1. 背景
对于很多数据团队来说,要满足实时需求并不容易。为什么?因为作流程(数据采集、预处理、分析、结果保存)涉及大量等待。等待数据发送到 ETL 工具,等待数据批量处理,等待数据加载到数据仓库中,甚至等待查询完成运行。
但开源领域有一个解决方案:Kafka、Flink和Druid一起使用时,可以创建一个实时数据架构,减少这些等待时间。在这篇文章中,我们将探讨如何利用Kafka、Flink、Druid实现广泛的实时数据系统架构。
2. 构建实时数据系统
什么是实时数据系统?想象一下任意一个后台系统或服务器端系统,它们利用数据来实时提供决策依据,这些数据包数据括警报、监控、仪表板、分析和个性化建议。
构建这种实时数据系统就是 Kafka-Flink-Druid (KFD) 架构的用武之地。

这种架构可以轻松构建实时数据应用系统,例如可观测性、物联网/遥测分析、安全检测/诊断以及高吞吐量和 QPS 下面向客户的洞察。
让我们看看它们如何一起使用。
3. 流数据管道:Kafka
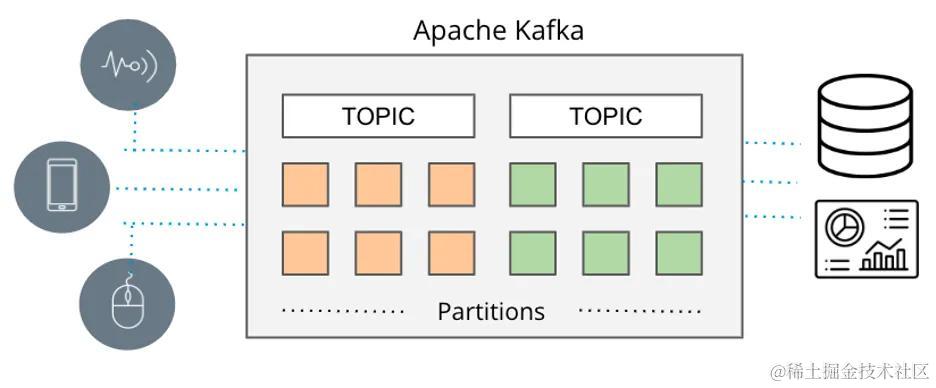
Kafka在过去几年中已成为流数据事实上的标准。在此之前,RabbitMQ、ActiveMQ和其他消息队列系统被用来提供各种消息传递模式,将数据从生产者分发到消费者,但存在规模限制。
目前,Kafka 已经无处不在。这是因为 Kafka 的架构远远超出了简单的消息传递范围。 Kafka 非常适合大规模的流数据传输,并具有容错性和数据一致性,以支持关键任务。
4. 流处理:Flink
随着 Kafka 提供实时数据,需要合适的消费者来实时利用其速度和规模。流行的选择之一是Flink。
为什么选择Flink?首先,Flink 凭借其统一的批处理和流处理引擎,在大规模处理连续数据流方面具有独特的优势。Flink 非常适合作为 Kafka 的流处理器,因为它无缝集成并保证每个事件仅处理一次,即使系统出现故障也是如此。
使用它很简单:连接到 Kafka的Topic,定义查询逻辑,然后连续发出结果。也就是“设置好后就可以忘记它”。这使得 Flink 对于立即处理流和可靠性至关重要的场景来说非常通用。
以下是 Flink 的一些常见使用场景:
- 丰富与转化
- 持续监控和警报
2.1 丰富与转化
如果流在使用之前需要进行数据操作(例如修改、重组数据),Flink 是对这些数据流进行更改的理想引擎。
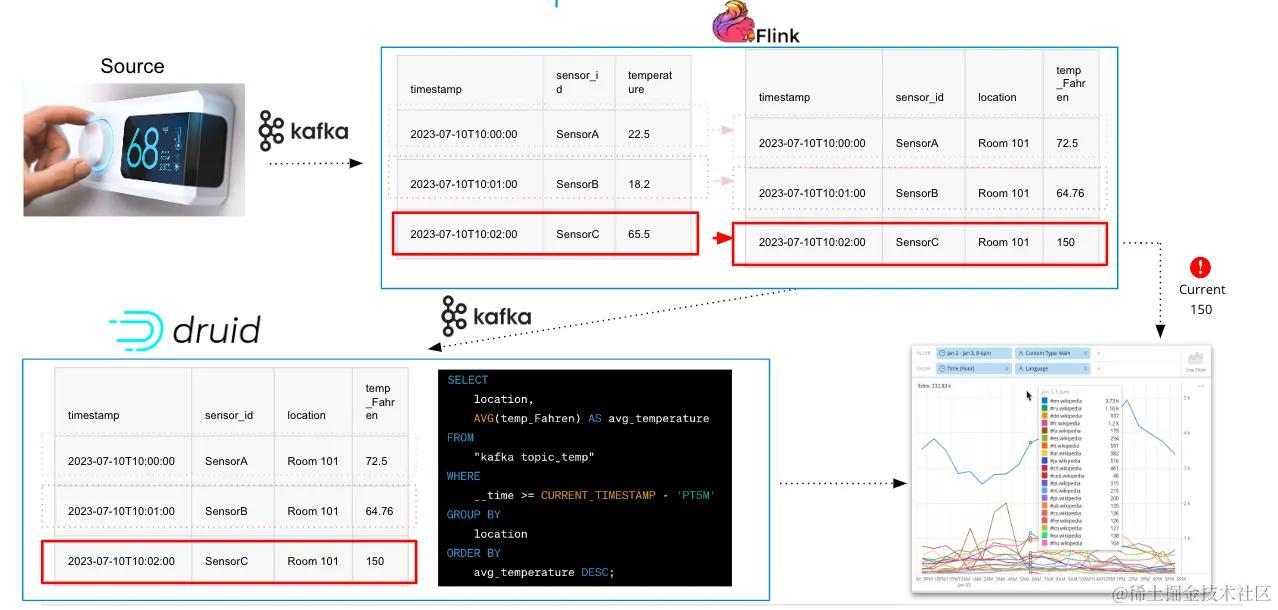
例如,假设我们有一个物联网的用例,用于处理智能建筑中的温度传感器。传入 Kafka 的每个数据流都具有以下 JSON 结构:
{
"sensor_id": "SensorA",
"temperature": 73.4,
"timestamp": "2023–07–10T10:00:00"
}
如果每个传感器 ID 需要与位置映射,并且温度需要以摄氏度为单位,Flink 可以将 JSON 结构更新为:
