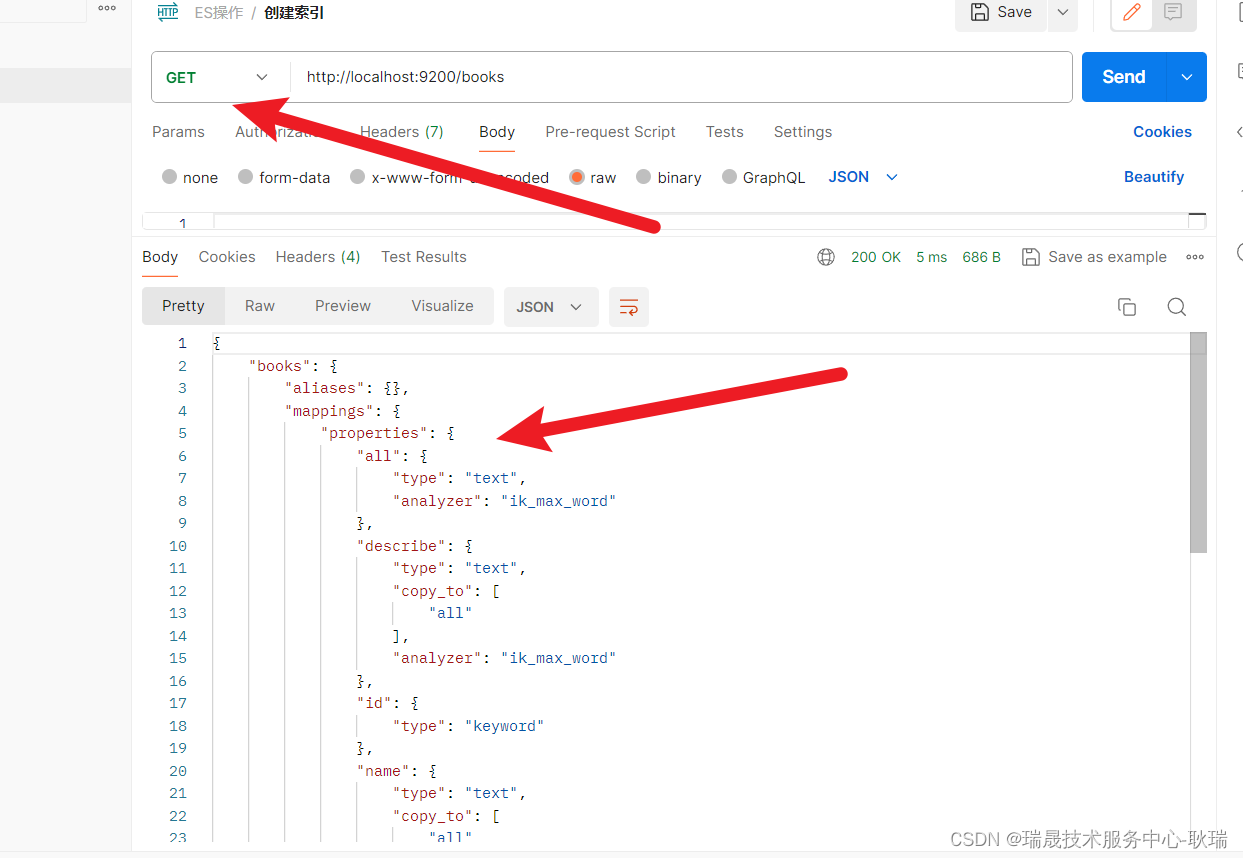
本文介绍: 但我们的name和describe 都设置了 copy_to 指向了 字段 all 意思是 它们拿到的数据 都会往all字段中备份一个 但是 copy_to给的数据确实是不真实存在的,主要是用于查询的。这个id的type 并不是java的类型 而是 ES的类型 keyword 表示 可以根据id进行查询。我们可以看到 mappings中的内容就是我们设置的了。我们数据结构的配置 都是在 mappings中的。然后 我们就可以设置它的其他属性了。然后 我们来说 IK分词器 怎么用。
