ELK集群搭建(基础教程)
目录:
机器准备
集群内各台机器安装Elasticsearch
安装部署Kafka(注:每个节点都配置,注意ip不同)
安装logstash工具
安装filebeat
ELK收集Nginx的json日志
ELK收集Nginx正常日志和错误日志
ELK收集Tomcat日志
ELK收集docker日志
配置filebeat收集单个docker日志
modules日志收集
使用redis作为缓存收集日志
使用Kafka做缓存收集日志
机器准备
172.20.26.204 node01
172.20.26.207 node02
172.20.26.208 node03
系统版本:CentOS Linux release 7.9.2009 (Core)
#各台服务器安装基础工具软件,系统更新
yum install vim net-tools epel-release wget -y
yum update
#修改每台服务器的hostname
hostnamectl set-hostname node01 #172.20.26.204
hostnamectl set-hostname node02 #172.20.26.207
hostnamectl set-hostname node03 #172.20.26.208
分别在 172.20.26.204、172.20.26.207、172.20.26.208服务器上配置域名映射
[root@node01 ~]# vim /etc/hosts
[root@node02 ~]# vim /etc/hosts
[root@node03 ~]# vim /etc/hosts
172.20.26.204 node01
172.20.26.207 node02
172.20.26.208 node03
关闭selinux、firewalld防火墙
[root@bogon ~]# vim /etc/selinux/config
[root@bogon ~]# systemctl stop firewalld
[root@bogon ~]# systemctl disable firewalld
一、集群内各台机器安装Elasticsearch
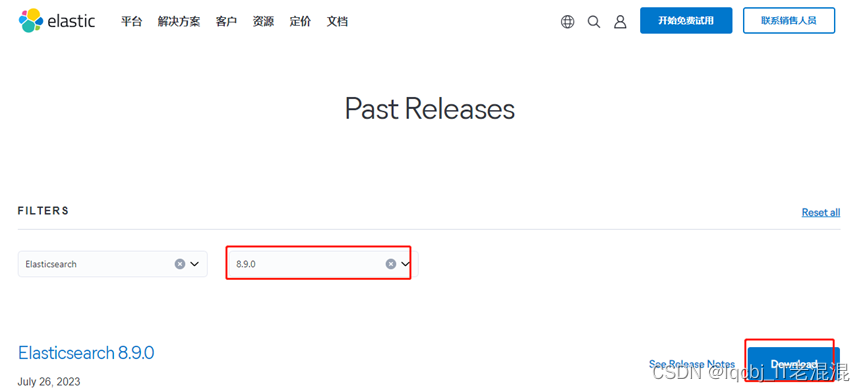
1、下载Elasticsearch的安装包
官方地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch

2、Elasticsearch安装(每台机器都执行)
#下载安装包存放在/data/software/目录
[root@node01 /]# mkdir -p /data/software && cd /data/software #创建并进入/data/software
[root@node02 /]# mkdir -p /data/software && cd /data/software #创建并进入/data/software
[root@node03 /]# mkdir -p /data/software && cd /data/software #创建并进入/data/software
wget -c https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.9.0-x86_64.rpm
linux开发java环境可能和elasticsearch java环境冲突,因为 elasticsearch 需要JDK才可以 ,所需需要指定elasticsearch的java环境,给它配置一个特定的java环境运行,下载JDK,然后解压即可。
Elasticsearch 和 JVM 兼容性版本查询地址如下:
https://www.elastic.co/cn/support/matrix#matrix_jvm
版本选择推荐及总结
1、ES 7.x 及之前版本,选择 Java 8
2、ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 18
3、Java 9、Java 10、Java 12 和 Java 13 均为短期版本,不推荐使用
4、M1(Arm) 系列 Mac 用户建议选择 ES 7.8.x 以上版本,因为考虑到 ELK 不同产品自身兼容性,7.8.x以上版本原生支持 Arm 原生 JDK
wget -c https://download.oracle.com/java/17/latest/jdk-17_linux-aarch64_bin.tar.gz
tar -zxf jdk-17_linux-aarch64_bin.tar.gz #各服务器均需安装jdk
下载后可以拷贝到其他服务器的/data/software目录下
#安装
[root@node01 software]# rpm -ivh elasticsearch-8.9.0-x86_64.rpm
[root@node02 software]# rpm -ivh elasticsearch-8.9.0-x86_64.rpm
[root@node03 software]# rpm -ivh elasticsearch-8.9.0-x86_64.rpm
警告:elasticsearch-8.9.0-x86_64.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中… ################################# [100%]
Creating elasticsearch group… OK
Creating elasticsearch user… OK
正在升级/安装…
1:elasticsearch-0:8.9.0-1 ################################# [100%]
————————— Security autoconfiguration information ——————————
Authentication and authorization are enabled.
TLS for the transport and HTTP layers is enabled and configured.
The generated password for the elastic built-in superuser is : 9gVL6ve8ARLwwJibai8Z
If this node should join an existing cluster, you can reconfigure this with
‘/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node –enrollment-token <token-here>’
after creating an enrollment token on your existing cluster.
You can complete the following actions at any time:
Reset the password of the elastic built-in superuser with
‘/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic’.
Generate an enrollment token for Kibana instances with
‘/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana’.
Generate an enrollment token for Elasticsearch nodes with
‘/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s node’.
————————————————————————————————-
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service

172.20.26.204服务器上的elasticsearch安装完成。其他节点同样操作即可。
HOME: /usr/share/elasticsearch
配置:/etc/elasticsearch
日志:/var/log/elasticsearch/
数据:/data/elasticsearch
配置2:/etc/sysconfig/elasticsearch
#查看elasticsearch配置文件目录
[root@node01 software]# rpm -qc elasticsearch
/etc/elasticsearch/elasticsearch-plugins.example.yml
/etc/elasticsearch/elasticsearch.yml
/etc/elasticsearch/jvm.options
/etc/elasticsearch/log4j2.properties
/etc/elasticsearch/role_mapping.yml
/etc/elasticsearch/roles.yml
/etc/elasticsearch/users
/etc/elasticsearch/users_roles
/etc/sysconfig/elasticsearch
/usr/lib/sysctl.d/elasticsearch.conf
/usr/lib/systemd/system/elasticsearch.service
#修改 elasticsearch 下的bin/elasticsearch(各服务器均需操作)
#在首行添加
#配置自己的jdk17
vim /usr/share/elasticsearch/bin/elasticsearch
export JAVA_HOME=/data/software/jdk-17.0.8
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x “$JAVA_HOME/bin/java” ]; then
JAVA=”/data/software/jdk-17.0.8 /bin/java”
else

