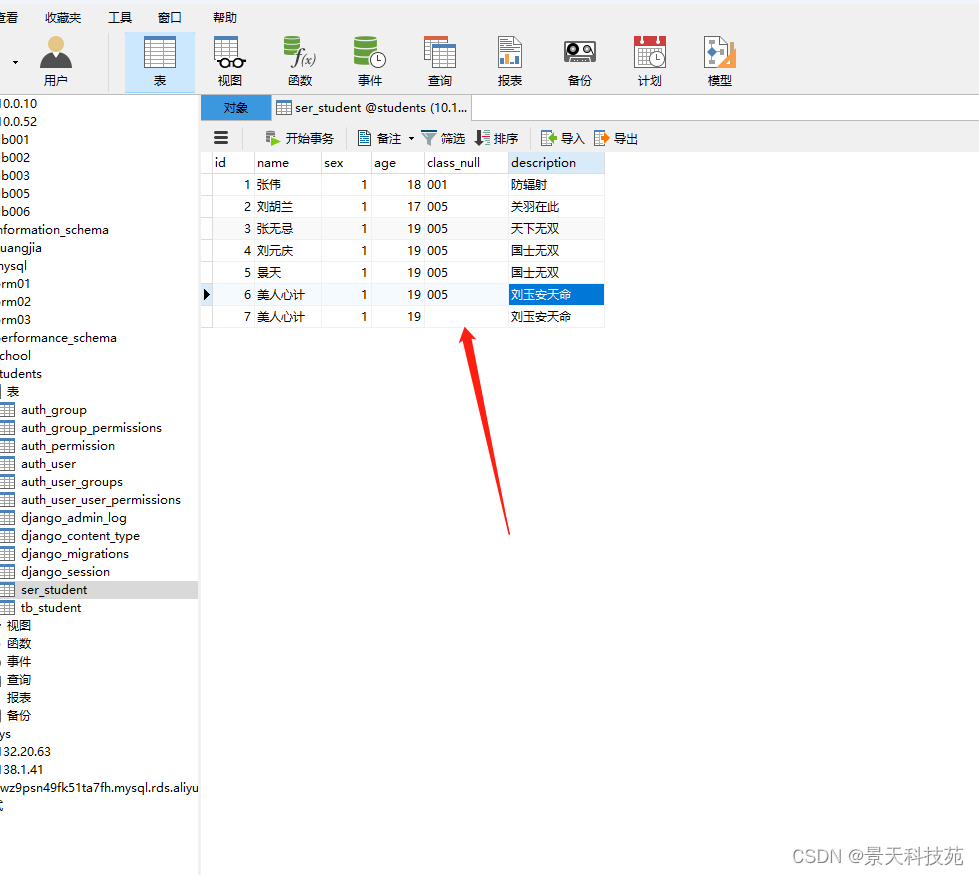
保存到数据库中的取值空字符串
6.ModelSerializer 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列序列化类中的字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现
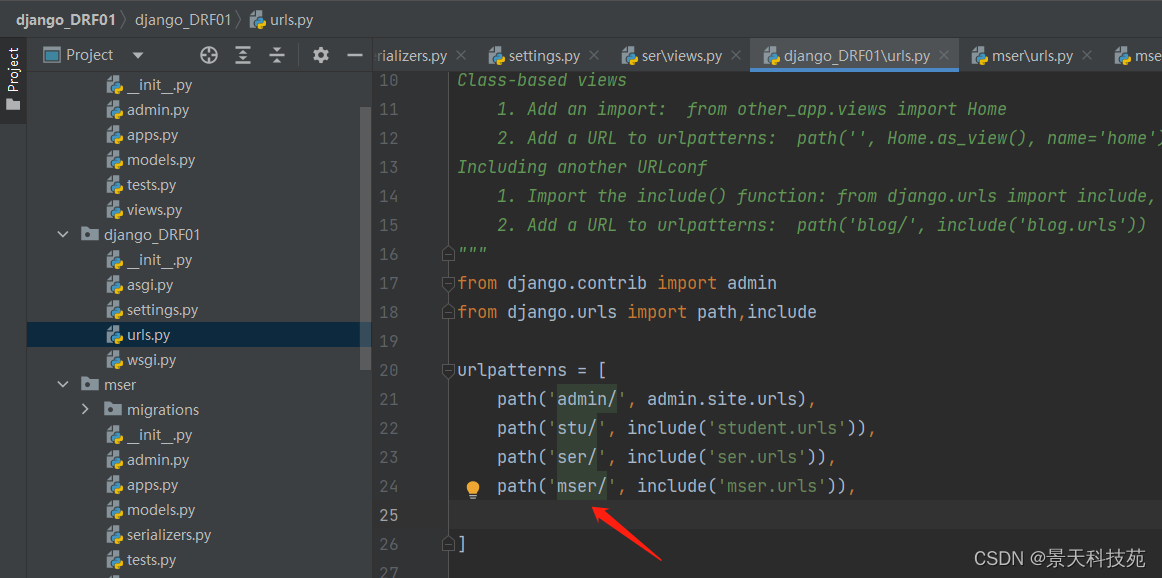
重新创建个应用mser
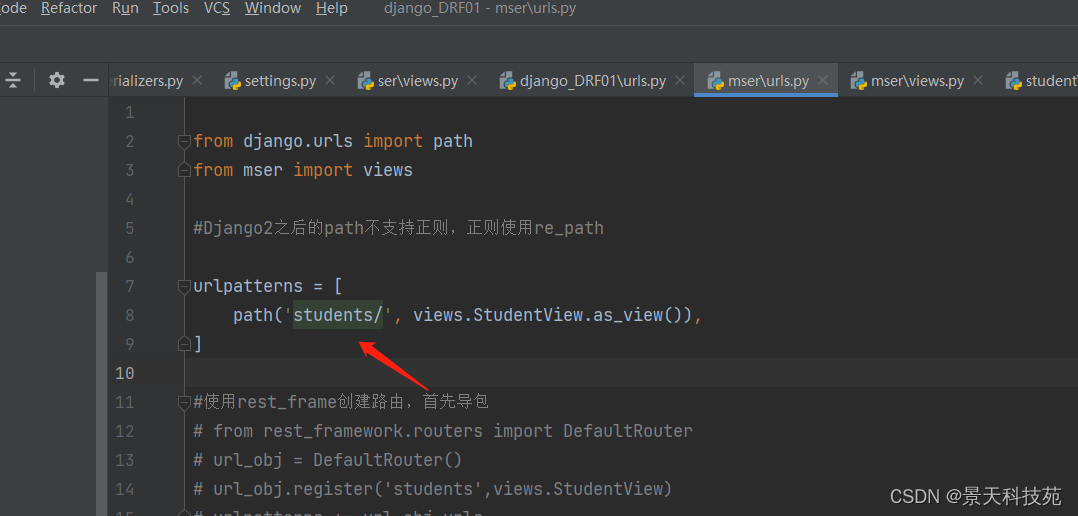
路由
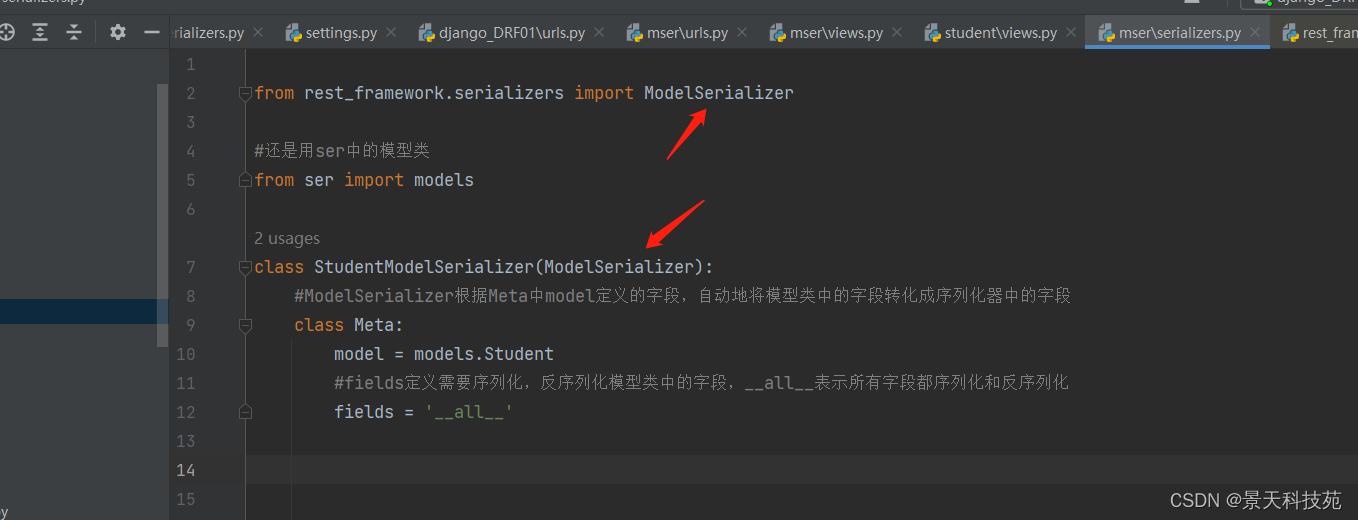
序列化器,使用ModelSerializer
视图类

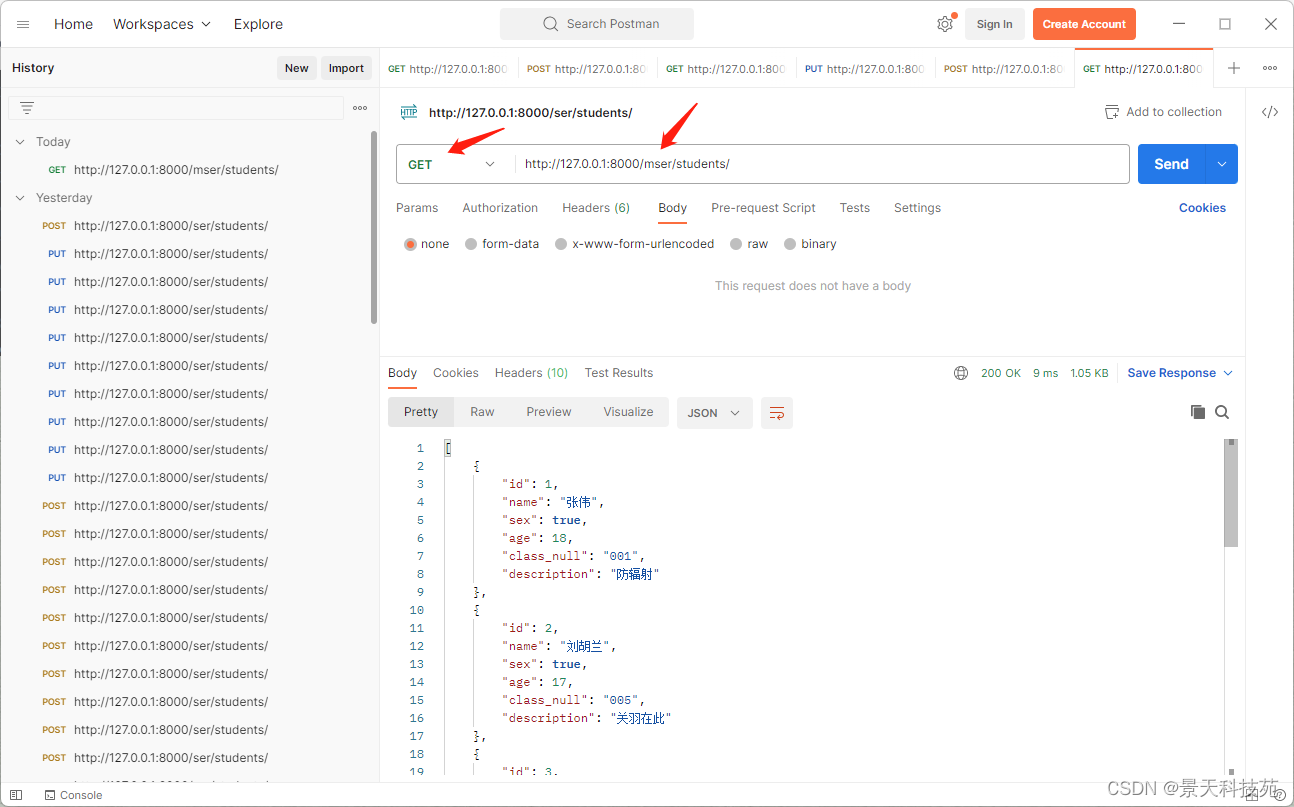
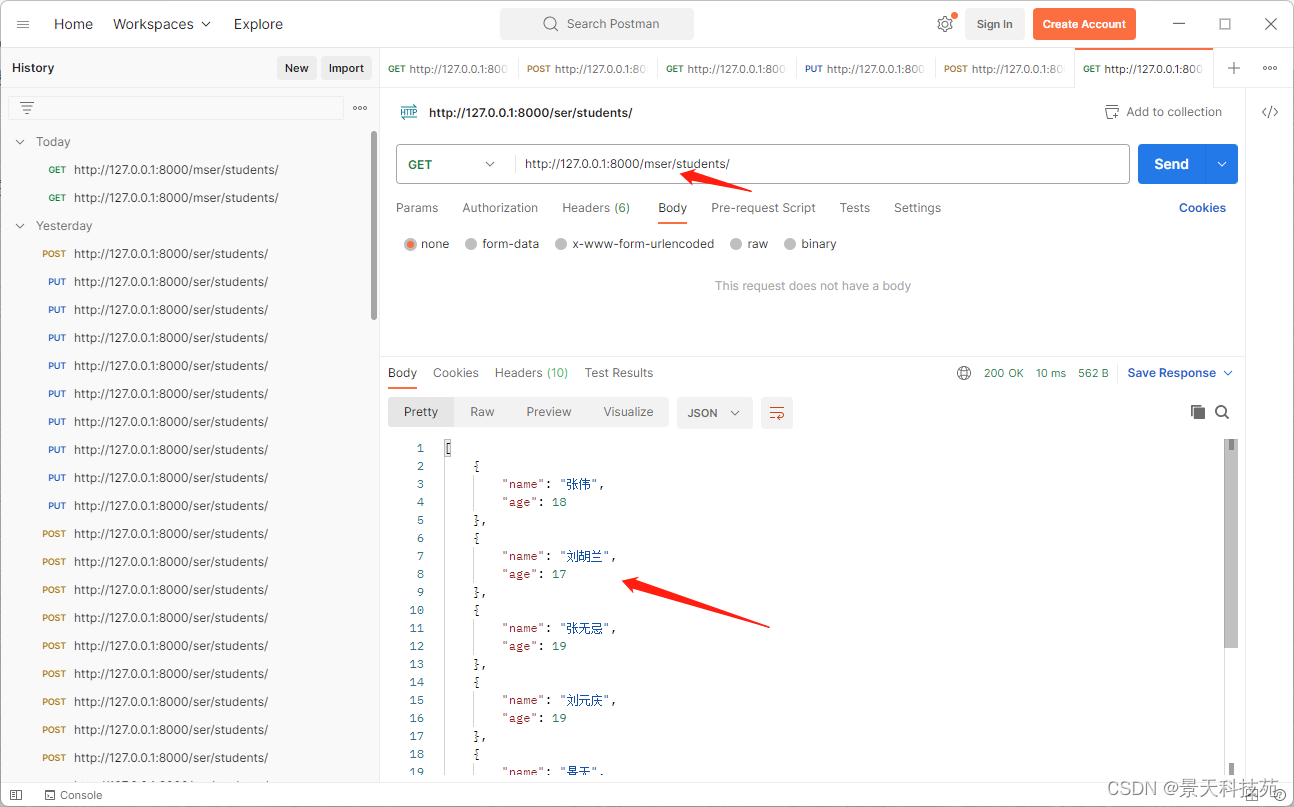
postman get请求访问,可以拿到数据
在序列化器中,也可以指定序列化指定字段
from rest_framework.serializers import ModelSerializer
#还是用ser中的模型类
from ser import models
class StudentModelSerializer(ModelSerializer):
