本文介绍: HiveSQL题——collect_set()/collect_list()聚合函数
一、collect_set() /collect_list()介绍
collect_set()函数与collect_list()函数属于高级聚合函数(行转列),将分组中的某列转换成一个数组返回,常与concat_ws()函数连用实现字段拼接效果。
二、collect_set() /collect_list()有序性
0 问题描述
有一张用户关注表table20,需求:根据用户user_id分组,按照粉丝关注的时间升序排序,输出粉丝id数组和粉丝关注的时间数组,并保障两个数组的数据能一一对应。
1 数据准备
2 数据分析
方式一: row_number() over(partition by .. order by..) as rn 排序,然后再使用collect_list()/collect_set()进行聚合.

发现问题:ut数组内的时间并没有按照升序排序输出。
原因分析:


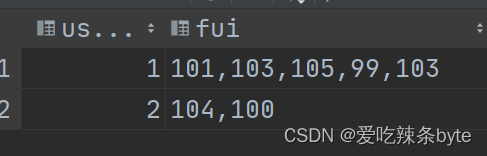


3 小结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