为后面es集群设置,每个节点操作如下:
#编辑elasticsearch.yml配置文件
vim /etc/elasticsearch/elasticsearch.yml
grep “^[a-Z]” /etc/elasticsearch/elasticsearch.yml
cluster.name: es_cluster #集群名称,各节点要一致
node.name: node01 #节点名称,同一个集群内所有节点的节点名称不能重复
path.data: /data/elasticsearch #将es的数据存在该目录,注意创建该目录
path.logs: /var/log/elasticsearch #日志目录,会创建以集群名称的一个日志目录 eg:es-app.log
bootstrap.memory_lock: true #内存锁定
network.host: 0.0.0.0 #绑定监听地址
http.port: 9200 #默认端口号
discovery.seed_hosts: [“172.20.26.204”, “172.20.26.207”,”172.20.26.208″]
cluster.initial_master_nodes: [“node01″,”node02″,”node03”]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
xpack.security.transport.ssl:
http.host: 0.0.0.0
transport.host: 0.0.0.0



vim /etc/systemd/system.conf #每个节点操作一遍
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
保存, 重启系统
#创建es数据存储目录
[root@node01 software]# mkdir -p /data/elasticsearch
[root@node02 software]# mkdir -p /data/elasticsearch
[root@node03 software]# mkdir -p /data/elasticsearch
# 创建证书目录
[root@node01 software]#mkdir -p /etc/elasticsearch/certs
[root@node01 bin]# vim /etc/elasticsearch/jvm.options
#去掉以下注释并顶格,各个节点均需操作
-Xms2g #默认是4g,可以根据自己情况适当调整大小,例如,1g、2g
-Xmx2g #默认是4g,可以根据自己情况适当调整大小,例如,1g、2g
#es因为安全问题拒绝使用root用户启动(各节点均需操作)
解决方法:
1.添加用户组es、创建用户es并设置密码
groupadd es
useradd es -g es -p 1qaz2wsx # -g 指定组 -p 设置密码为1qaz2wsx
2.添加目录拥有权限
更改 elasticsearch文件夹及内部文件的所属用户及组为es,如果是编译安装或者是二进制安装的话,可能只有一个目录。

[root@node01 ~]# find / -name elasticsearch
/etc/sysconfig/elasticsearch
/etc/elasticsearch
/var/lib/elasticsearch
/var/log/elasticsearch
/usr/share/elasticsearch
/usr/share/elasticsearch/bin/elasticsearch
/data/elasticsearch
# -R 处理指定目录以及其子目录下的所有文件权限赋予es用户及es组
chown es:es -R /etc/sysconfig/elasticsearch /etc/elasticsearch /var/lib/elasticsearch /var/log/elasticsearch /usr/share/elasticsearch /data/elasticsearch
解决Elasticsearch集群开启账户密码安全配置自相矛盾的坑
- 生成CA证书
在第一台服务器节点 node01 设置集群多节点通信密钥,使用 elasticsearch-certutil 工具为您的集群生成 CA。
[root@node01 ~]# cd /usr/share/elasticsearch/bin/
[root@node01 bin]# ./elasticsearch-certutil ca
a.出现提示时,接受默认文件名,即 elastic-stack-ca.p12。此文件包含 CA 的公共证书和用于为每个节点签署证书的私钥。
b.输入 CA 的密码。如果不部署到生产环境,您可以选择将密码留空,这里输入的密码为1qaz2wsx

2、配置CA证书
用 ca 证书签发节点证书,为集群中的节点生成证书和私钥。包括在上一步中生成的 elastic-stack-ca.p12 输出文件。
[root@node01 bin]# ./elasticsearch-certutil cert –ca elastic-stack-ca.p12
根据提示
a.输入您的 CA 的密码,请按 Enter。
b.为证书创建密码并接受默认文件名。创建的密码为1qaz2wsx
输出文件是一个名为 elastic-certificates.p12 的密钥库。此文件包含节点证书、节点密钥和 CA 证书。

将生成的证书文件移动到证书目录中(/etc/elasticsearch/certs)
[root@node01 bin]# mv /usr/share/elasticsearch/elastic-certificates.p12 /etc/elasticsearch/certs/

3、复制证书到集群
在集群中的每个节点上,将 elastic-certificates.p12 文件复制到 证书目录中/etc/elasticsearch/certs
[root@node01 certs]# scp elastic-certificates.p12 root@172.20.26.207:/etc/elasticsearch/certs/
[root@node01 certs]# scp elastic-certificates.p12 root@172.20.26.208:/etc/elasticsearch/certs/
[root@node01 certs]# chown es:es -R /etc/elasticsearch #各个节点再次给/etc/elasticsearch 赋权给es用户和组
4、修改配置文件(需要注意的是:格式一定要对齐,否则会报错)
vim /etc/elasticsearch/elasticsearch.yml #各个节点打开配置文件进行修改
a.基本集群配置,不启用安全也需要的配置
cluster.name: es_cluster #每个节点一致
node.name: node01 #每个节点不同
b.安全配置
由于在群集的每个节点上使用相同的Elastic-Certificate.p12文件,因此将验证模式设置为证书:
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: /etc/elasticsearch/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /etc/elasticsearch/certs/elastic-certificates.p12
5、配置密码
如果在创建节点证书时输入了密码,运行以下命令以将密码存储在Elasticsearch密钥库中:
[root@node01 ~]# su es #切换到es用户下执行
[es@node01 elasticsearch]$ cd /usr/share/elasticsearch/bin #各服务器切换到elasticsearch的bin目录下,密码设置为1qaz2wsx
[es@node01 bin]$
./elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
./elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password
./elasticsearch-keystore add xpack.security.http.ssl.keystore.secure_password
./elasticsearch-keystore add xpack.security.http.ssl.truststore.secure_password
也可以自动生成随机密码,elasticsearch-setup-passwords auto
4-5的步骤在每个节点中都需要进行。
密码设置为1qaz2wsx



6、重新启动es服务
在es用户下,node01、node02、node03的elasticsearch服务重启
[root@node01 ~]# su es
[es@node01 root]$ cd /usr/share/elasticsearch/bin/
[es@node01 bin]$./elasticsearch -d #后台方式启动


Node03也可以用同样方法启动。



后面也可以创建elasticsearch.sh脚本来启动:
mkdir -p /data/sh && cd /data/sh
vim /data/sh/elasticsearch.sh
#!/bin/bash
sudo -u es bash << EOF
cd /usr/share/elasticsearch/bin
./elasticsearch -d
EOF
保存退出
脚本说明:其中,普通用户名称需要替换为实际的普通用户名称。在脚本中使用sudo -u命令可以切换到指定的用户下执行命令,<< EOF和EOF之间的代码块是在普通用户下执行的命令。执行完普通用户下的命令后,脚本会自动切换回root用户,继续执行后续的命令。
[root@node01 sh]# chmod +x /data/sh/elasticsearch.sh #赋予/data/sh/elasticsearch.sh 可执行权限
[root@node01 sh]# sh elasticsearch.sh #在root用户下,执行elasticsearch.sh启动脚本
[root@node01 sh]# ./elasticsearch.sh
/var/tmp/scl5h41LI: line 8: -u: command not found