上文 Elasticsearch(ES) 下载添加IK分词器 带大家 下载 并使用了 IK 分词器
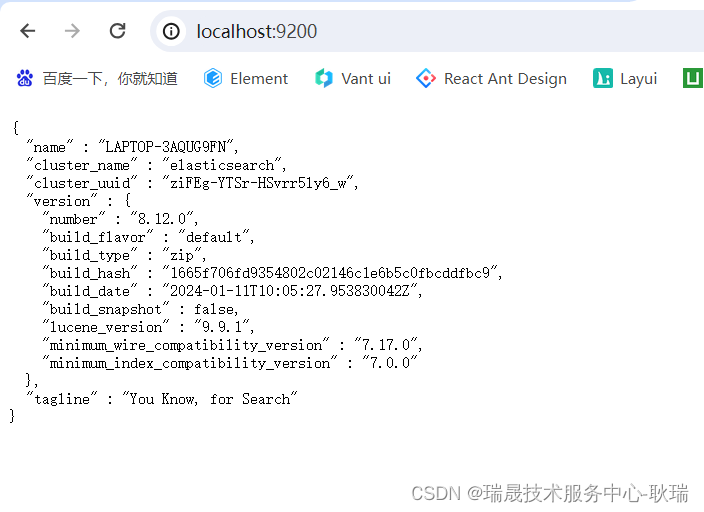
我们先启动 ES 服务
然后 我们来说 IK分词器 怎么用
设置分词器 我们还是要发put请求 创建索引时 通过参数设置
这里 我们put请求 类型要换成 json的
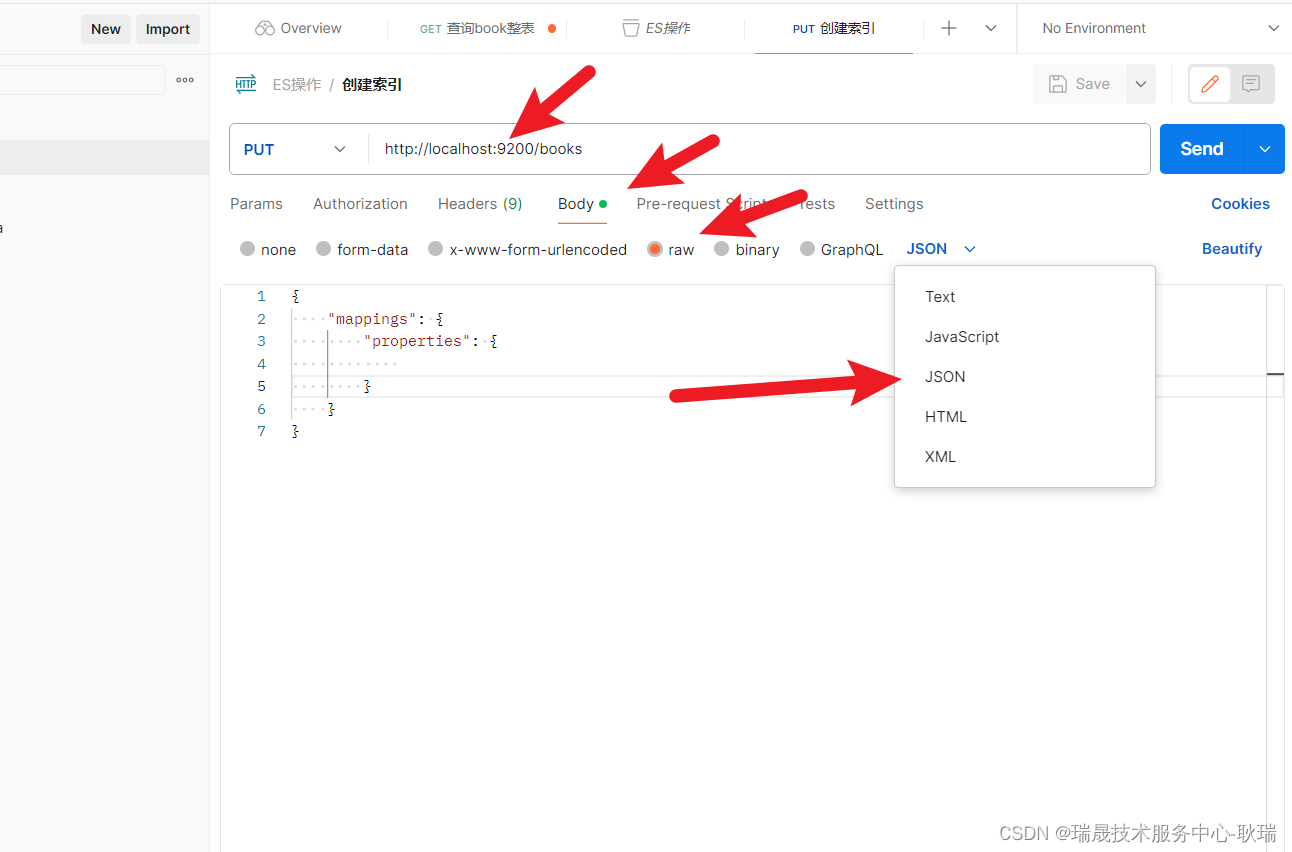
我们先加一个这样的模板
