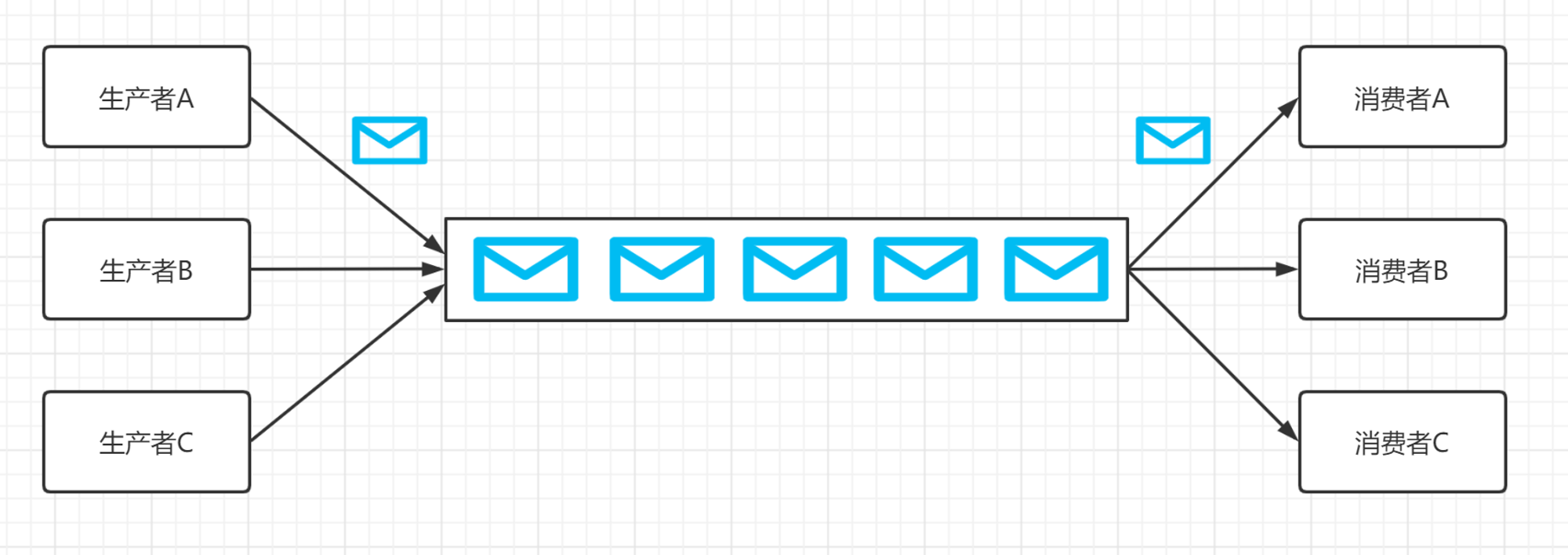
消息队列Kafka系统架构
Q:什么是Kafka?
A:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息引擎、消息队列服务,它可以处理消费者规模的网站中的所有动作流数据。
Q:Kafka有哪些特性?