9200、9300端口开启,Elasticsearch 服务启动完成。
同时将elasticsearch.sh脚本文件拷贝到其他节点对应的目录下,执行elasticsearch.sh启动服务。
[root@node01 sh]# scp elasticsearch.sh root@172.20.26.207:/data/sh/
[root@node01 sh]# scp elasticsearch.sh root@172.20.26.208:/data/sh/
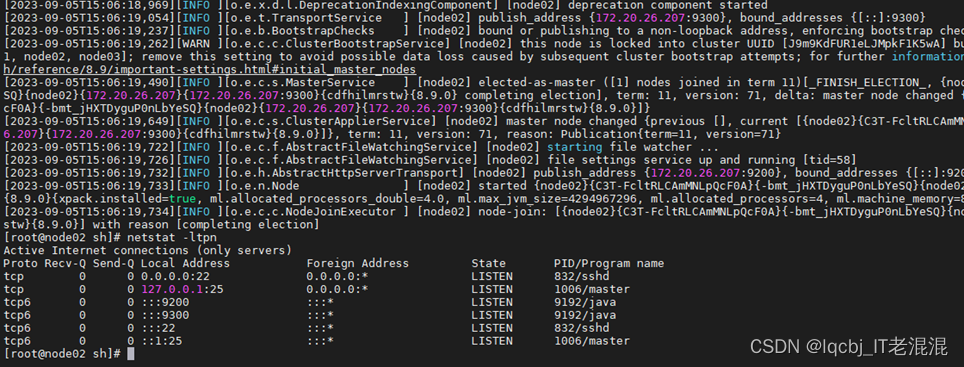

node02、node03节点上的elasticsearch服务均已启动。
将elasticsearch.sh启动添加到开机启动中,各个节点均需执行
1、编辑启动文件
[root@node01 sh]# vim /etc/rc.d/rc.local #添加以下内容
/data/sh/elasticsearch.sh
保存退出
[root@node01 sh]# chmod +x /etc/rc.d/rc.local #添加可执行权限
[root@node01 sh]# systemctl restart rc-local.service
[root@node01 sh]# systemctl status rc-local.service


# 如需指定用户启动 请使用如下方式:su – username -c “your-cammand”
/bin/su – es -c ‘/data/sh/elasticsearch.sh’

保存退出
[root@node01 sh]#chmod +x /etc/rc.d/rc.local #添加可执行权限
systemctl restart rc-local.service && systemctl status rc-local.service #重启并查看状态
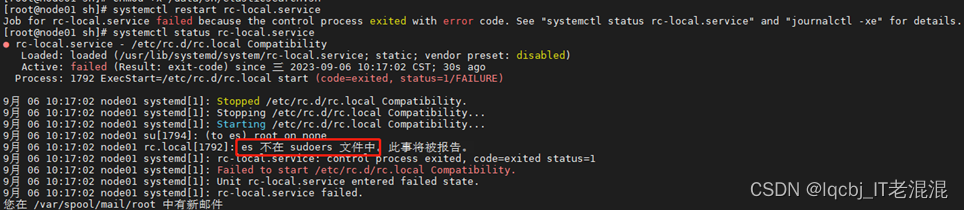
报错:es用户权限不够,需要提升权限
在root用户下查看/etc/sudoers文件权限,如果是只读权限,修改为可写权限
[root@node01 sh]# ll /etc/sudoers #查看/etc/sudoers文件权限
-r–r—–. 1 root root 4328 9月 30 2020 /etc/sudoers #只有只读权限
[root@node01 sh]# chmod u+w /etc/sudoers #修改为可写权限
[root@node01 sh]# ll /etc/sudoers #再次查看/etc/sudoers文件权限
-rw-r—–. 1 root root 4328 9月 30 2020 /etc/sudoers #增加了可写权限
[root@node01 sh]# vim /etc/sudoers #编辑/etc/sudoers文件,在root ALL=(ALL) ALL的下一行添加代码es ALL=(ALL) ALL
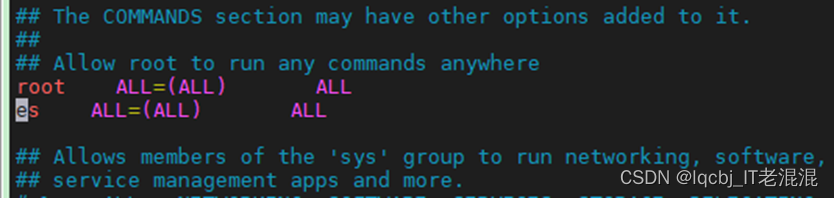
保存退出
[root@node01 sh]# chmod 440 /etc/sudoers #恢复/etc/sudoers的权限为440
[root@node01 sh]# ll /etc/sudoers
-r–r—– 1 root root 4354 9月 6 10:23 /etc/sudoers
[root@node01 sh]# systemctl restart rc-local.service #重启rc-local服务
[root@node01 sh]# systemctl status rc-local.service #查看rc-local状态,然后重启服务器,验证elasticsearch.sh开机启动。
完成elasticsearch.sh脚本开机自动执行成功。
其他节点同样操作即可完成elasticsearch.sh脚本开机自动执行。
3、检查ES集群部署
各个节点修改elasticsearch.yml
vim /etc/elasticsearch/elasticsearch.yml
# 指定集群名称3个节点必须一致 cluster.name: es_cluster
#指定节点名称,每个节点名字唯一 node.name: node01
#是否有资格为master节点,默认为true,node.master: true
#是否为data节点,默认为true,node.data: true
# 绑定ip,开启远程访问,可以配置0.0.0.0,这里也可以配ip地址 network.host: 0.0.0.0
#指定web端口 #http.port: 9200
#指定tcp端口 #transport.tcp.port: 9300
#用于节点发现,如果你不配域名映射,直接用ip也是可以的 discovery.seed_hosts: [“node01”, “node02”, “node03”]
如果后期有新节点加入,新节点的 discovery.seed_hosts 没必要包含所有的节点,只要它里面包含集群中已有的节点信息,新节点就能发现整个集群了。
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群节点的名称,每个节点的名称 cluster.initial_master_nodes: [“node01″,”node02″,”node03”]
因此当您在生产模式下第一次启动全新的群集时,你必须显式列出符合资格的主节点。也就是说,需要使用 cluster.initial_master_nodes 设置来设置该主节点列表。重新启动集群或将新节点添加到现有集群时,你不应使用此设置。
cluster.initial_master_nodes 该配置项并不是需要每个节点设置保持一致,设置需谨慎,如果其中的主节点关闭了,可能会导致其他主节点也会关闭。因为一旦节点初始启动时设置了这个参数,它下次启动时还是会尝试和当初指定的主节点链接,当链接失败时,自己也会关闭!
因此,为了保证可用性,预备做主节点的节点不用每个上面都配置该配置项!保证有的主节点上就不设置该配置项,这样当有主节点故障时,还有可用的主节点不会一定要去寻找初始节点中的主节点!
注意:第一次成功形成集群后,从每个节点的配置中删除 cluster.initial_master_nodes 设置。重新启动集群或向现有集群添加新节点时,请勿使用此设置。
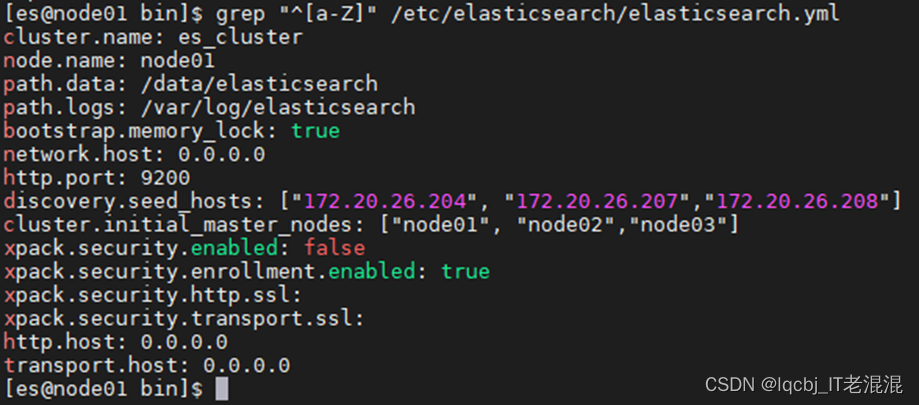
Node01
[es@node01 bin]$ grep “^[a-Z]” /etc/elasticsearch/elasticsearch.yml
cluster.name: es_cluster
node.name: node01
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: [“172.20.26.204”, “172.20.26.207”,”172.20.26.208″]
cluster.initial_master_nodes: [“node01”, “node02″,”node03”]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
xpack.security.transport.ssl:
http.host: 0.0.0.0
transport.host: 0.0.0.0
Node02
[es@node02 bin]$ grep “^[a-Z]” /etc/elasticsearch/elasticsearch.yml
cluster.name: es_cluster
node.name: node02
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: [“172.20.26.204”, “172.20.26.207”,”172.20.26.208″]
cluster.initial_master_nodes: [“node01”, “node02″,”node03”]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
xpack.security.transport.ssl:
http.host: 0.0.0.0
transport.host: 0.0.0.0