我们数据结构的配置 都是在 mappings中的
properties 是指 装在的所有属性描述
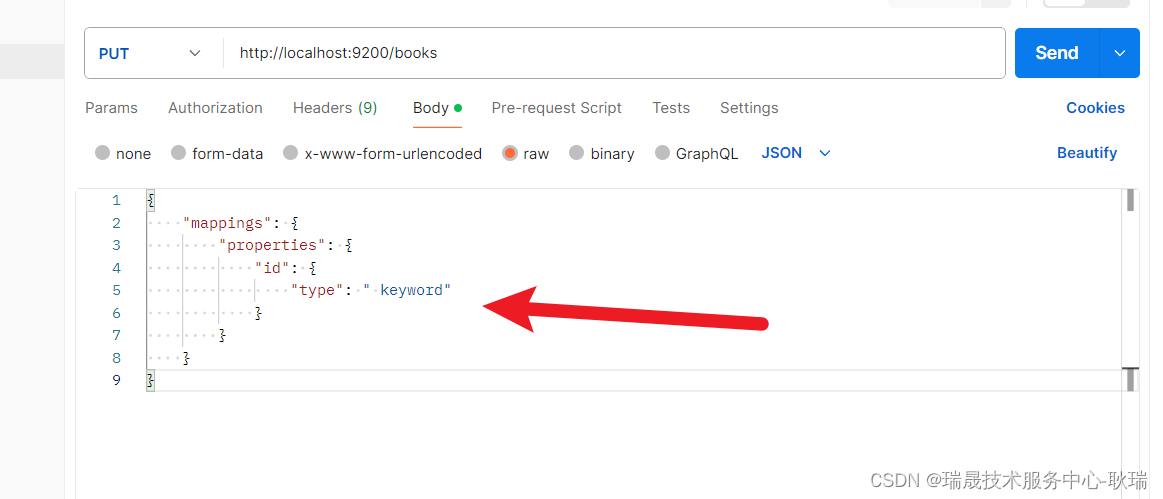
然后 我们来写第一个属性 id
这个id的type 并不是java的类型 而是 ES的类型 keyword 表示 可以根据id进行查询
如果 你不希望id参与查询
我们下面加个 index 给false 就好了
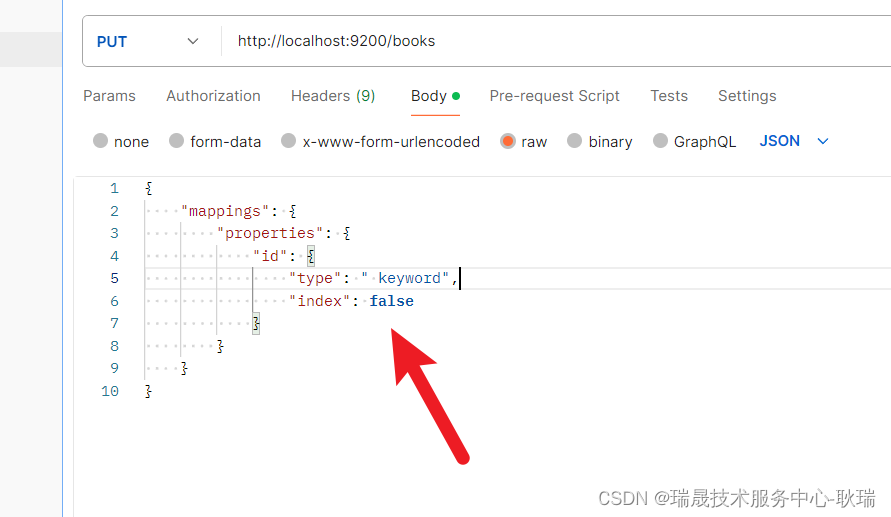
但 我们这明显是要参与查询的 将index 属性去掉
