本文介绍: Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
1. 使用入口
- DistributedOptimizer类定义在
megatron/optimizer/distrib_optimizer.py文件中。创建的入口是在megatron/optimizer/__init__.py文件中的get_megatron_optimizer函数中。根据传入的args.use_distributed_optimizer参数来判断是用DistributedOptimizer还是Float16OptimizerWithFloat16Params。
def get_megatron_optimizer(model,
no_weight_decay_cond=None,
scale_lr_cond=None,
lr_mult=1.0):
...
# Megatron optimizer.
opt_ty = DistributedOptimizer
if args.use_distributed_optimizer else
Float16OptimizerWithFloat16Params
return opt_ty(optimizer,
args.clip_grad,
args.log_num_zeros_in_grad,
params_have_main_grad,
args.use_contiguous_buffers_in_local_ddp,
args.fp16,
args.bf16,
args.params_dtype,
grad_scaler,
model)
- 相关的Optimizer的使用参考【Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1】
2. 初始化init源码说明
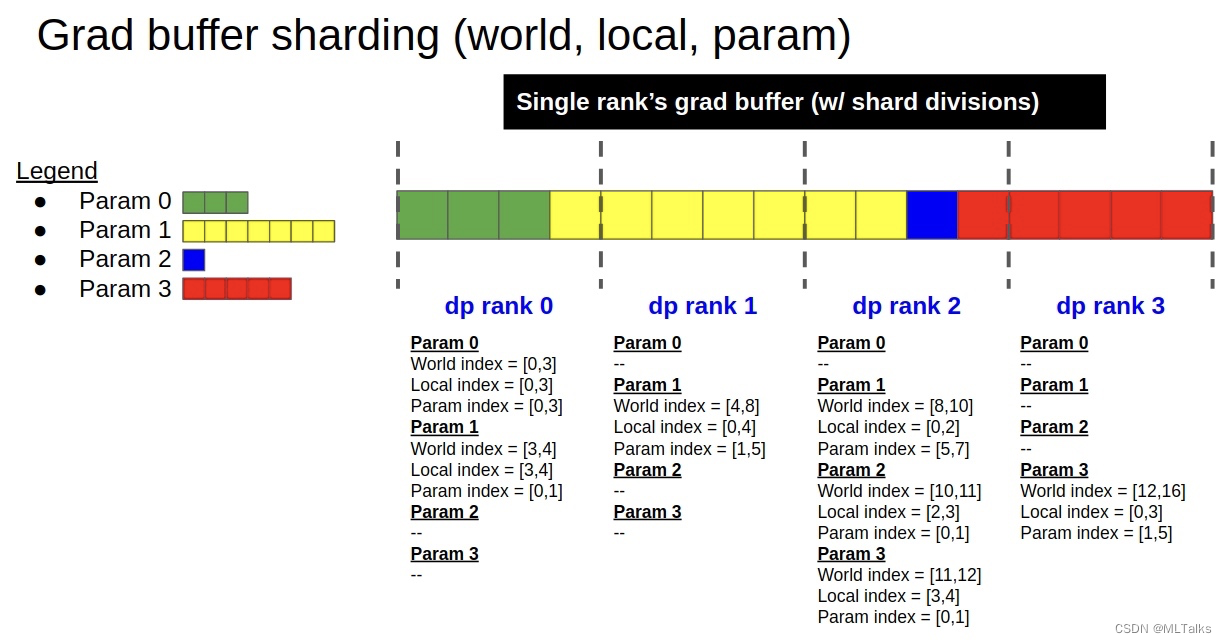
- 初始化的过程很大程度对应的上图grad buffer分片的实现,对应init函数如下:
def __init__(self, optimizer, clip_grad, log_num_zeros_in_grad,
params_have_main_grad, use_contiguous_buffers_in_local_ddp,
fp16, bf16, params_dtype, grad_scaler, models):
- init时会通过
build_model_gbuf_range_map函数先创建grad buffer的范围映射,也就是对应图中的world_index/local_index/param_index三个。这里的self.models是一个list类型,对于使用了interleave流水线方式的训练来说,这里的self.models中会保存多份model, 其余情况list中只有一个元素。
# Model grad buffer ranges.
self.model_gbuf_ranges = []
for model_index, model in enumerate(self.models):
self.model_gbuf_ranges.append(self.build_model_gbuf_range_map(model))
build_model_gbuf_range_map会依次按grad buffer中类型来进行range的初始化build_model_gbuf_range。这里定义了一个单独的Range类。
@classmethod
def build_model_gbuf_range_map(cls, model):
"""
Create param-to-grad-buffer mappings, for grad buffer data types
within a specific virtual model.