A:作为一种高吞吐量的分布式发布订阅消息系统,有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量 :即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
支持通过Kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载
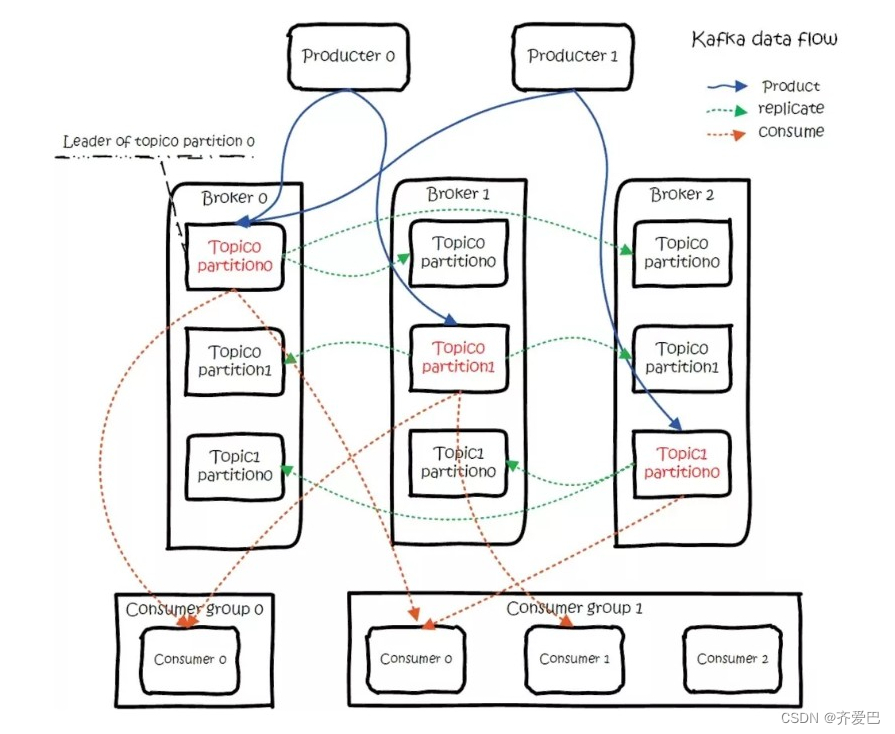
Q:kafka的总体数据流是什么样的?
A:
Q:kafka的使用场景有些?
消息队列Kafka版具有丰富的应用生态,主要包括三个方面:
大数据领域:如网站行为分析、日志聚合、应用监控、流式数据处理、在线和离线数据分析等领域。
数据集成:将消息导入MaxCompute、OSS、RDS、Hadoop、HBase等离线数据仓库。
流计算集成:与StreamCompute、E-MapReduce、Spark、Storm等流计算引擎集成。

Q:主要功能有哪些?
A:根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能:发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因;以容错的方式记录消息流,kafka以文件的方式来存储消息流;可以再消息发布的时候进行处理。
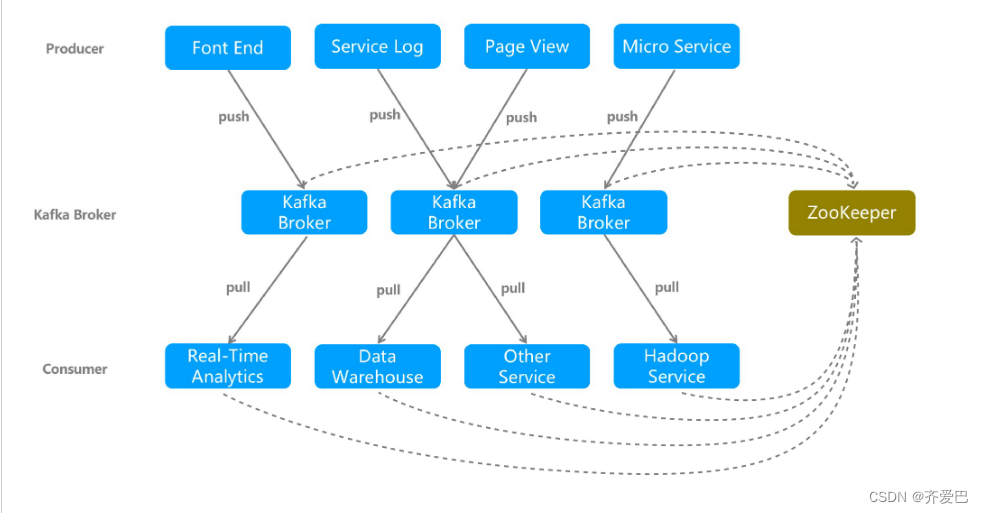
消息队列Kafka系统架构
一个典型的消息队列Kafka版集群包括四个部分:
Producer
通过push模式向消息队列Kafka版的Kafka Broker发送消息。发送的消息可以是网站的页面访问、服务器日志,也可以是CPU和内存相关的系统资源信息。