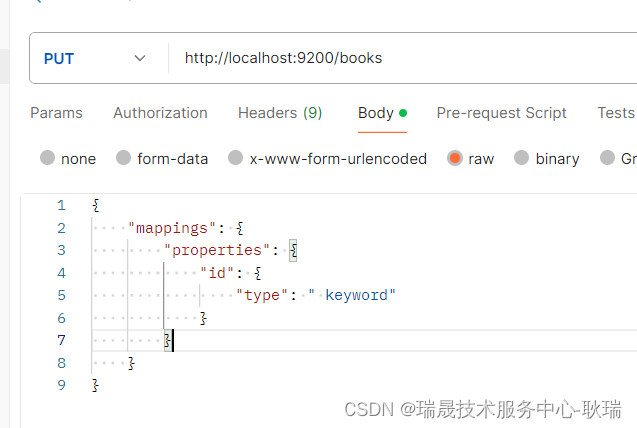
然后 我们就可以设置它的其他属性了
这里 我们设置 name和describe type类型都是 text 表示这是一段文本信息
然后 analyzer 表示分词器 ik分词器的地址就是 ik_max_word
然后 又来了个type字段
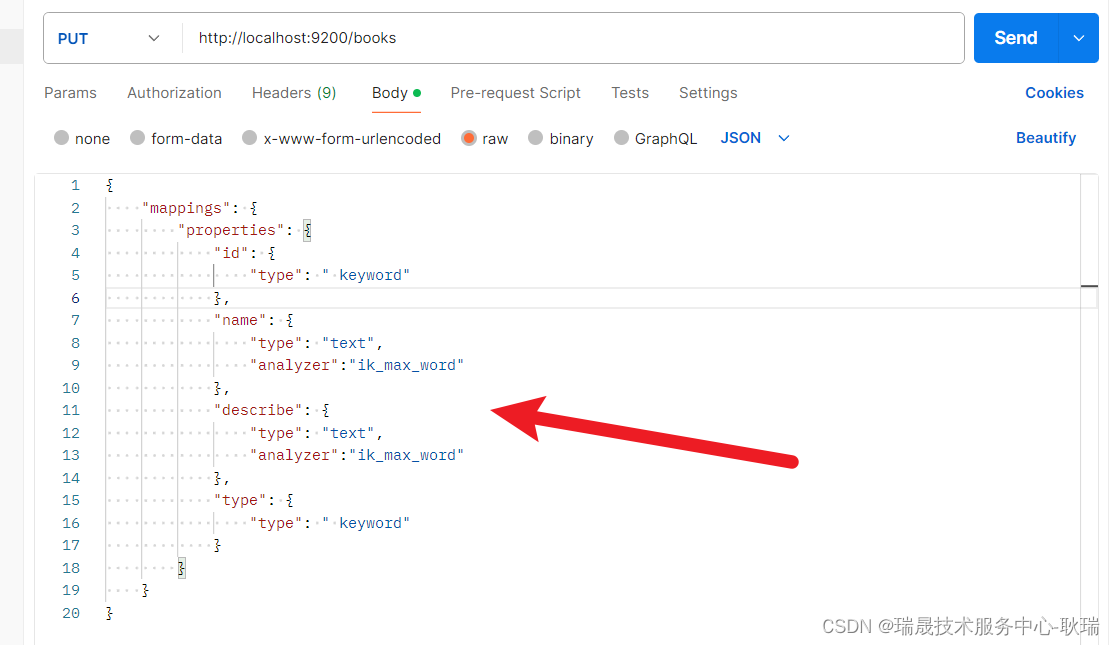
最后 还有一个东西 要设置
例如 我们输入一个 springboot 那么 系统就蒙了 你是要在 name还是analyzer 中去找这个关键字?