Node03
[es@node03 bin]$ grep “^[a-Z]” /etc/elasticsearch/elasticsearch.yml
cluster.name: es_cluster
node.name: node03
path.data: /data/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: [“172.20.26.204”, “172.20.26.207”,”172.20.26.208″]
cluster.initial_master_nodes: [“node01”, “node02″,”node03”]
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
xpack.security.http.ssl:
xpack.security.transport.ssl:
http.host: 0.0.0.0
transport.host: 0.0.0.0

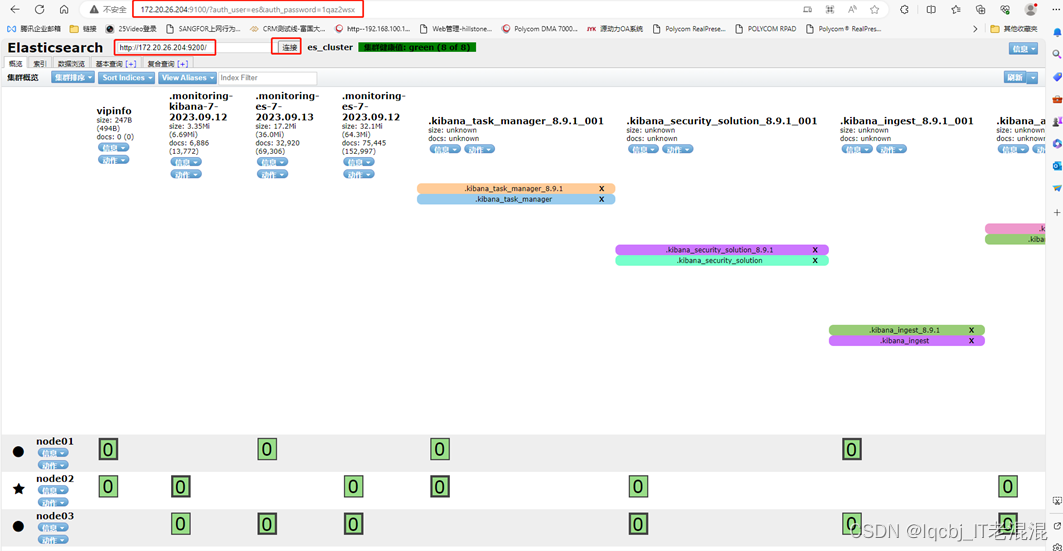
三台机器的elasticsearch服务均已启动,然后访问随意一台机器即可,例如:172.20.26.204:9200,出现如下就说明访问成功了。

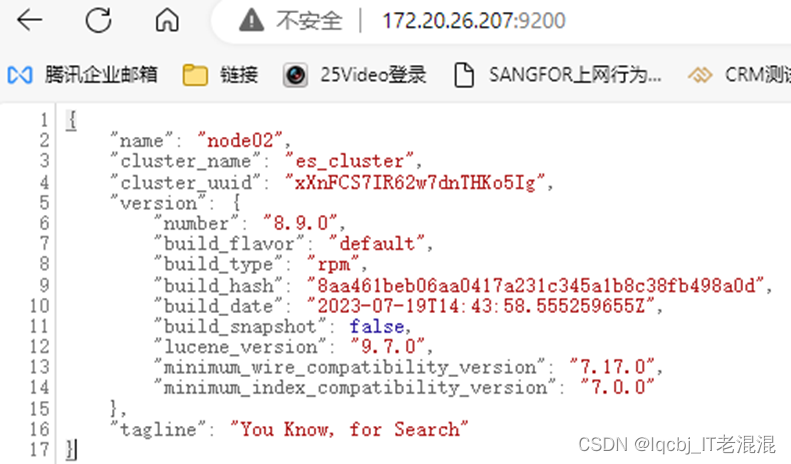
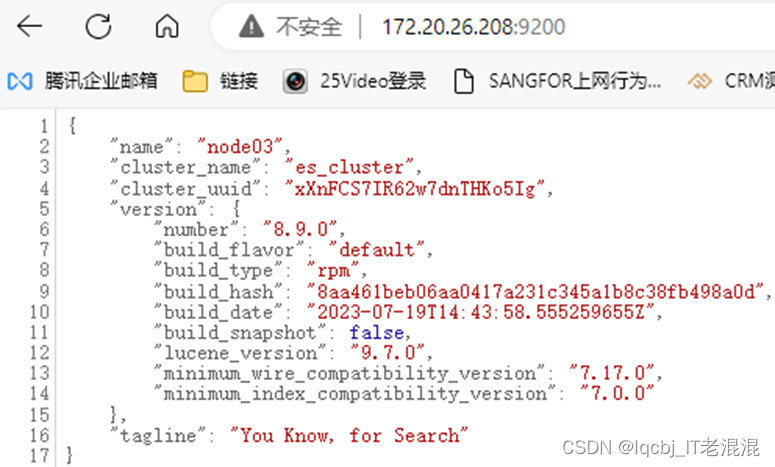
172.20.26.204:9200/_cat/nodes #查看集群状态

设置账号
在使用它们之前,我们必须为它们设置一个账号,切换到 Elasticsearch的bin目录下
[root@node01 elasticsearch]# su es
[es@node01 elasticsearch]$ cd /usr/share/elasticsearch/bin
[es@node01 bin]$ ./elasticsearch-users useradd es -r superuser #设置es用户并赋予超级用户角色
然后输入两次密码,1qaz2wsx

在浏览器地址输入:172.20.26.204:9200 ,输入刚才创建的用户es和密码1qaz2wsx,

向集群中创建一些索引、数据
创建索引
[root@node01 elasticsearch]# curl -XPUT ‘172.20.26.204:9200/vipinfo?pretty’
{
“acknowledged” : true,
“shards_acknowledged” : true,
“index” : “vipinfo”
}

在各节点上查看集群状态
[root@node01 elasticsearch]# curl -XGET ‘http://localhost:9200/_cat/nodes’

也可以在浏览器中查看集群状态
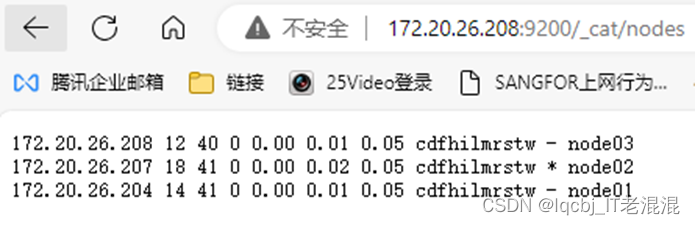
查看集群健康状态:
[es@node01 bin]$ curl -XGET ‘http://localhost:9200/_cluster/health’