Kafka Broker
用于存储消息的服务器。Kafka Broker支持水平扩展。Kafka Broker节点的数量越多,Kafka集群的吞吐率越高。
Consumer Group
通过pull模式从消息队列Kafka版 Broker订阅并消费消息。
Zookeeper
管理集群的配置、选举leader分区,并且在Consumer Group发生变化时,进行负载均衡。
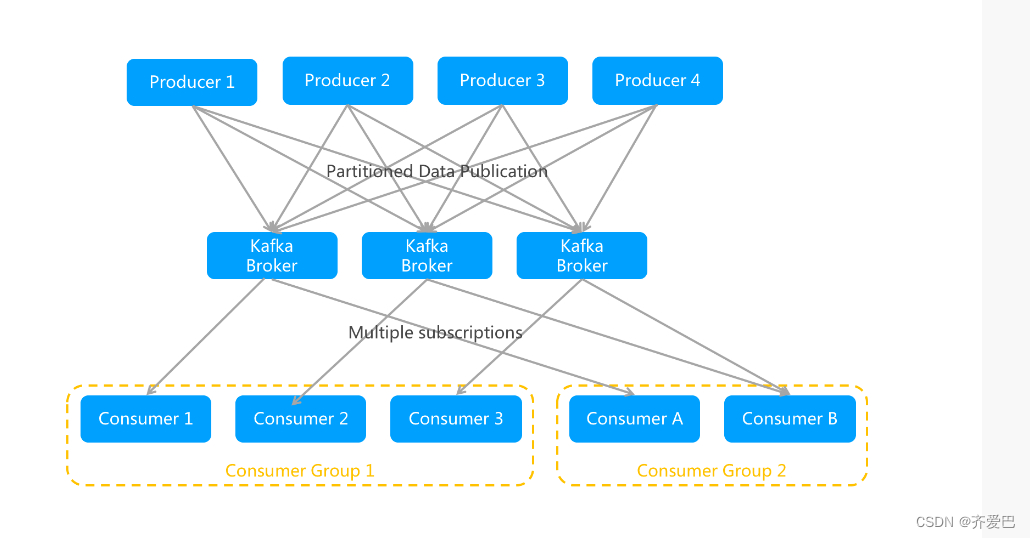
消息队列Kafka版的发布/订阅模型
消息队列Kafka版采用发布/订阅模型:
Consumer Group和Topic的对应关系是N : N,即一个Consumer Group可以同时订阅多个Topic,一个Topic也可以被多个Consumer Group同时订阅。
某个Topic的一条消息可以被多个Consumer Group同时订阅,但只能被同一个Consumer Group内的任意一个Consumer消费。
本文主要介绍消息队列Kafka版的经典应用场景。
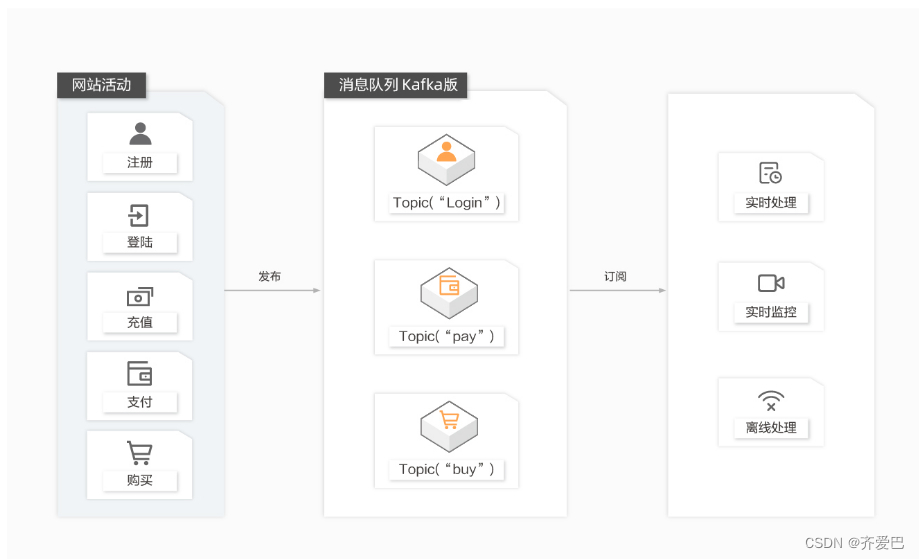
网站活动跟踪
成功的网站运营都会非常关注站点的用户行为并进行分析。通过消息队列Kafka版,您可以实时收集网站活动数据(包括用户浏览页面、搜索及其他行为等),并通过“发布/订阅”模型实现:
根据不同的业务数据类型,将消息发布到不同的Topic。
通过订阅消息的实时投递,将消息流用于实时监控与业务分析或者加载到Hadoop、ODPS等离线数据仓库系统进行离线处理与业务报告。
能够实现:
高吞吐:网站所有用户产生的行为信息极为庞大,需要非常高的吞吐量来支持。
弹性扩容:网站活动导致行为数据激增,云平台可以快速按需扩容。