"""
return {
dtype : cls.build_model_gbuf_range(model, dtype)
for dtype in model._grad_buffers
}
class Range:
"""
A range represents a start and end points for indexing a shard
from a full tensor.
"""
def __init__(self, start, end):
self.start = start
self.end = end
self.size = end - start
def normalize(self, start = 0):
return Range(start, start + self.size)
def __str__(self):
return "%d,%d [%d]" % (self.start, self.end, self.size)
def __len__(self):
return self.end - self.start
build_model_gbuf_range初始化range的流程如下:- 获取DP的rank,计算单个Grad buffer切片的大小
- 保存当前rank的world range和local range, 分别对应world index和local index
- 计算param的range范围,对应param index
- 返回当前rank的相关range范围
@classmethod
def build_model_gbuf_range(cls, model, dtype):
# 获取DP的rank
data_parallel_rank = mpu.get_data_parallel_rank()
data_parallel_world_size = mpu.get_data_parallel_world_size()
# 计算单个Grad buffer切片的大小
grad_buffer = model._grad_buffers[dtype]
gbuf_size = grad_buffer.numel
max_gbuf_range_size = int(math.ceil(gbuf_size / data_parallel_world_size))
# 跟据DDP的rank总数,分别计算每个rank对应的全局range
gbuf_world_all_ranges = []
for r in range(data_parallel_world_size):
gbuf_world_start = r * max_gbuf_range_size
gbuf_world_end = min(gbuf_size, gbuf_world_start+max_gbuf_range_size)
gbuf_world_range = Range(gbuf_world_start, gbuf_world_end)
gbuf_world_all_ranges.append(gbuf_world_range)
# 保存当前rank的world range和local range
# Local DP's ranges.
gbuf_world_range = gbuf_world_all_ranges[data_parallel_rank]
gbuf_local_range = gbuf_world_range.normalize()
# 计算param的range范围
param_range_map = cls.build_model_gbuf_param_range_map(model,
dtype,
gbuf_world_range)
# Group into dict.
data = {
"local" : gbuf_local_range,
"world" : gbuf_world_range,
"world_all" : gbuf_world_all_ranges,
"param_map" : param_range_map,
"max_range_size" : max_gbuf_range_size,
}
return data
- 接着会根据当前rank相关的Range内容
self.model_gbuf_ranges调用build_model_param_gbuf_map函数,主要作用是创建model_gbuf_ranges的逆映射,保存param->(modex_index, type)的映射。
class DistributedOptimizer(MixedPrecisionOptimizer):
def __init__(...):
...
self.model_param_gbuf_map =
self.build_model_param_gbuf_map(self.model_gbuf_ranges)
...
def build_model_param_gbuf_map(cls, model_gbuf_ranges):
"""
Create a reverse of the model_gbuf_ranges, for referencing in
opposite direction.
"""
param_gbuf_map = {}
for model_index, model_gbuf_range_map in enumerate(model_gbuf_ranges):
for dtype, gbuf_range_map in model_gbuf_range_map.items():
for param, param_range_map in gbuf_range_map["param_map"].items():
param_gbuf_map[param] = (model_index, dtype)
return param_gbuf_map
- 在
self.build_model_param_gbuf_map之后是初始化Optimizer对应的local group range,Optimizer原本有param_groups包括多个参数组,这里build_optimizer_group_ranges为了创建param参数到group_index的map映射,也就是<model_parameter:group_index>;self.build_model_param_gbuf_map最后对每个group_range中增加新的orig_group和orig_group_idx两个key,原来group_range初始化的时候只有params一个key
class DistributedOptimizer(MixedPrecisionOptimizer):
def __init__(...):
...
# Optimizer ranges.
self.model_param_group_index_map, self.opt_group_ranges =
self.build_optimizer_group_ranges(self.optimizer.param_groups,
self.model_gbuf_ranges)
...
def build_optimizer_group_ranges(cls, param_groups, model_gbuf_ranges):
# 获取param_groups中组的个数
num_groups = len(param_groups)
# 创建全局的参数到group_index的map映射,也就是<model_parameter:group_index>
world_param_group_map = {}
for group_index, group in enumerate(param_groups):
for param in group["params"]:
assert param.requires_grad
world_param_group_map[param] = group_index
# 创建当前rank的local_param_group_map, local_param_group_map是param与(group_index, group_params_len)的映射, local_param_group_map虽然返回了但后面没用
local_param_group_map = {}
group_ranges = [ {"params": []} for _ in param_groups ]
for model_gbuf_range_map in model_gbuf_ranges:
for dtype, gbuf_range_map in model_gbuf_range_map.items():
for param in gbuf_range_map["param_map"]:
group_index = world_param_group_map[param]
group_range = group_ranges[group_index]
group_range["params"].append(param)
local_param_group_map[param] =
(group_index, len(group_range["params"]) - 1)