./elasticsearch-reset-password -u elastic -i #重置elastic(内置超级用户账号)
ERROR: Failed to determine the health of the cluster

后续再排查elastic账号密码重置的问题
4、安装Elasticsearch-head插件(可视化插件), 安装在master上即可
安装ES可视化插件ES-head前需安装node.js
#安装node.js
官网地址:Node.js — Download

下载解压(右键复制链接)
[root@node01 ~]# cd /data/software/
[root@node01 software]# wget https://nodejs.org/dist/v18.17.1/node-v18.17.1-linux-x64.tar.xz
[root@node01 software]# tar -xf node-v18.17.1-linux-x64.tar.xz
然后我们再配置环境变量:
vi /etc/profile
在最后加上:
export NODE_HOME=/data/software/node-v18.17.1-linux-x64
export PATH=$NODE_HOME/bin:$PATH
保存,再执行
source /etc/profile 让环境变量生效
node -v #查看版本
npm -v #查看版本
#phantomjs 官网 Download PhantomJS
[root@node01 software]#wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
#以下两个如果已经装过可忽略
yum -y install bzip2
yum -y install fontconfig-devel
[root@node01 software]#tar -xvjf phantomjs-2.1.1-linux-x86_64.tar.bz2
#创建软连接
ln -s /data/software/node-v18.17.1-linux-x64/bin/node /usr/local/bin/node
ln -s /data/software/node-v18.17.1-linux-x64/bin/npm /usr/local/bin/npm
ln -s /data/software/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/phantomjs
#查看版本
node -vnpm -vphantomjs –version

node: /lib64/libm.so.6: version `GLIBC_2.27′ not found (required by node)
node: /lib64/libc.so.6: version `GLIBC_2.25′ not found (required by node)
node: /lib64/libc.so.6: version `GLIBC_2.28′ not found (required by node)
node: /lib64/libstdc++.so.6: version `CXXABI_1.3.9′ not found (required by node)
node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.20′ not found (required by node)
node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21′ not found (required by node)
# 查看系统内安装的glibc版本
strings /lib64/libc.so.6 |grep GLIBC_
[root@node01 build]# rpm -qa | grep glibc
glibc-headers-2.17-326.el7_9.x86_64
glibc-common-2.17-326.el7_9.x86_64
glibc-2.17-326.el7_9.x86_64
glibc-devel-2.17-326.el7_9.x86_64
#安装gcc-8.2.0所依赖的环境
#a
[root@node01 usr]# yum install zlib-devel pcre-devel bison bzip2 gcc gcc-c++ glibc-headers -y #安装相关依赖包
#b升级GNU Make 3.82到4.3
yum install centos-release-scl -y
yum install devtoolset-8 -y
scl enable devtoolset-8 — bash
# 设置环境变量
echo “source /opt/rh/devtoolset-8/enable” >> /etc/profile
source /etc/profile
#b升级make
还是进入root目录下
cd /root
wget https://ftp.gnu.org/gnu/make/make-4.3.tar.gz
tar -xzvf make-4.3.tar.gz && cd make-4.3/
# 安装到指定目录
./configure –prefix=/usr/local/make
make -j 4 && make install
# 创建软链接
cd /usr/bin/ && mv make make.bak
ln -sv /usr/local/make/bin/make /usr/bin/make
cd /root
# 编译安装 (如果编译失败了,可以使用make clean清除已编译的内容,再重新编译、安装)
wget http://ftp.gnu.org/gnu/glibc/glibc-2.28.tar.gz
tar -xf glibc-2.28.tar.gz
cd glibc-2.28/ && mkdir build && cd build
../configure –prefix=/usr –disable-profile –enable-add-ons –with-headers=/usr/include –with-binutils=/usr/bin
[root@node01 build]#make -j 4 && make install
[root@node01 software]#wget https://cdn.frostbelt.cn/software/libstdc%2B%2B.so.6.0.26
[root@node01 software]# cp libstdc++.so.6.0.26 /usr/lib64/
[root@node01 software]# cd /usr/lib64/
[root@node01 lib64]# ln -snf ./libstdc++.so.6.0.26 libstdc++.so.6
[root@node01 build]# node -vnpm -vphantomjs –version #查看版本

#假如Node01 重启后,使用ssh远程登录,出现如下告警信息:

-bash: 警告:setlocale: LC_TIME: 无法改变区域选项 (zh_CN.UTF-8)
原因分析:
系统已经设置了默认地区_语言.字符集为zh_CN.UTF-8,但是在系统中没有定义对应的locale文件,所以只需要手动生成这个locale文件即可!
解决办法:
1)# vim /etc/environment #添加下面两行内容
LANG=”zh_CN.UTF-8″
LC_ALL=
2)source这个文件内容:
# source /etc/environment
3)# vim /etc/sysconfig/i18n
LANG=”zh_CN.UTF-8″
4)然后执行如下命令,生成 en_US.UTF-8这个字符集对应的locale文件:
# localedef -v -c -i zh_CN -f UTF-8 zh_CN.UTF-8
下载安装ES-head插件
电脑上浏览器打开
https://download.csdn.net/download/weixin_41879185/87749515?utm_source=bbsseo
点击“立即下载”,完成后将elasticsearch-head.zip上传到服务器的/data/software/目录下
[root@node01 ~]# cd /data/software/
[root@node01 software]#unzip elasticsearch-head.zip #解压elasticsearch-head.zip包
[root@node01 software]# cd elasticsearch-head #进入到elasticsearch-head目录
npm install
npm run start
nohup grunt server & # #重新后台运行head插件服务,这个要注意,一定要在插件也就是上方的目录的根目录下,执行此条命令才可以。
nohup npm run start & #使用grunt方式后台运行启动
npm install -g grunt-cli
grunt server &netstat -tulnp| grep 9100

http://172.20.26.204:9100/,显示集群健康值: 未连接

原因是:因为给ES配置了加密,用之前的访问链接访问不到,访问的时候需要用户认证。
[root@node01 software]# vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true # 开启跨域访问支持,默认为false
http.cors.allow-origin: “*” # 跨域访问允许的域名地址
http.cors.allow-headers: Authorization,Content-Type
保存退出

保存文件后重启 elasticsearch 和 elasticsearch-head
[root@node01 bin]# cd /data/software/elasticsearch-head
[root@node01 elasticsearch-head]# nohup npm run start & #后台启动运行
http://172.20.26.204:9100/?auth_user=es&auth_password=1qaz2wsx
#浏览器中打开,使用es用户和密码1qaz2wsx #前面已创建完成,后面也可以使用http://172.20.26.204:9100/来打开

创建elasticsearch-head启动脚本
#!/ban/bash
cd /data/software/elasticsearch-head
nohup npm run start &