#ModelSerializer根据Meta中model定义的字段,自动地将模型类中的字段转化成序列化器中的字段
class Meta:
model = models.Student
#fields定义需要序列化,反序列化模型类中的字段,__all__表示所有字段都序列化和反序列化
# fields = '__all__'
#fields字段还可以指定序列化指定字段,用列表或元祖包裹
fields = ['name','age']
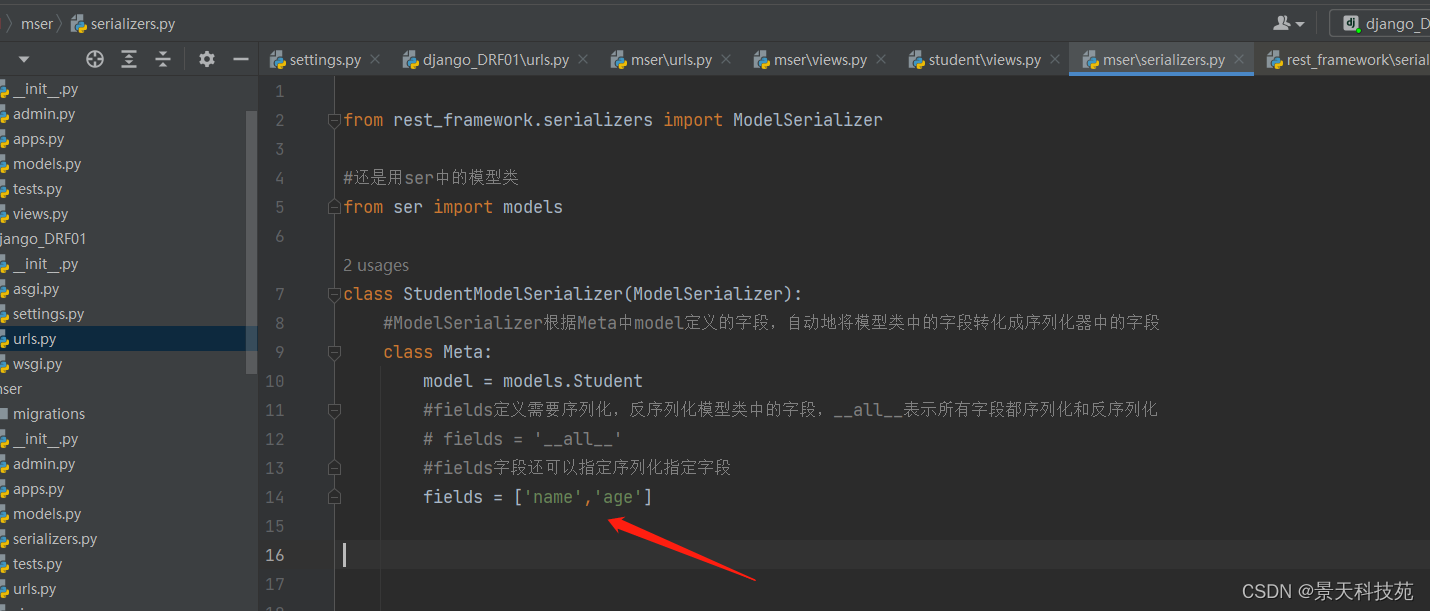
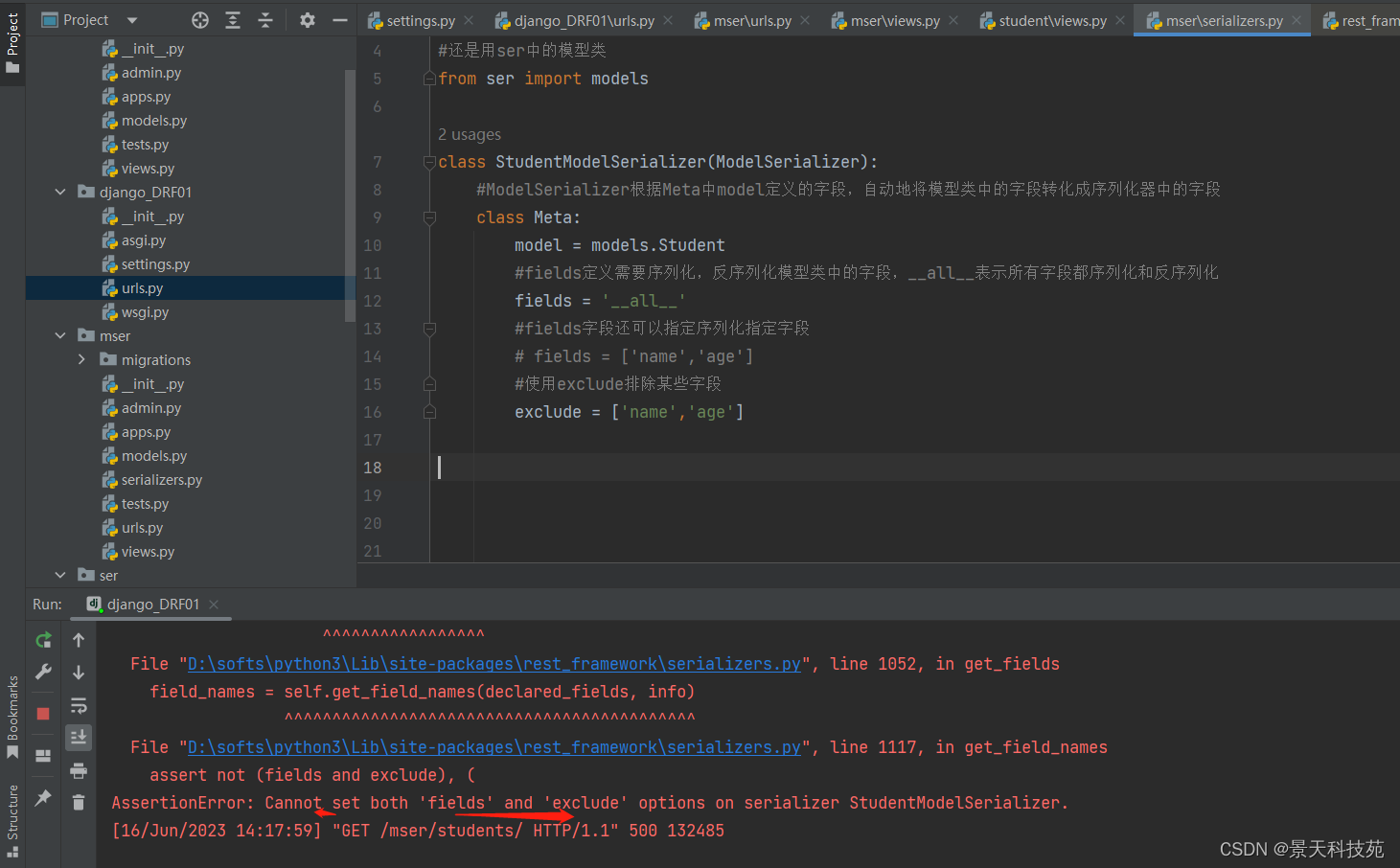
如果想排除某些字段,其他字段都序列化,使用exclude
exclude和fields不能同时使用,不然报错
正常使用,只用exclude
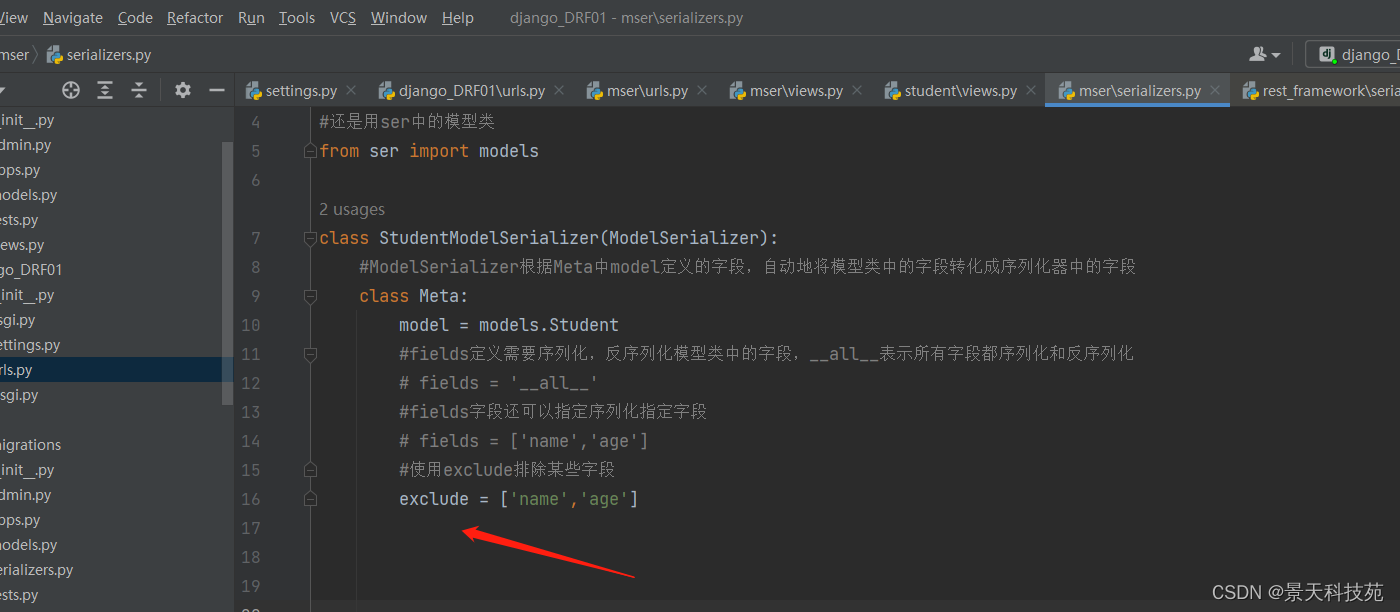
看GET请求,响应里面没有name和age
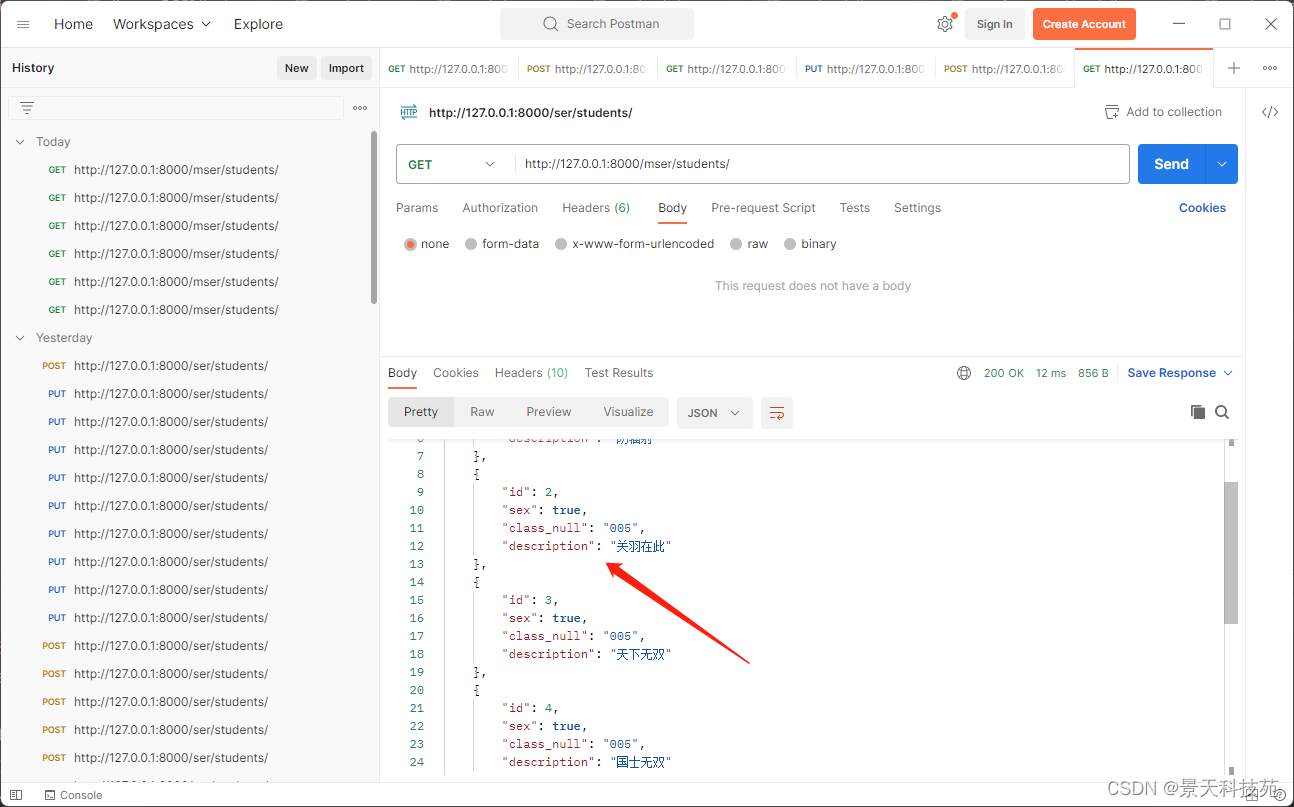
自定义个字段的参数
read_only_fields
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
write_only_fields。仅用于反序列化校验
这俩很少用,通过extra_kwargs更方便一些