但是 我们希望的是 只要有任何一个包含 就能查出来
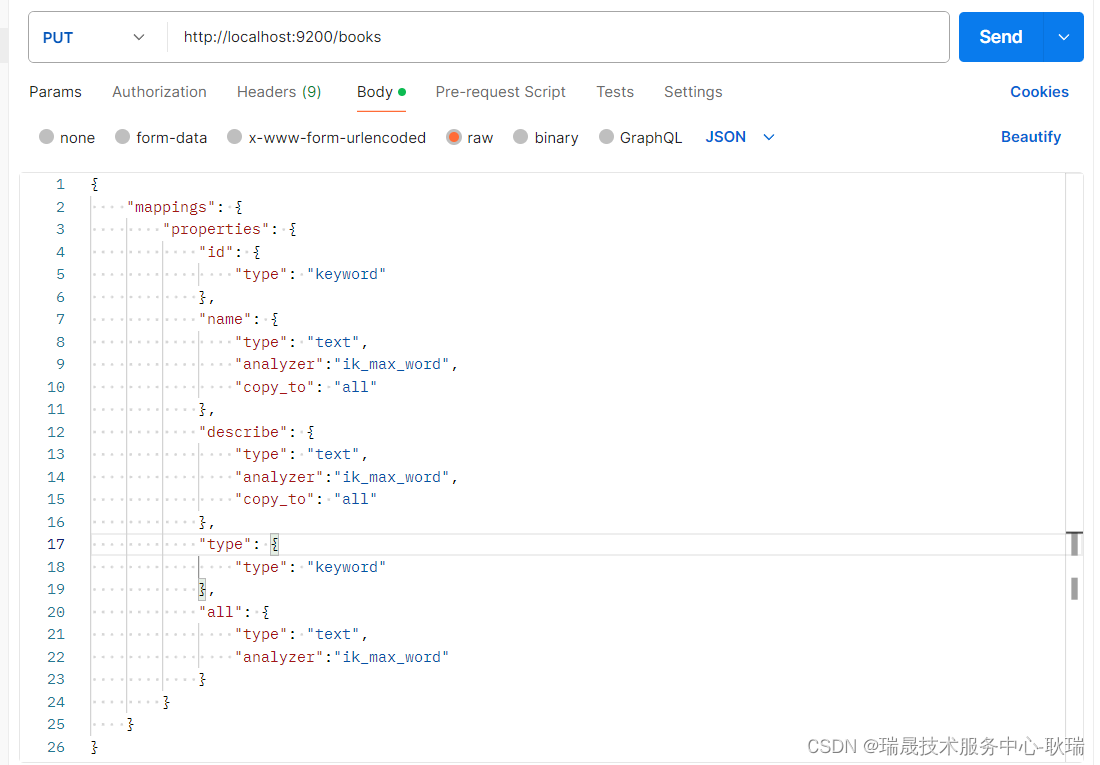
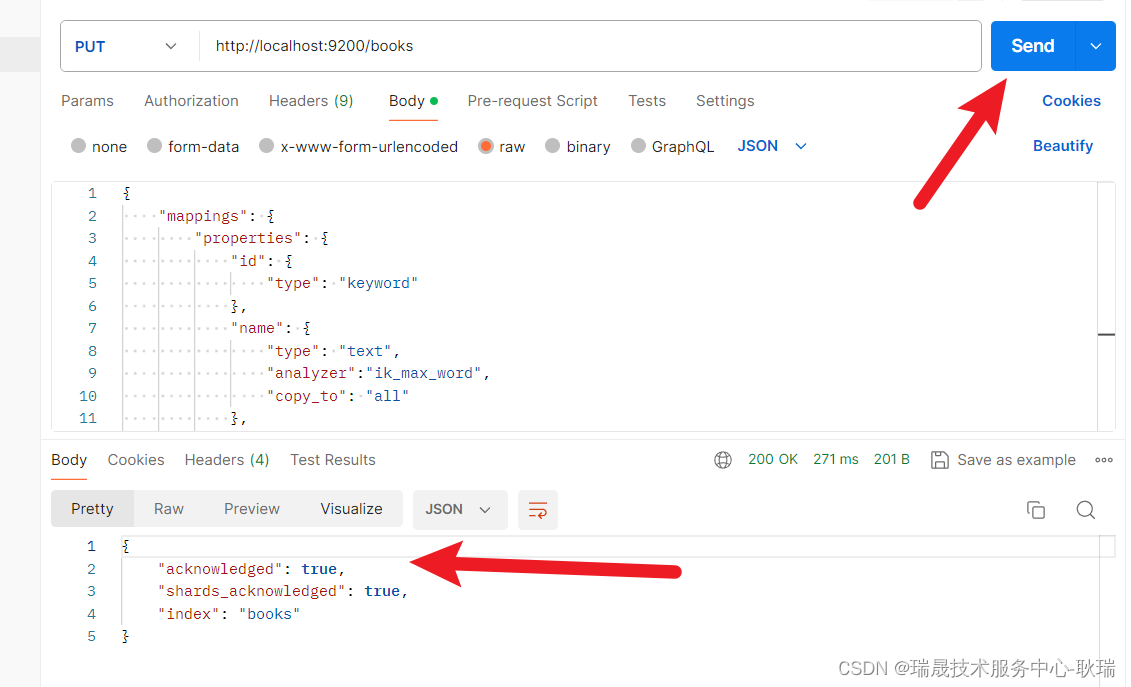
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


![ES证书过期,错误信息: current license is non-compliant for [security]](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)