保存退出
chmod +x /data/sh/es_head.sh #将脚本添加可执行权限
vim /etc/rc.d/rc.local #把脚本添加到开机启动服务

chmod +x /etc/rc.d/rc.local
systemctl restart rc-local.service
systemctl status rc-local.service
二、安装Kibana(各节点上安装配置)
在node01节点上
#下载kibana-8.9.1-linux-x86_64.tar.gz包
[root@node01 certs]# cd /data/software #进入软件存放目录
wget -c https://artifacts.elastic.co/downloads/kibana/kibana-8.9.1-linux-x86_64.tar.gz
#各个节点安装kibana-8.9.1-linux-x86_64.tar.gz包
tar -zxf kibana-8.9.1-linux-x86_64.tar.gz
#各个节点修改Kibana配置文件
vim /data/software/kibana-8.9.1/config/kibana.yml
[root@node01 software]# grep “^[a-Z]” /data/software/kibana-8.9.1/config/kibana.yml
server.port: 5601 # 站点端口号
server.host: “172.20.26.204”
server.name: “node01”
elasticsearch.hosts: [“http://localhost:9200”]
i18n.locale: “zh-CN”
kibana.index: “.kibana”
[root@node01 bin]# chown -R es:es /data/software/kibana-8.9.1 #将整个kibana-8.9.1目录更改属组为es用户和组
#启动Kibana&&查看服务状态&&通过IP访问界面
[root@node01 bin]#./kibana –allow-root #kibana不建议以root用户启动,如果用root启动,需要加–allow-root,我们这里用es用户来启动kibana服务
[root@node01 bin]# su es
[es@node01 bin]$ ./kibana #前台启动kibana服务
[es@node01 bin]$nohup ./kibana & #也可以将Kibana服务的后台启动

[es@node01 bin]$ tail -f /home/es/nohup.out #查看kibana的日志

打开http://172.20.26.204:5601 ,点击“自己浏览”。



稍等一会

这里你就可以看到集群的状态看,退出右上角“设置模式”,点击nodes就可以查看到节点状态,你可以随便点点就知道能浏览查看什么数据了,这里不再过多介绍。

如果你想管理索引,点击左边菜单栏,点击最底下的Stack Management,找到索引管理,里面的功能基本上就可以对ES上的数据进行操作了 。



#设置开机启动kiban服务
创建启动脚本
vim /data/sh/kibana.sh #因kibana 用的是非root用户运行,这里我们使用前面创建的es用户运行
#!/bin/bash
sudo -u es bash << EOF
cd /data/software/kibana-8.9.1/bin
nohup ./kibana &
EOF
保存退出
chmod +x /data/sh/kibana.sh #添加可执行权限
vim /etc/rc.d/rc.local

保存退出
chmod +x /etc/rc.d/rc.local
systemctl restart rc-local.service
systemctl status rc-local.service
节点node02、node03上进行同样的设置。
scp /data/sh/kibana.sh root@172.20.26.207:/data/sh #将脚本拷贝到node02相应路径下
scp /data/sh/kibana.sh root@172.20.26.208:/data/sh #将脚本拷贝到node03相应路径下
chmod +x /data/sh/kibana.sh #添加可执行权限
vim /etc/rc.d/rc.local #添加/data/sh/kibana.sh执行命令
/data/sh/kibana.sh
保存退出
chmod +x /etc/rc.d/rc.local #添加可执行权限
systemctl restart rc-local.service
systemctl status rc-local.service
三、安装logstash工具
#官网下载
https://www.elastic.co/cn/downloads/past-releases
选择产品Logstash,选择合适的版本即可,因为我们的前面安装配置的是elasticsearch-8.9.0-x86_64,所以我们也尽量安装相同版本的Logstash

点击“Download”,右键“LINUX X86_64”,复制链接

cd /data/software #进入/data/software,将安装包下载到这里
wget -c https://artifacts.elastic.co/downloads/logstash/logstash-8.9.0-linux-x86_64.tar.gz
[root@node01 software]# tar -zxf logstash-8.9.0-linux-x86_64.tar.gz
#安装结果测试
执行以下命令:
cd /data/software/logstash-8.9.0
bin/logstash -e ‘input { stdin { } } output { stdout {} }’
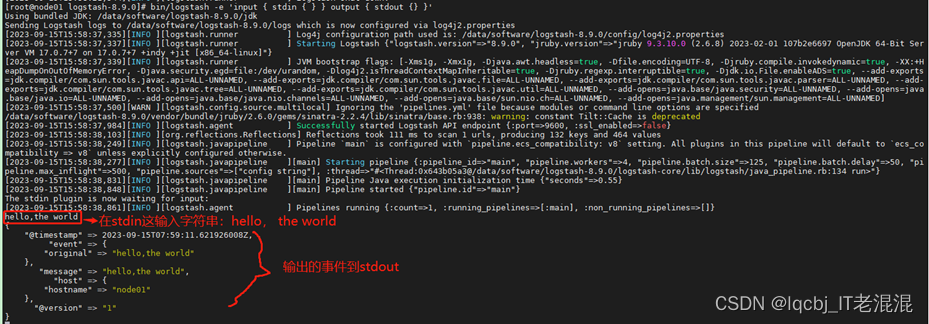
看到这样的输出结果,说明Logstash 安装是成功的。
#将ES的证书复制到Logstash目录。因为我们的ES使用的HTTPS访问认证, Logstash要发送日志到ES时,需要进行证书认证。
[root@node01 logstash-8.9.0]# cp -r /etc/elasticsearch/certs /data/software/logstash-8.9.0/
#添加一个配置文件,以收集操作系统日志作为例子
vim /data/software/logstash-8.9.0/systemlog.conf
input {
tcp {
port=> 9900
}
}
filter {
grok {
match => { “message” => “%{COMBINEDAPACHELOG}” }
}
mutate {
convert => {
“bytes” => “integer”
}
}
geoip {
source => “clientip”
target => “clientgeo”
}
useragent {
source => “agent”
target => “useragent”
}
}
output {
stdout { }
elasticsearch {
hosts => [“http://172.20.26.204:9200″,”http://172.20.26.207:9200″,”http://172.20.26.208:9200”]
index => “logstash}”
user => “es”
password => “1qaz2wsx”
}
}
#收集日志。运行日志收集脚本,开始收集日志,并查看日志
执行日志收集命令:
[root@node01 certs]#/data/software/logstash-8.9.0/bin/logstash -f /data/software/logstash-8.9.0/systemlog.conf

cd /etc/logstash/conf.d
vim nginx_log.conf
input {
redis {
host => “10.20.1.114”
port => “6379”
db => “0”
key => “nginx_access”
data_type => “list”
}
redis {
host => “10.20.1.114”
port => “6379”
db => “0”
key => “nginx_error”
data_type => “list”
}
}
filter {
mutate {
convert => [“upstream_time”, “float”]
convert => [“request_time”, “float”]
}
}
output {
stdout {}
if “access” in [tags] {
elasticsearch {
hosts => “http://10.20.1.114:9200”
manage_template => false
index => “nginx_access-%{+yyyy.MM}”
}
}
if “error” in [tags] {
elasticsearch {
hosts => “http://10.20.1.114:9200”
manage_template => false
index => “nginx_error-%{+yyyy.MM}”
}
}
}
#启动logstash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/nginx_log.conf
四、安装filebeat
#官网下载
https://www.elastic.co/cn/downloads/past-releases# #选择产品Filebeat及其版本
Past Releases of Elastic Stack Software | Elastic