class StudentModelSerializer(serializers.ModelSerializer):
"""学生数据序列化器"""
class Meta:
model = Student
fields = ['id', 'age', 'name',"description"]
read_only_fields = ('id',)
#write_only_fields = ('sex',)
添加额外参数
extra_kwargs
我们可以使用extra_kwargs参数为ModelSerializer添加或修改原有的选项参数
额外字段声明,必须在fields里面也要声明上去,否则序列化器不会调用
extra_kwargs 用字典包裹
from rest_framework import serializers
from students.models import Student
class StudentModelSerializer(serializers.ModelSerializer):
# 额外字段声明,必须在fields里面也要声明上去,否则序列化器不会调用
# password2 = serializers.CharField(write_only=True,required=True)
# 如果模型类序列化器,必须声明本次调用是哪个模型,模型里面的哪些字段
class Meta:
model = Student
# fields = ["id","name","age","description","sex","password2"]
fields = ["id","name","age","description","sex"]
# fields = "__all__" # 表示操作模型中的所有字段
# 添加额外的验证选项,比如额外的字段验证
extra_kwargs = {
"sex":{"write_only":True,},
"id":{"read_only":True,}
}
验证代码
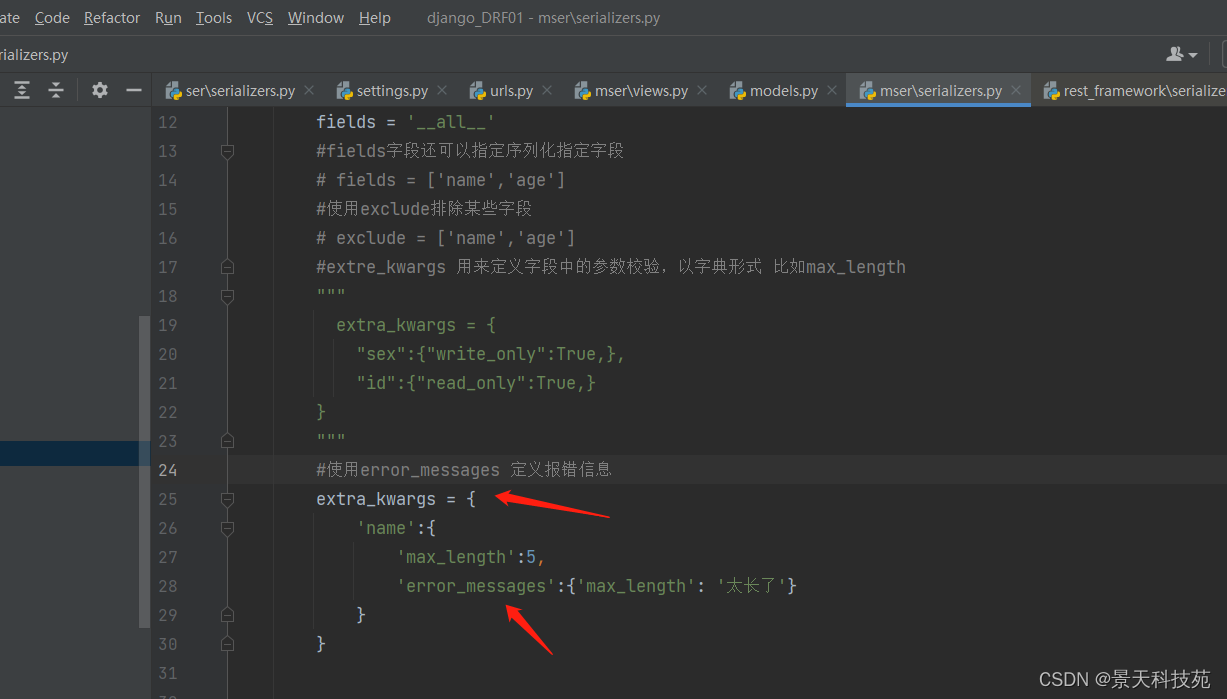
如下设置name长度最长限制5位,当提交数据好过5位,就报错。与基础类的serializer报的错是一样的

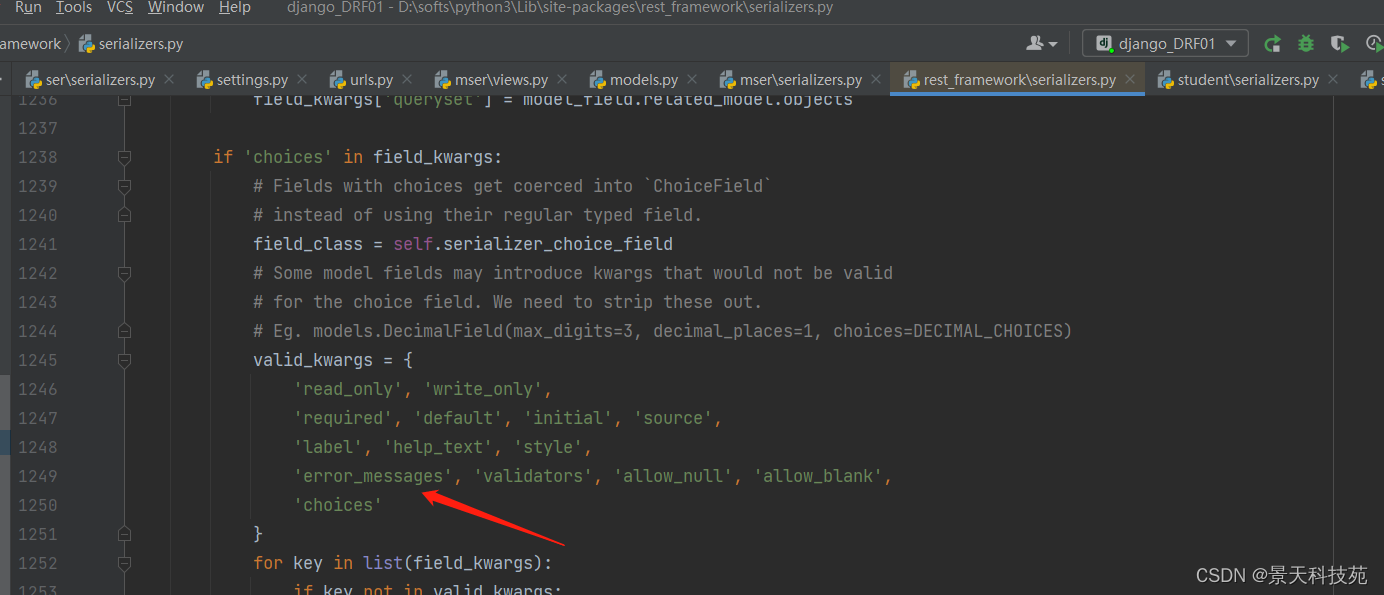
使用error_messages自定义报错信息,根据源码可知,error_messages放在extra_kwargs里面
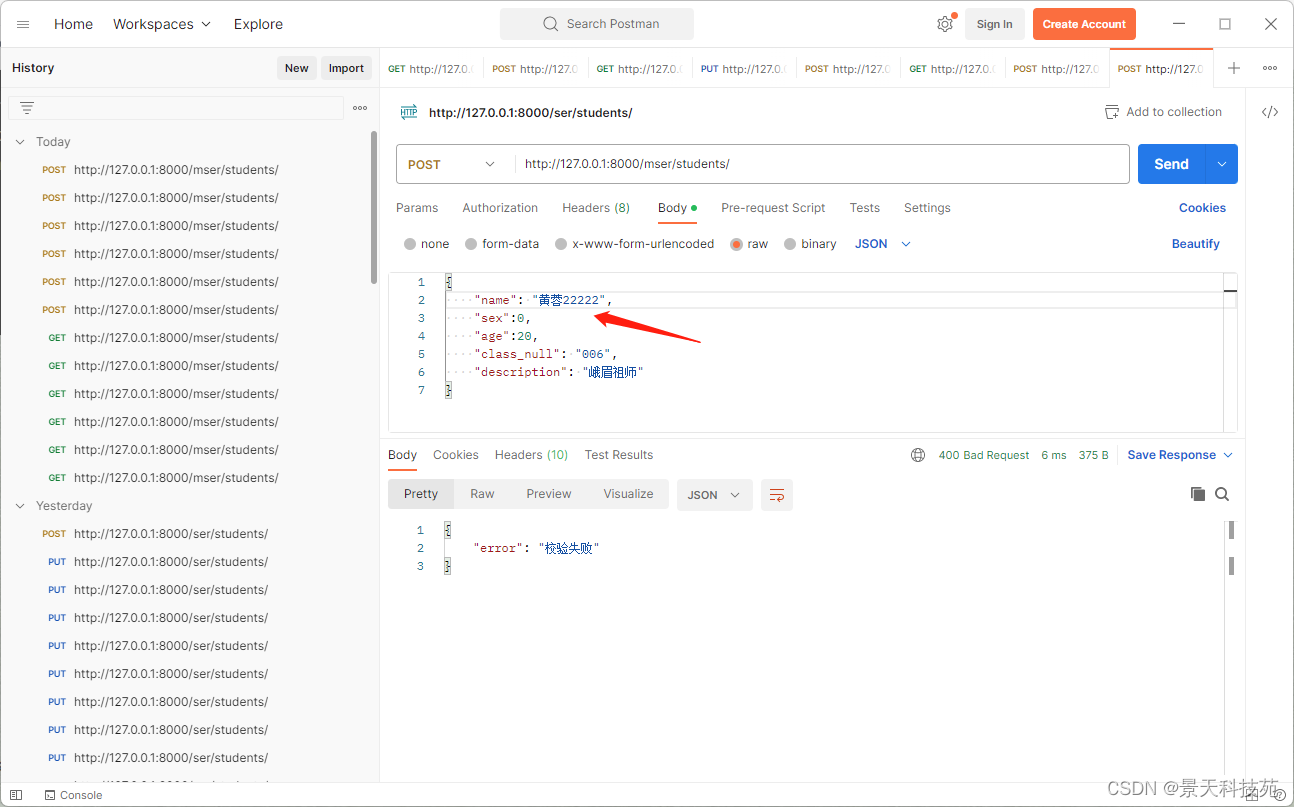
查看报错信息
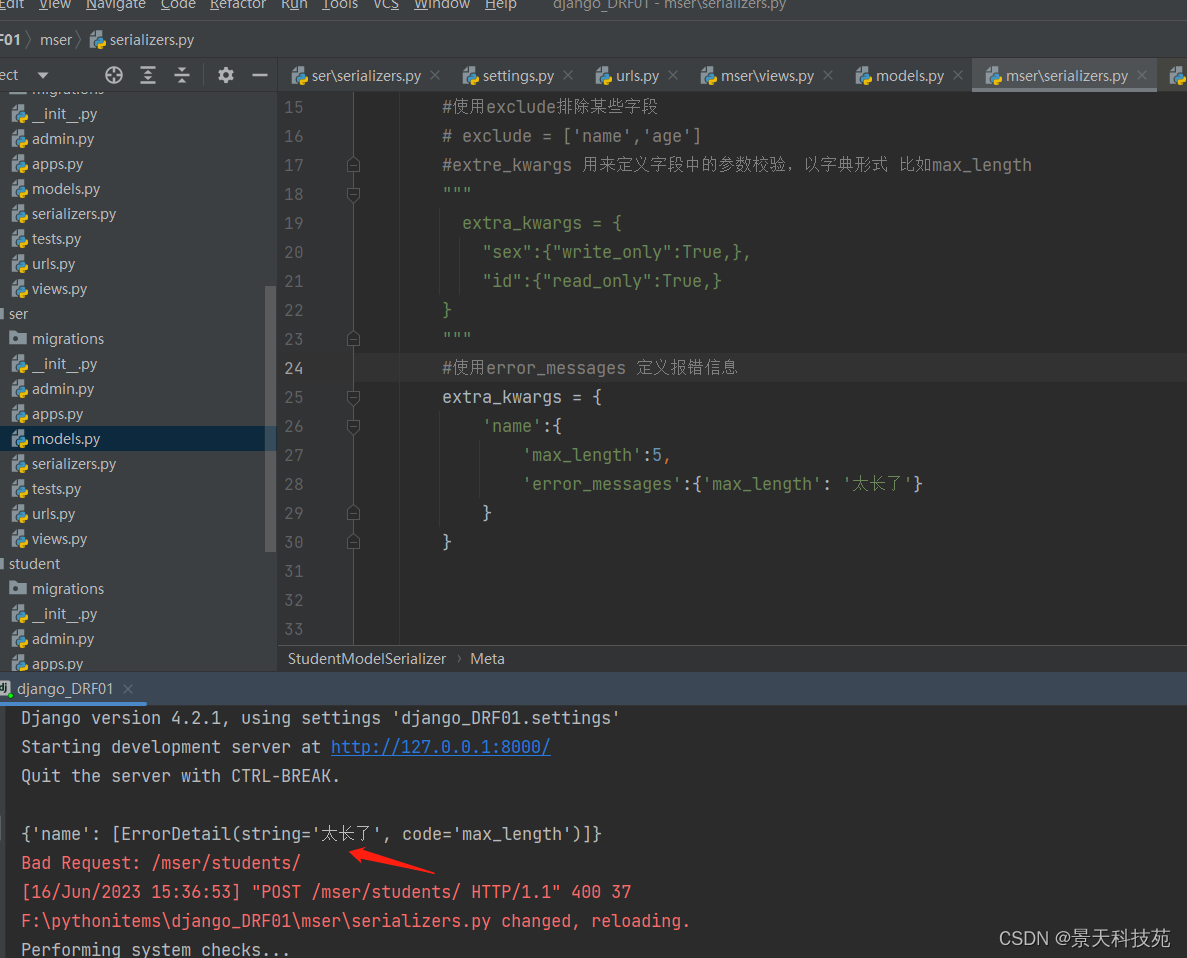
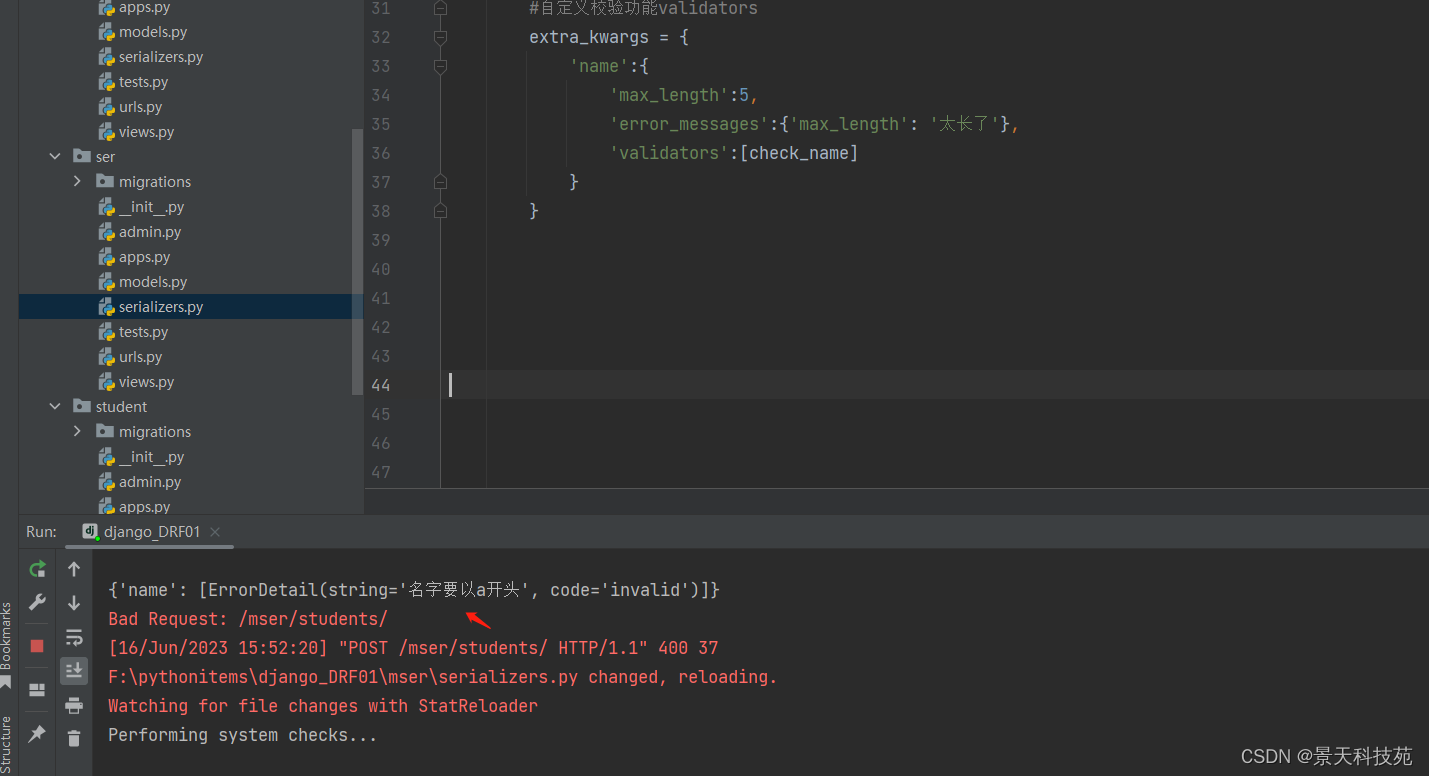
自定义校验 validators:也是写在extra_kwargs里面
先定义一个函数