大数据分析:可对接Storm/Spark实时流计算引擎,亦可对接Hadoop/ODPS等离线数据仓库系统。
日志聚合
公司的不同平台每天都会产生大量的日志(一般为流式数据,如搜索引擎pv、查询等),相较于日志为中心的系统,例如Scribe或者Flume来说,消息队列Kafka版在提供同样高效的性能时,可以实现更强的数据持久化以及更低的端到端响应时间。消息队列Kafka版的这种特性决定它非常适合作为日志收集中心:
消息队列Kafka版忽略掉文件的细节,可以将多台主机或应用的日志数据抽象成一个个日志或事件的消息流,异步发送到消息队列Kafka版集群,从而做到非常低的RT时间。
消息队列Kafka版客户端可批量提交消息和压缩消息,对生产者而言几乎感觉不到性能的开支。
消费者可以使用Hadoop、ODPS等离线仓库存储和Strom、Spark等实时在线分析系统对日志进行统计分析。
能够实现:
应用与分析解耦:构建应用系统和分析系统的桥梁,并将它们之间的关联解耦。
高可扩展性:具有非常高的可扩展性,即当数据量增加时可通过增加节点快速水平扩展。
在线/离线分析系统:支持实时在线分析系统和类似于Hadoop的离线分析系统。

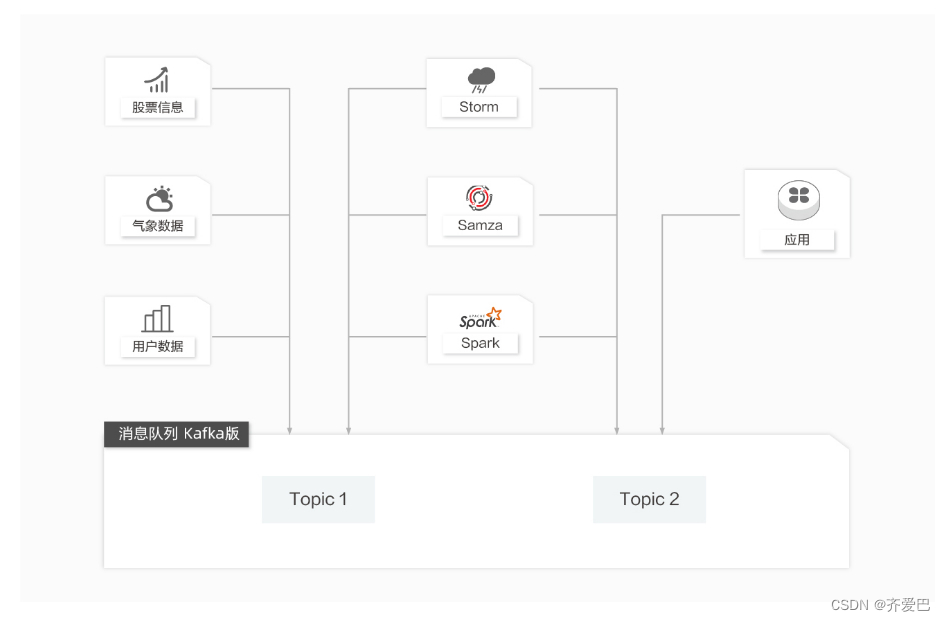
流计算处理
在很多领域,如股市走向分析、气象数据测控、网站用户行为分析,由于数据产生快、实时性强且量大,您很难统一采集这些数据并将其入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。
与传统架构不同,消息队列Kafka版以及Storm/Samza/Spark等流计算引擎的出现,就是为了更好地解决这类数据在处理过程中遇到的问题,流计算模型能实现在数据流动的过程中对数据进行实时地捕捉和处理,并根据业务需求进行计算分析,最终把结果保存或者分发给需要的组件。