点击“Download”,右键“LINUX X86_64”,复制链接地址

cd /data/software #进入/data/software,将安装包下载到这里
wget -c https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.9.0-linux-x86_64.tar.gz
[root@node01 software]# tar -zxf filebeat-8.9.0-linux-x86_64.tar.gz
[root@node01 software]# cd filebeat-8.9.0-linux-x86_64 #进入filebeat目录下
[root@node01 filebeat-8.9.0-linux-x86_64]# vim mogublog.yml #创建对应的配置文件
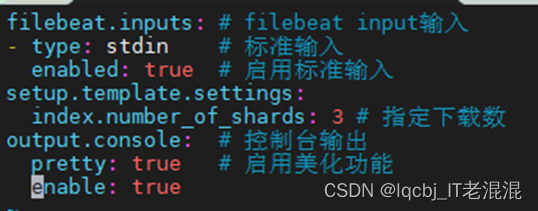
filebeat.inputs: # filebeat input输入
– type: stdin # 标准输入
enabled: true # 启用标准输入
setup.template.settings:
index.number_of_shards: 3 # 指定下载数
output.console: # 控制台输出
pretty: true # 启用美化功能
enable: true
chmod go-w /data/software/filebeat-8.9.0-linux-x86_64/mogublog.yml
[root@node01 filebeat-8.9.0-linux-x86_64]# ./filebeat -e -c mogublog.yml # 通过二进制文件来实现filebeat服务启动
#读取文件配置
再次创建一个文件mogublog-log.yml
[root@node01 filebeat-8.9.0-linux-x86_64]#vim mogublog-log.yml
filebeat.inputs:
– type: log
enabled: true
paths:
– /data/software/filebeat-8.9.0-linux-x86_64/logs/*.log
setup.template.settings:
index.number_of_shards: 3
output.console:
pretty: true
enable: true
#添加完成后,我们在到下面目录创建一个日志文件
mkdir -p /data/software/filebeat-8.9.0-linux-x86_64/logs
cd /data/software/filebeat-8.9.0-linux-x86_64/logs
echo “hello” >> a.log
#再次启动filebeat
chmod go-w /data/software/filebeat-8.9.0-linux-x86_64/mogublog-log.yml
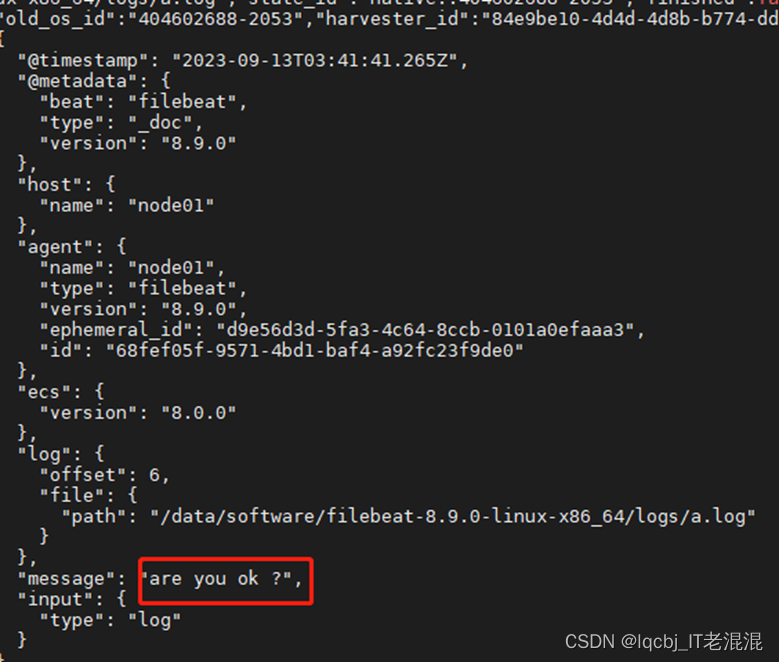
./filebeat -e -c mogublog-log.yml
能够发现,它已经成功加载到了我们的日志文件 a.log
echo “are you ok ?” >> a.log
#再次启动filebeat
[root@node01 filebeat-8.9.0-linux-x86_64]# ./filebeat -e -c mogublog-log.yml
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 & #后台启动filebeat服务
#新建配置文件filebeat_apache.yml
vim /data/software/filebeat-8.9.0-linux-x86_64/filebeat_apache.yml
filebeat.inputs:
– type: log
enabled: true
paths:
– /data/software/filebeat-8.9.0-linux-x86_64/apache_logs/*
output.logstash:
hosts: [“localhost:5044”]
mkdir -p /data/software/filebeat-8.9.0-linux-x86_64/apache_logs #创建apache_logs目录
运行Filebeat
cd /data/software/filebeat-8.9.0-linux-x86_64
[root@node01 filebeat-8.9.0-linux-x86_64]# ./filebeat -c filebeat_apache.yml
Exiting: /data/software/filebeat-8.9.0-linux-x86_64/data/filebeat.lock: data path already locked by another beat. Please make sure that multiple beats are not sharing the same data path (path.data)
原因
本机器已经存在filebeat启动,datapath被lock
解决办法
关闭已存在filebeat的进程,然后重新启动
[root@node01 filebeat-8.9.0-linux-x86_64]# ps -ef | grep filebeat
root 1492 1 0 10:33 ? 00:00:04 ./filebeat -e -c filebeat.yml
root 16992 1584 0 16:20 pts/0 00:00:00 grep –color=auto filebeat
[root@node01 filebeat-8.9.0-linux-x86_64]# kill -9 1492 #kill 掉filebeat 进程
[root@node01 filebeat-8.9.0-linux-x86_64]# ./filebeat -c filebeat_apache.yml
就会将日志同步到Logstash。
#输出到ElasticSearch
vim /data/software/filebeat-8.9.0-linux-x86_64/filebeat.yml
我们可以通过配置,将修改成如下所示
filebeat.inputs:
– type: log
enabled: true
paths:
– /data/software/filebeat-8.9.0-linux-x86_64/logs/*.log
tags: [“web”, “test”]
fields:
from: test-web
fields_under_root: false
setup.template.settings:
index.number_of_shards: 1
output.elasticsearch:
hosts: [“172.20.26.204:9200”]
启动成功后,我们就能看到它已经成功连接到es了
我们到刚刚的 logs文件夹向 a.log文件中添加内容
[root@node01 ~]# cd /data/software/filebeat-8.9.0-linux-x86_64/logs/
[root@node01 logs]# echo “hello mogublog” >> a.log
在ES中,我们可以看到,多出了一个 filebeat的索引库
然后我们浏览对应的数据,看看是否有插入的数据内容
启动命令
./filebeat -e -c mogublog-es.yml
./filebeat -e -c mogublog-es.yml -d “publish”
参数说明
-e:输出到标准输出,默认输出到syslog和logs下
-c:指定配置文件
-d:输出debug信息
设置开机启动
[root@node01 sh]# vim /data/sh/filebeat.sh #创建filebeat服务启动脚本
#!/bin/bash
cd /data/software/filebeat-8.9.0-linux-x86_64
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &