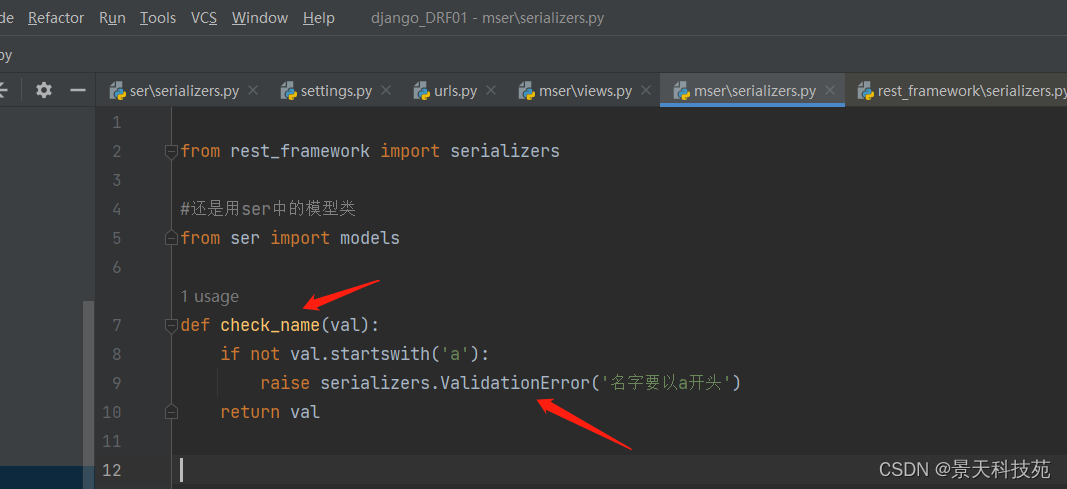
在validators 引用,以列表方式把函数名放进去
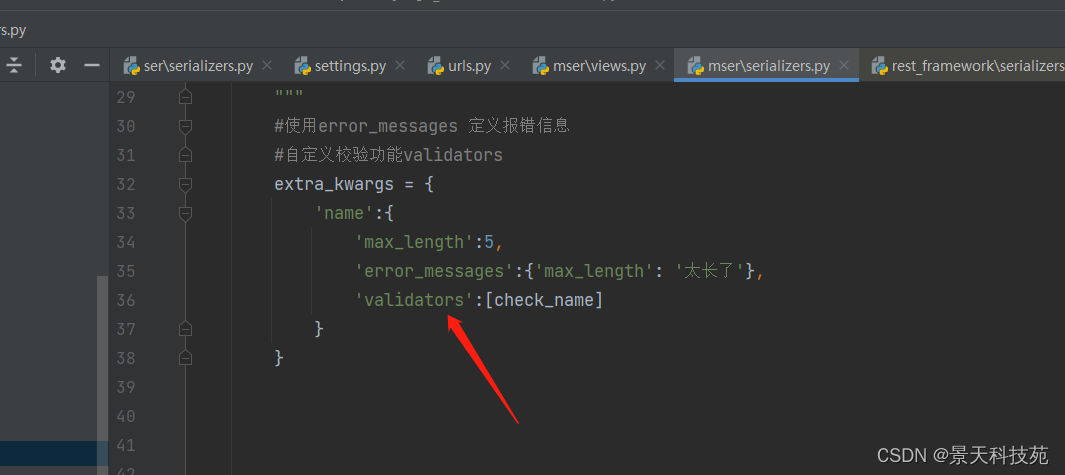
提交请求
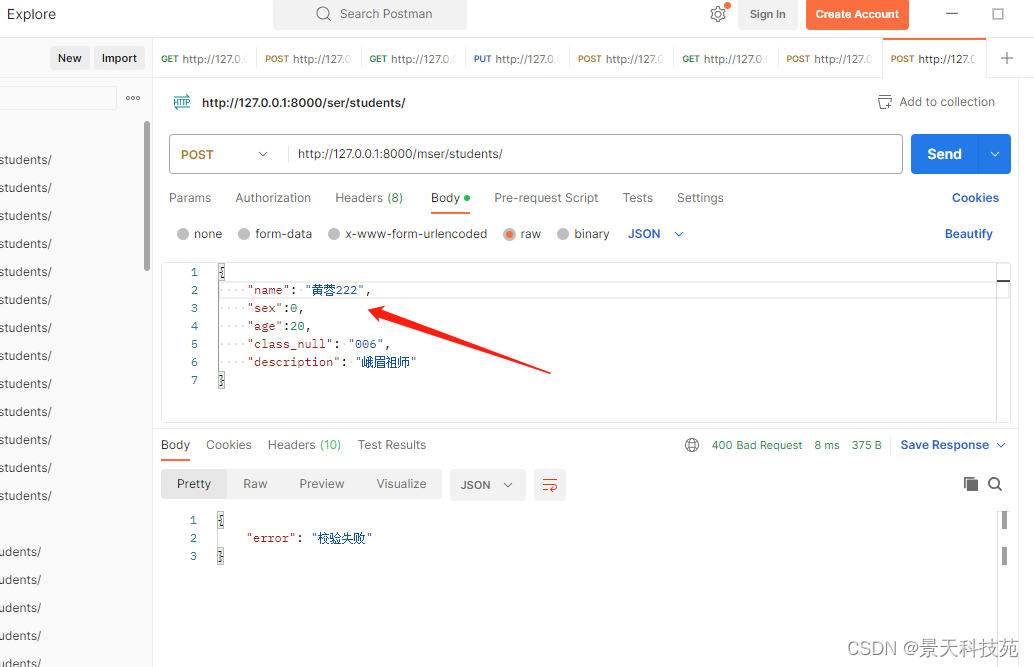
查看报错
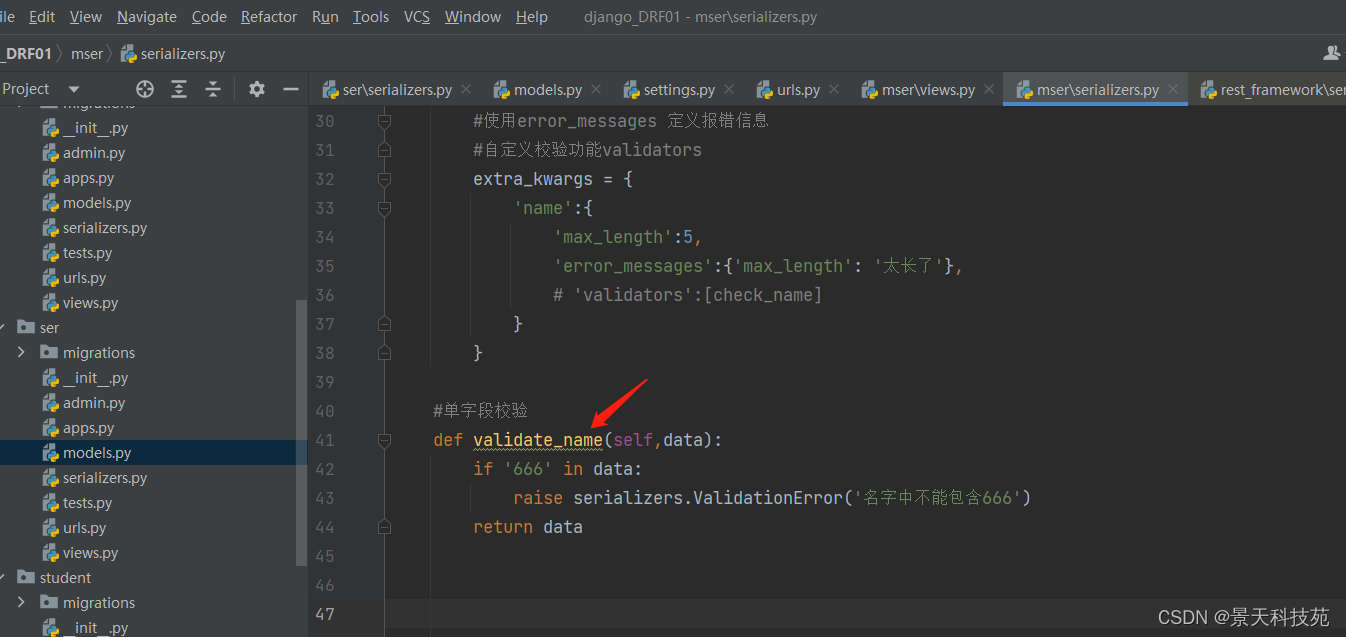
局部钩子:单字段校验,这个与calss Meta同级的,写在类里面

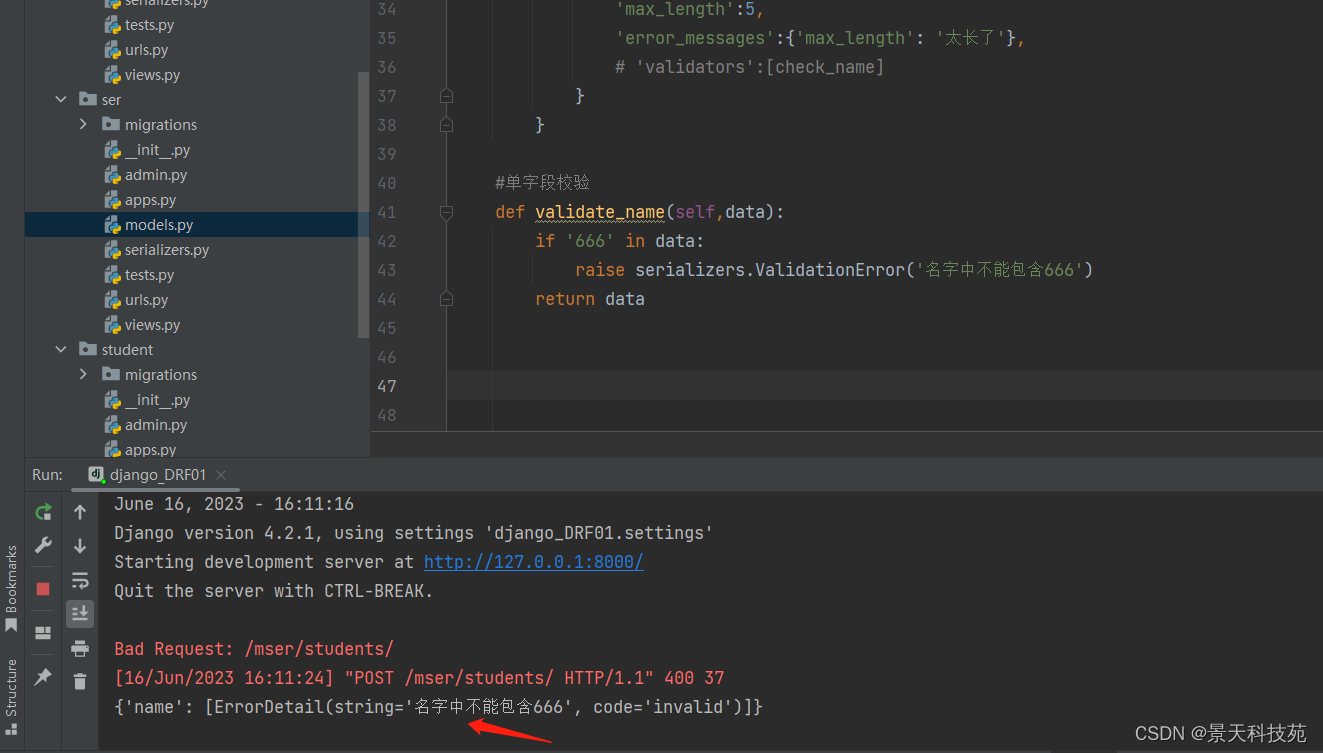
全局钩子:多字段联合校验
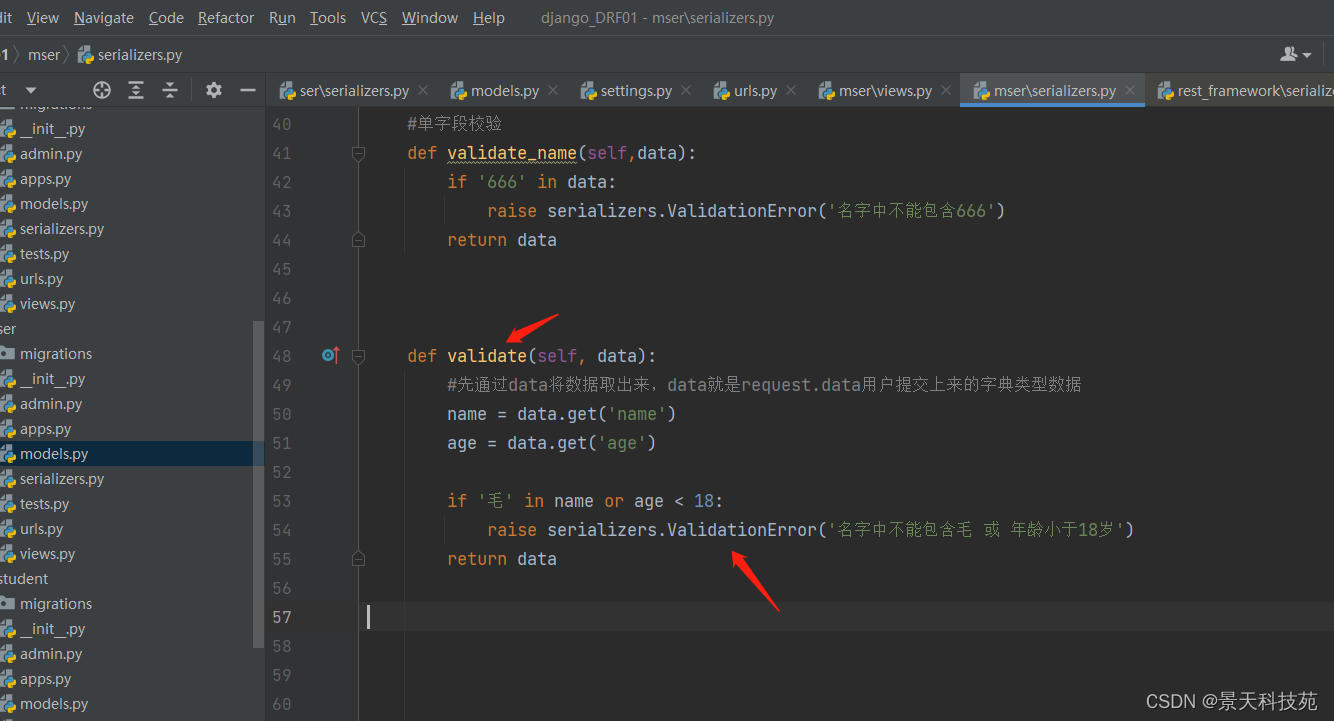
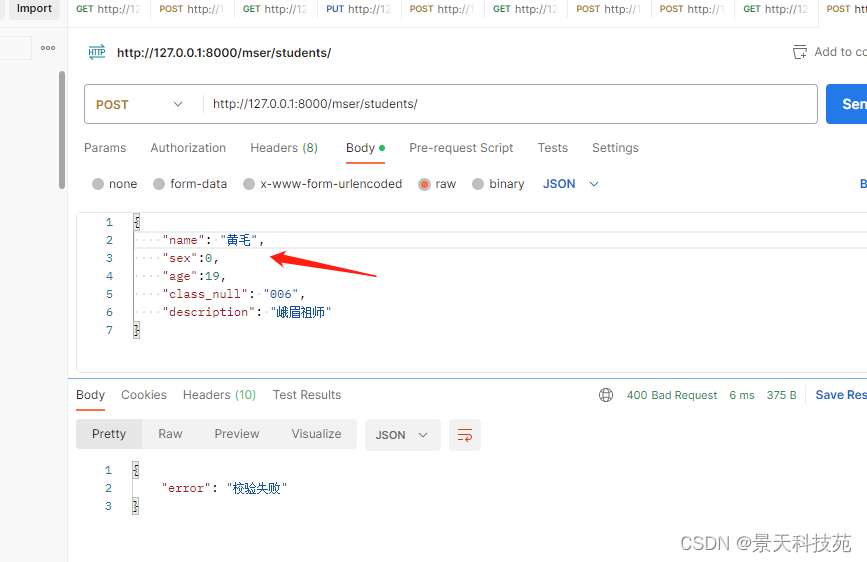
查看报错,实现效果

什么时候继承序列化器类Serializer,什么时候继承模型序列化器类ModelSerializer?主要还是看哪个更适合你的应用场景
继承序列化器类Serializer
字段声明
验证
添加/保存数据功能
继承模型序列化器类ModelSerializer
字段声明[可选,看需要]
Meta声明
验证
添加/保存数据功能[可选]
一般还是用ModelSerializer多些 校验两次输入密码是否相同,可以重载父类create方法,将多的那个密码删除,然后再将模型类对象返回
在视图函数只需要save就可以了