{
"sensor_id": "SensorA",
"location": "Room 101",
"temperature_Fahreinheit": 73.4,
"timestamp": "2023–07–10T10:00:00"
}
Flink 的优势在于它能够大规模实时处理大量 Kafka 流(每秒处理数百万个事件) 。此外,对数据的丰富与转化处理通常是一个无状态过程,其中每个数据记录都可以修改而无需维护持久状态,从而使其工作量最小且性能也很高。
2.2 持续监控和警报
Flink 的实时连续处理和容错能力的结合也使其成为实时检测和响应的理想解决方案。
当检测灵敏度非常高(例如亚秒级)并且采样率也很高时,Flink 的连续处理非常适合作为数据服务层,用于监视条件并相应地触发警报和操作。
Flink 具有警报功能的一个优点是它可以支持无状态和有状态警报。阈值或事件触发器(例如“当温度达到 X 时发送通知”)很简单,但并不总是足够智能。因此,在警报需要由需要记住状态的复杂模式驱动的用例中,甚至需要在连续的数据流中聚合指标(例如总和、平均值、最小值、最大值、计数等),Flink 可以监控并记录数据。更新状态以识别偏差和异常。
需要考虑的一点是,使用 Flink 进行监控和警报需要持续的运算,因此很消耗 CPU,在使用时最好评估是否需要持续运算。
5. 实时分析:Druid
Druid与Kafka和Flink一起成为支持实时分析的流消费者。虽然它是一个用于分析的数据库,但它的用途与其他数据库和数据仓库有很大不同。
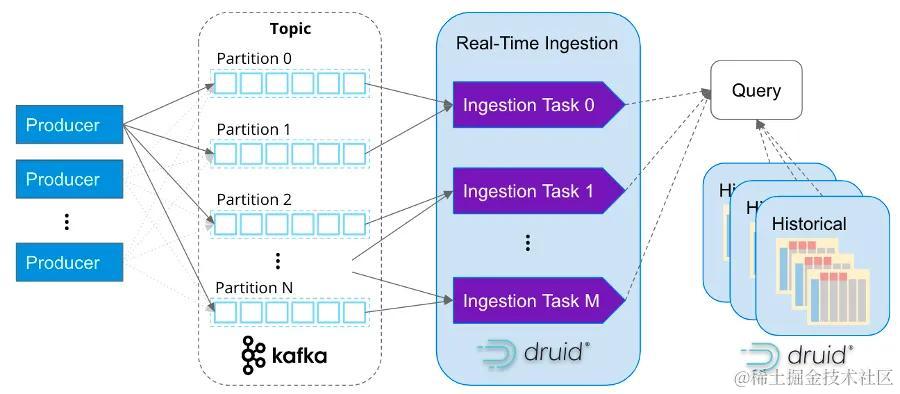
首先,Druid 它也是流原生的。事实上,Kafka 不需要连接器,因为它直接连接到 Kafka的Topic,并且支持一次性语义。Druid 还设计用于快速大规模获取流数据,并在事件到达时立即查询内存中的事件。
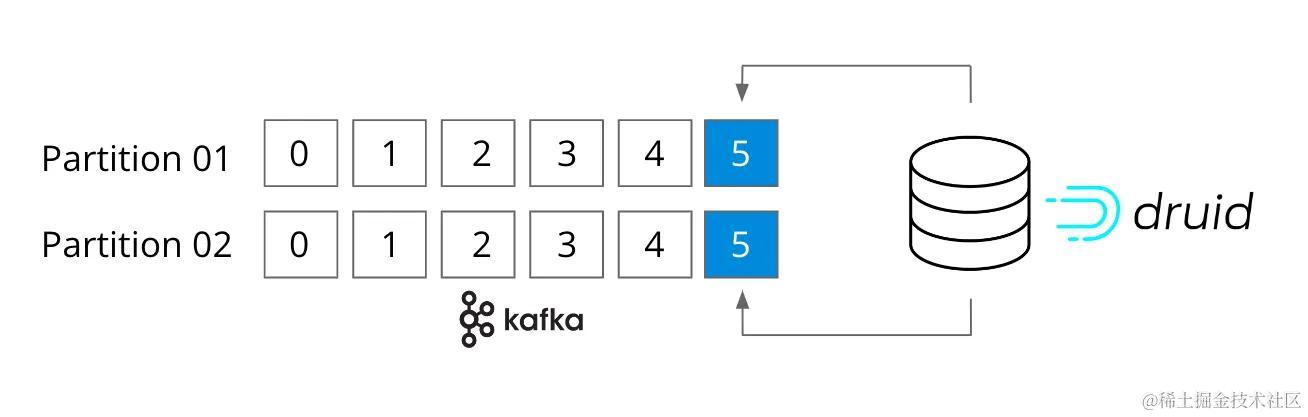
在查询方面,Druid 是一个高性能、实时分析数据库,可在大规模和负载下提供亚秒级查询。如果用例对性能敏感并且需要处理TBS具有PBS高查询量的数据(例如聚合、过滤器、GroupBy、复杂联接等),那么 Druid 是一个理想的数据库,因为它的查询速度足够快,并且可以轻松地做水平扩展。
这就是为什么 Druid 被称为实时分析数据库:它是为实时数据满足实时查询而设计的。
以下是 Druid 的优点:
- 高度互动的查询
- 实时历史数据
5.1 高度互动的查询
使用 Druid 来支持数据密集型程序,涉及可观察性、安全性、产品分析、物联网/遥测、制造操作等。由 Druid 具有以下特点:
- 大规模性能: 需要对大型数据集进行丰富分析查询的亚秒级读取性能而无需预先计算的应用程序。即使应用程序的用户通过 TB-PB 规模的大量随机查询进行任意分组、过滤和切片/切块,Druid 也具有高性能。
- 高查询量: 分析查询 QPS 要求高的应用程序。