能够实现:
流动的数据:构建应用系统和分析系统的桥梁,并将它们之间的关联解耦。
高可扩展性:由于数据产生非常快且数据量大,需要非常高的可扩展性。
流计算引擎:可对接开源Storm/Samza/Spark以及EMR、Blink、StreamCompute等产品。
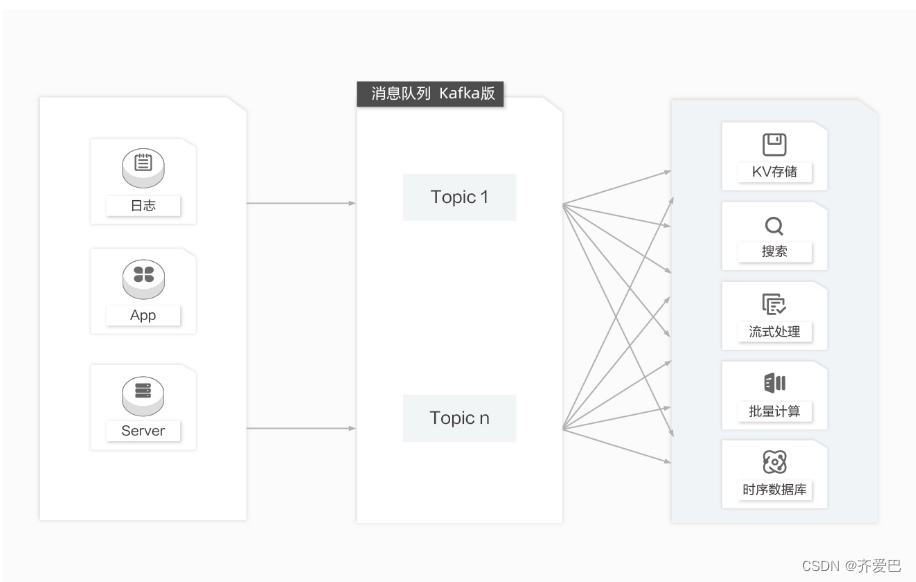
数据中转枢纽
近10多年来,诸如KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生。这些系统是因为单一的目标而产生,也因其简单性使得在商业硬件上构建分布式系统变得更加容易且性价比更高。
通常,同一份数据集需要被注入到多个专用系统内。例如,当应用日志用于离线日志分析,搜索单个日志记录同样不可或缺,而构建各自独立的工作流来采集每种类型的数据再导入到各自的专用系统显然不切实际,利用消息队列Kafka版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
能够实现:
高容量存储:能在商业硬件上存储高容量的数据,实现可横向扩展的分布式系统。
一对多消费模型:“发布/订阅”模型,支持同份数据集能同时被消费多次。
同时支持实时和批处理:支持本地数据持久化和Page Cache,在无性能损耗的情况下能同时传送消息到实时和批处理的消费者。
原文地址:https://blog.csdn.net/m0_46517444/article/details/135946659
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65755.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!