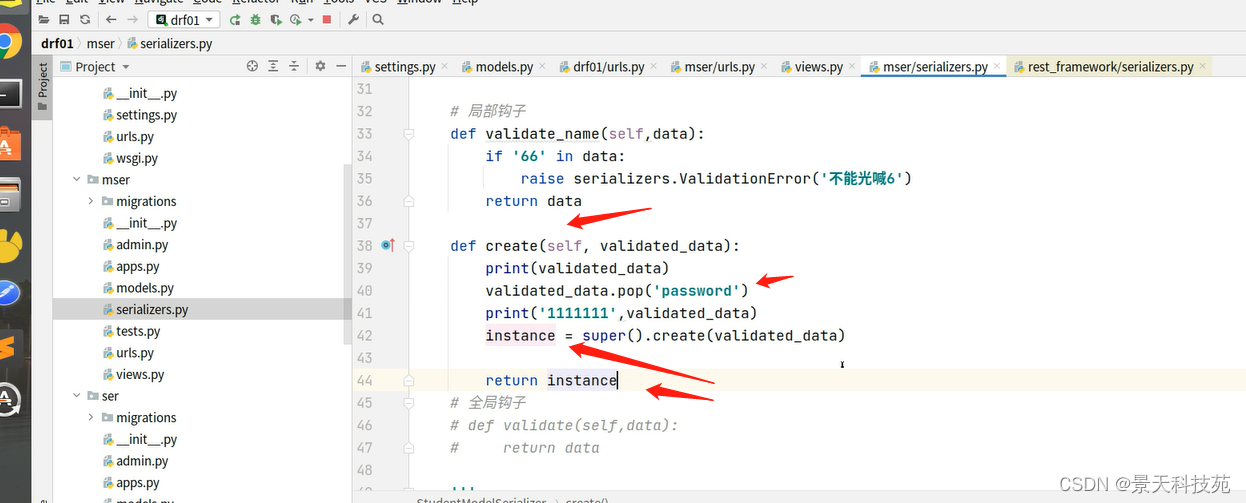
视图类
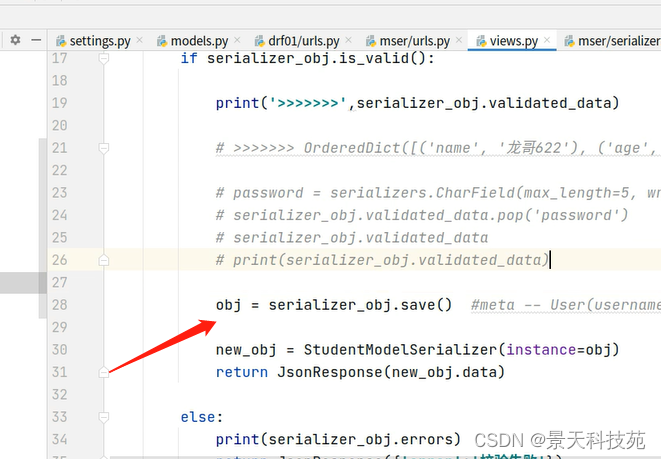
序列化器中重载父类的create方法
def create(self, validated_data):
print(validated_data)
validated_data.pop('password')
print('提出后的数据',validated_data)
#调用父类create方法保存
instance = super().create(validated_data)
return instance
视图类中保存数据
def post(self,request):
data = request.data
ser_obj = StudentModelSerializer(data=data)
if ser_obj.is_valid():
# obj = models.Student.objects.create(**ser_obj.validated_data)
#ModelSerializer自动创建了create,update方法,不用自己再创建。可以直接调用
obj = ser_obj.save()
# obj = ser_obj.validated_data
print('校验成功后的数据==》',obj)