# Squeeze zero-size group ranges.
for group_index, group_range in enumerate(group_ranges):
group_range["orig_group"] = param_groups[group_index]
group_range["orig_group_idx"] = param_groups[group_index]
return local_param_group_map, group_ranges
- 在初始化Optimizer之后,是通过创建
self.build_model_and_main_param_groups创建optimizer step要用到的main parameter groups, 这里的group一方面是要进行reduce和gather通信操作,另一方面是被优化器用于梯度的更新操作。
class DistributedOptimizer(MixedPrecisionOptimizer):
def __init__(...):
...
# Allocate main param shards.
(
self.model_float16_groups,
self.model_fp32_groups,
self.shard_float16_groups,
self.shard_fp32_groups,
self.shard_fp32_from_float16_groups,
) = self.build_model_and_main_param_groups(self.model_gbuf_ranges,
self.model_param_gbuf_map,
self.opt_group_ranges)
...
self.build_model_and_main_param_groups的实现主要是关于fp32/fp16/bf16三种类型训练时优化器内的显存分配。
@classmethod
def build_model_and_main_param_groups(cls,
model_gbuf_ranges,
param_gbuf_map,
opt_group_ranges):
...
# 保存原本fp16类型param
model_float16_groups = []
# 保存原本fp32类型param
model_fp32_groups = []
# 保存原本fp16类型param的切片
shard_float16_groups = []
# 保存原本fp32类型param的切片
shard_fp32_groups = []
# 保存原本fp16类型param的fp32类型param的副本
shard_fp32_from_float16_groups = []
# 分配每个group的param参数切片
for group_index, group_range in enumerate(opt_group_ranges):
for model_param in group_range["params"]:
if model_param.type() in ['torch.cuda.HalfTensor',
'torch.cuda.BFloat16Tensor']:
# 如果是fp16/bf16类型参数,clone为fp32类型的切片.
shard_model_param = model_param.detach().view(-1)
[param_range.start:param_range.end]
shard_main_param = shard_model_param.clone().float()
...
# 添加到group中
model_float16_params_this_group.append(model_param)
shard_float16_params_this_group.append(shard_model_param)
shard_fp32_from_float16_params_this_group.append(shard_main_param)
elif model_param.type() == 'torch.cuda.FloatTensor':
# 如果是fp32类型参数,不进行clone,直接引用
shard_model_param = model_param.view(-1)
[param_range.start:param_range.end]
model_fp32_params_this_group.append(model_param)
shard_fp32_params_this_group.append(shard_model_param)
...
# 更新优化器的参数
group_range["orig_group"]["params"] = [
*shard_fp32_params_this_group,
*shard_fp32_from_float16_params_this_group,
]
return (
model_float16_groups,
model_fp32_groups,
shard_float16_groups,
shard_fp32_groups,
shard_fp32_from_float16_groups,
)
- 在Optimizer init中,接下来是初始化self.param_buffers,这里的self.param_buffers是DDP模型的grad buffer的view示图,跟grad buffer共享存储,但是用自己的数据类型;最后更新优化器的param_groups。
class DistributedOptimizer(MixedPrecisionOptimizer):
def __init__(...):
...
# 初始化self.param_buffers
self.param_buffers = []
for model_index, model in enumerate(self.models):
current_param_buffers = {}
for dtype, grad_buffer in model._grad_buffers.items():
# 获取存储,这里是兼容的写法.
try:
storage = grad_buffer.data.storage()._untyped()
except:
storage = grad_buffer.data.storage().untyped()
# 基于grad_buffer的storage创建param_buffer类型,这里的params_dtype是参数类型; 这里的torch.tensor没有autograd的历史。
param_buffer = torch.tensor(
storage,
dtype = params_dtype,
device = grad_buffer.data.device)
param_buffer = param_buffer[:grad_buffer.numel_padded]
# 这里的dtype是grad_buffer的类型
current_param_buffers[dtype] = param_buffer
self.param_buffers.append(current_param_buffers)
# 最后更新优化器的param_groups
self.optimizer.param_groups =
[ g["orig_group"] for g in self.opt_group_ranges ]
self.optimizer.load_state_dict(self.optimizer.state_dict())
3. 参考
- Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
- Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
- NVIDIA/Megatron-LM
原文地址:https://blog.csdn.net/qinduohao333/article/details/136006263
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65765.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[论文笔记] PAI-Megatron 1、Qwen continuing pretrain(CT)千问预训练](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)