- 时间序列数据: 提供时间维度数据洞察的应用程序(Druid 的优势但不是限制)。由于其时间分区和数据格式,Druid 可以非常快速地大规模处理时间序列数据。这使得基于时间的
WHERE过滤器变得异常快。
这些应用程序要么具有非常交互式的数据可视化的界面,在动态更改查询方面具有很大的灵活性(因为 Druid 非常快),要么在许多情况下,它们利用 Druid 的 API 来大规模提高查询速度。在Druid的应用案例中,可支持每秒500万个事件流入Kafka和Druid,并使用Druid支持350 QPS。
Druid的使用不仅限于流数据,也可以提供实时数据与历史数据相结合的交互式数据体验,以获得更丰富的上下文。
虽然 Flink 非常擅长回答“现在正在发生什么”,但 Druid 可以回答“现在正在发生什么,与之前相比如何,以及哪些因素影响了这一结果”。这些问题加在一起非常强大,因为它们可以消除误报、帮助发现新趋势。
例如,假设我们正在构建一个应用程序来监视安全登录是否存在可疑行为。我们可能想在 5 分钟窗口内设置一个阈值:即尝试登录的行为发生的次数。这对于 Flink 来说很容易。但使用 Druid,当前的登录尝试还可以与历史数据相关联,以识别过去没有安全漏洞的类似登录峰值。
因此,当应用程序需要针对快速变化的事件提供大量分析(例如当前状态、各种聚合、分组、时间窗口、复杂连接等)时,还需要提供历史背景并通过高度集成的方式探索该数据集。这种场景非常时候Druid。
Flink 和 Druid 的决策清单
Flink 和 Druid 都是为流数据而构建的。虽然它们有一些高级相似之处——都在内存中,都可以扩展,都可以并行化——但它们的架构实际上是为完全不同的用例构建的,这里列出一份简单的决策清单,以便选择Druid还是Flink:
- 是否需要在流数据上实时转换或连接数据? 选择Flink
- 您需要同时支持许多不同的查询吗? 选择Druid
- 指标是否需要不断更新或汇总? 选择Flink
- 分析是否更复杂,是否需要历史数据进行比较? 选择Druid
- 是否在选择程序可视化的方案? Flink + Druid
大多数情况下,答案不是 Druid 或 Flink,而是 Druid 和 Flink。每一个都提供了技术特性,使它们非常适合支持广泛的实时数据应用程序。
结论
企业对数据团队的实时性要求越来越高。这意味着需要端到端地重新考虑数据工作流程。这就是为什么许多公司转向 Kafka-Flink-Druid 作为构建实时数据应用程序的事实上的开源数据架构。他们是完美的三人组。
原文地址:https://blog.csdn.net/guohuang/article/details/134493507
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6557.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!