new_obj = StudentModelSerializer(instance=obj)
print('序列化之后的数据',new_obj.data)
return JsonResponse(new_obj.data,safe=False,json_dumps_params={'ensure_ascii':False})
else:
#打印校验失败信息
print(ser_obj.errors)
#校验失败,返回错误信息,并修改状态码
return JsonResponse({'error':'校验失败'},status=400)
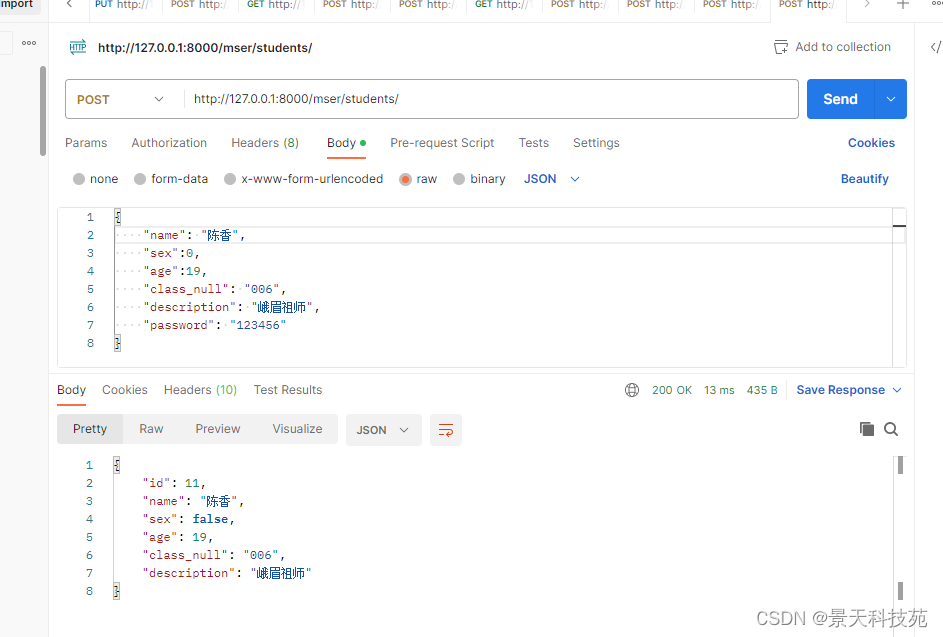
这才是最香的办法
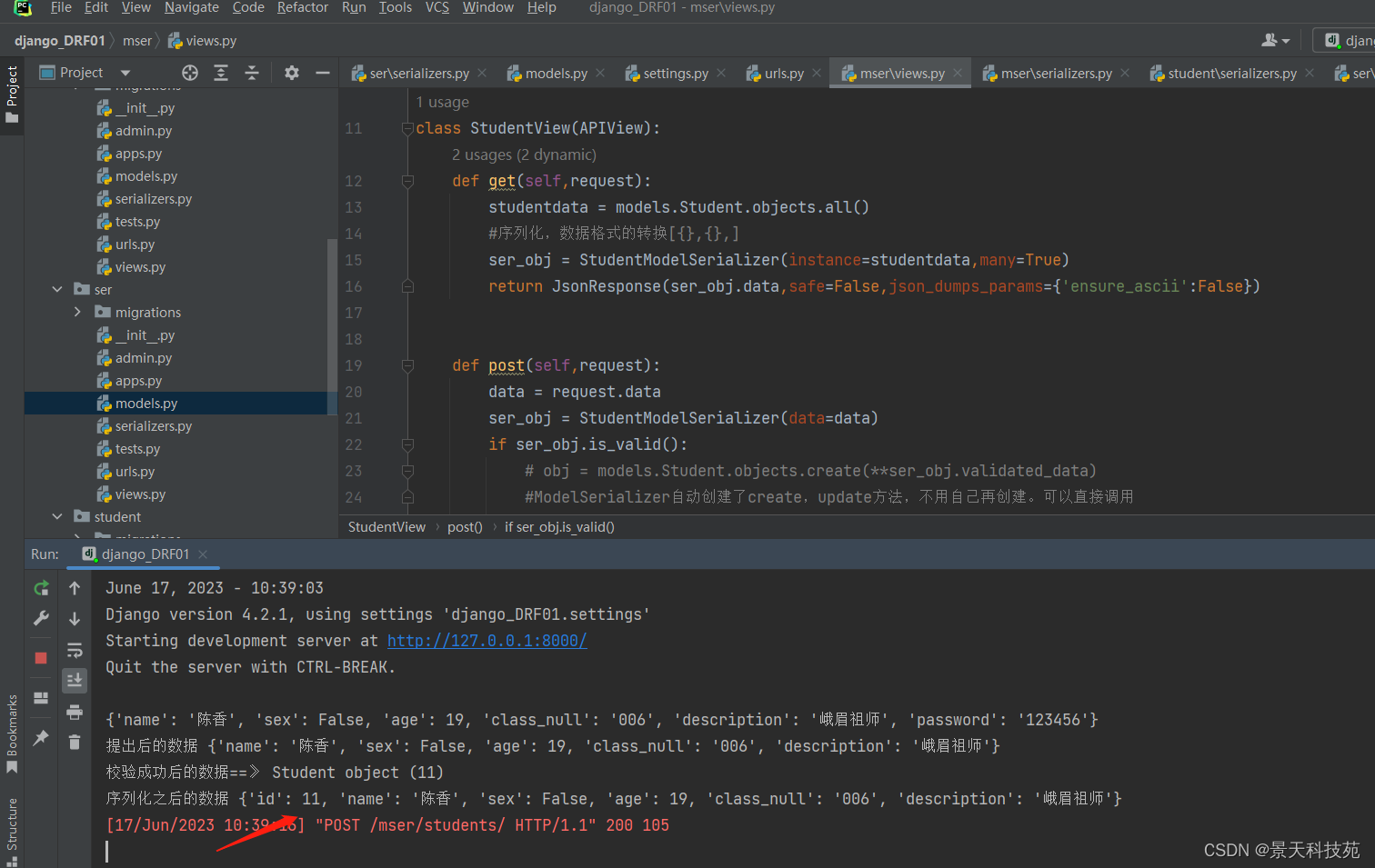
post请求,序列化器对象调用save方法保存数据时,ModelSerializer里面封装的有create和update方法
并且,自动将id设为read_only=True
#也可以重新声明一个create和update
def post(self,request):
data = request.data
ser_obj = StudentModelSerializer(data=data)
if ser_obj.is_valid():
# obj = models.Student.objects.create(**ser_obj.validated_data)
#ModelSerializer封装了create,update方法,不用自己再创建。可以直接调用。找到序列化器中的Meta中model指向的模型类,并将校验后的数据保存进去
obj = ser_obj.save()
new_obj = StudentModelSerializer(instance=obj)
return JsonResponse(new_obj.data,safe=False,json_dumps_params={'ensure_ascii':False})
else:
#打印校验失败信息
print(ser_obj.errors)
#校验失败,返回错误信息,并修改状态码
return JsonResponse({'error':'校验失败'},status=400)
以后写项目时,我们经常用ModelSerializer来做
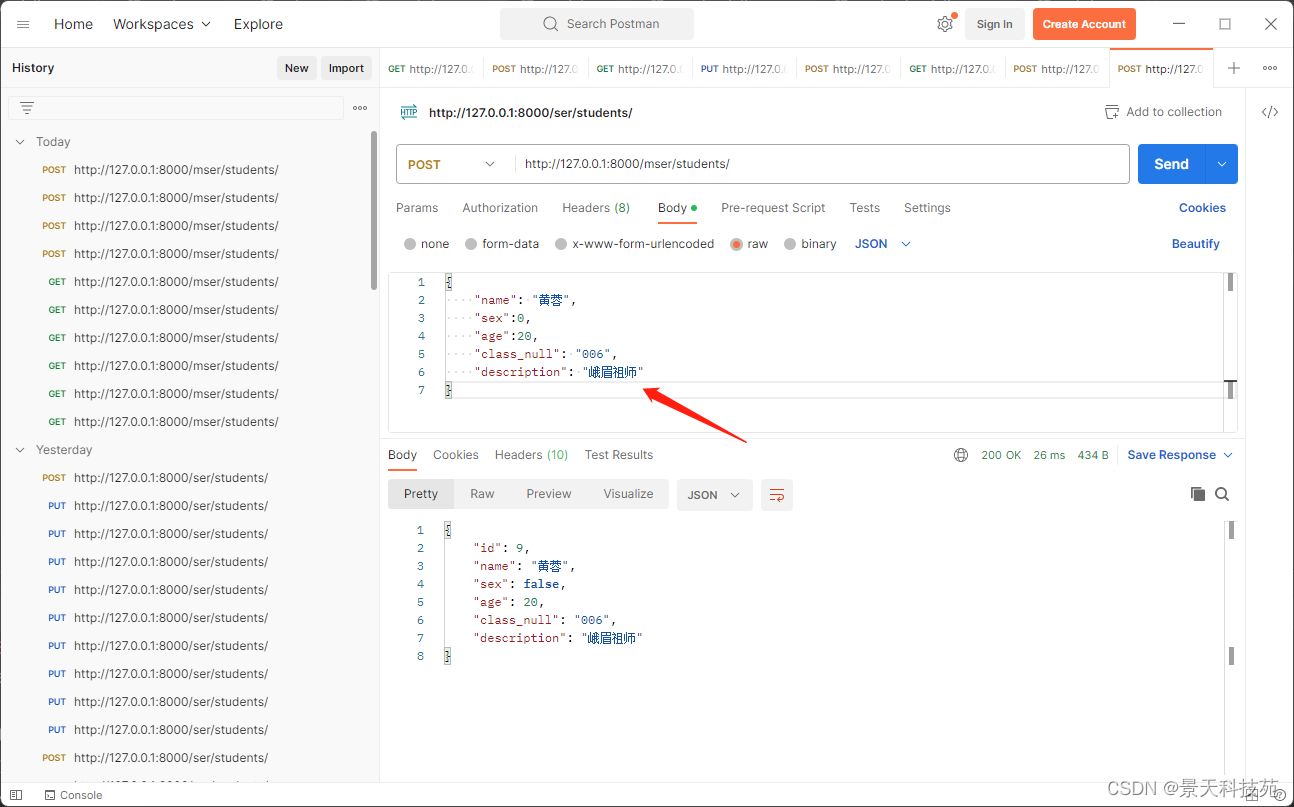
可见已保存到数据库
原文地址:https://blog.csdn.net/littlefun591/article/details/135985683
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65421.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!