保存退出
chmod +x /data/sh/filebeat.sh
vim /etc/rc.d/rc.local #/data/sh/filebeat.sh将添加到开机启动

chmod +x /etc/rc.d/rc.local
systemctl restart rc-local.service
systemctl status rc-local.service
五、ELK收集Nginx的json日志
思路:
1、将nginx中的日志以json格式记录
2、filebeat采的时候说明是json格式
3、传入es的日志为json,那么显示在kibana的格式也是json,便于日志管理
1、配置nginx的日志以json格式记录
#修改/etc/nginx/nginx.conf配置文件,加入以下内容,yml文件注意缩进
log_format json ‘{ “time_local”: “$time_local”, ‘
‘”remote_addr”: “$remote_addr”, ‘
‘”referer”: “$http_referer”, ‘
‘”request”: “$request”, ‘
‘”status”: $status, ‘
‘”bytes”: $body_bytes_sent, ‘
‘”agent”: “$http_user_agent”, ‘
‘”x_forwarded”: “$http_x_forwarded_for”, ‘
‘”up_addr”: “$upstream_addr”,’
‘”up_host”: “$upstream_http_host”,’
‘”upstream_time”: “$upstream_response_time”,’
‘”request_time”: “$request_time”‘
‘ }’;
access_log /var/log/nginx/access.log json;
#重启nginx服务
systemctl restart nginx.service
#再次进行压测&&查看nginx日志是否记录显示为json格式的键值对&&查看可知已是json格式
ab -n 100 -c 100 http://172.20.26.204/
tail -f /var/log/nginx/access.log
2、filebeat采的时候说明是json格式
#备份filebeat配置文件到/root目录下
[root@master soft]# cp /etc/filebeat/filebeat.yml /root/
#修改配置文件
cat > /etc/filebeat/filebeat.yml <<EOF
filebeat.inputs: #输入
– type: log #输入类型
enabled: true
paths: #filebeat采集路径
– /var/log/nginx/access.log
#说明input的日志是json格式
json.keys_under_root: true
json.overwrite_keys: true
setup.kibana:
host: “172.20.26.204:5601”
output.elasticsearch: #输出
hosts: [“172.20.26.204:9200”]
index: “nginx-%{[beat.version]}-%{+yyyy.MM}”
setup.template.name: “nginx”
setup.template.pattern: “nginx-*”
setup.template.enabled: false
setup.template.overwrite: true
EOF



六、ELK收集Nginx正常日志和错误日志
#编辑filebeat的配置文件,在/etc/filebeat/filebeat.yml加入以下配置
#filebeat输入配置
filebeat.inputs:
– type: log
enabled: true
paths:
– /var/log/nginx/access.log
#输入为json格式
json.keys_under_root: true
json.overwrite_keys: true
#对正常日志加上access标签
tags: [“access”]
– type: log
enabled: true
paths:
– /var/log/nginx/error.log
#对错误日志加上error标签
tags: [“error”]
setup.kibana:
host: “172.20.26.204:5601”
#filebeat输入配置
output.elasticsearch:
hosts: [“172.20.26.204:9200”]
#index: “nginx-%{[beat.version]}-%{+yyyy.MM}”
indices:
#将输入带有access标签输出为这个索引
– index: “nginx-access-%{[beat.version]}-%{+yyyy.MM}”
when.contains:
tags: “access”
#将输入带有error标签输出为这个索引
– index: “nginx-error-%{[beat.version]}-%{+yyyy.MM}”
when.contains:
tags: “error”
setup.template.name: “nginx”
setup.template.pattern: “nginx-*”
setup.template.enabled: false
setup.template.overwrite: true
#保存退出&&重启filebeat服务&&重新压测数据(访问不存在页面)即可查看到现象


七、ELK收集Tomcat日志
#安装成功tomcat&&启动tomcat&&访问测试(1查看8080默认端口是否开启,2通过IP:8080在浏览器访问观察是否有tomcat官网页面)
yum install tomcat tomcat-webapps tomcat-admin-webapps tomcat-docs-webapp tomcat-javadoc -y
systemctl start tomcat
#修改tomcat日志为json格式
vim /etc/tomcat/server.xml
##删除第139行
139 pattern=”%h %l %u %t "%r" %s %b” />
##将以下配置放入到139行
pattern=”{"clientip":"%h","ClientUser":"%l","authenticated":"%u","AccessTime":&quo t;%t","method":"%r","status":"%s","SendBytes":"%b","Query?string":"%q","partn er":"%{Referer}i","AgentVersion":"%{User-Agent}i"}”/>
##保存退出&&重启服务&&查看日志
systemctl restart tomcat
tail -f /var/log/tomcat/localhost_access_log.2020-09-05.txt
#修改filebeat.yml配置文件
vim /etc/filebeat/filebeat.yml
#在filebeat.inputs:下增加以下配置
##############tomcat##############
– type: log
enabled: true
paths:
– /var/log/tomcat/localhost_access_log.*.txt
json.keys_under_root: true
json.overwrite_keys: true
tags: [“tomcat”]
#filebeat.outputs:下增加以下配置
– index: “tomcat-access-%{[beat.version]}-%{+yyyy.MM}”
when.contains:
tags: “tomcat”
#重启服务即可查看到
systemctl restart filebeat.service


八、ELK收集docker日志
安装docker
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.ustc.edu.cn/docker-ce/linux/centos/docker-ce.repo
sed -i ‘s#download.docker.com#mirrors.tuna.tsinghua.edu.cn/docker-ce#g’ /etc/yum.repos.d/docker-ce.repo
yum install docker-ce -y
systemctl start docker
#添加阿里云仓库加速,每个人都可以自己到阿里云官网获取自己的加速registry-mirrors
tee /etc/docker/daemon.json <<-‘EOF’
{
“registry-mirrors”: [“https://76rdsfoe.mirror.aliyuncs.com”]
}
EOF
systemctl daemon-reload
systemctl restart docker
#登录docker(阿里云-》容器镜像服务-》访问凭证,该路径下设定固定密码,用作登录docker)
sudo docker login –username=jeffii registry.cn-hangzhou.aliyuncs.com
#紧接着,输入密码你刚设置的密码即可。若一下拉取镜像时提示connect refused的话,可重新登录下docker
#拉取ng镜像
docker pull nginx
docker run –name nginx -p 80:80 -d nginx
docker ps
docker logs -f nginx
九、配置filebeat收集单个docker日志
#获取容器id
/var/lib/docker/containers/
#编辑filebeat.yml配置文件
filebeat.inputs:
– type: docker
containers.ids:
– ‘e5e90adc1871e0689f5346fac071db90cb462941c8ff4444ceecaec5772bbafa’
tags: [“docker-nginx”]
output.elasticsearch:
hosts: [“172.20.26.204:9200”]
index: “docker-nginx-%{[beat.version]}-%{+yyyy.MM}”
setup.template.name: “docker”
setup.template.pattern: “docker-*”
setup.template.enabled: false
setup.template.overwrite: true
十、modules日志收集
官方参考:
https://www.elastic.co/guide/en/beats/filebeat/6.4/configuration-filebeat-modules.html
十一、使用redis作为缓存收集日志
1、redis安装
复制代码#配置epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
#安装redis
yum install redis -y
#修改redis配置文件
vim /etc/redis.conf
bind 172.20.26.204
#启动redis服务
systemctl start redis
2、修改filebeat的配置文件
复制代码#把nginx的日志格式改为json
#修改filebeat的主配置文件
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
– type: log
enabled: true
paths:
– /var/log/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
tags: [“access”]
– type: log
enabled: true
paths:
– /var/log/nginx/error.log
tags: [“error”]
output.redis:
hosts: [“172.20.26.204”]
keys:
– key: “nginx_access”
when.contains:
tags: “access”
– key: “nginx_error”
when.contains:
tags: “error”
setup.template.name: “nginx”
setup.template.pattern: “nginx_*”
setup.template.enabled: false
setup.template.overwrite: true
#重启filebeat服务
systemctl restart filebeat
3、检查redis能否收集日志
复制代码#连接redis
redis-cli -h 172.20.26.204
#使用命令检查
172.20.26.204:6379> keys *
1) “nginx_access”
172.20.26.204:6379> LLEN nginx_access
(integer) 18
172.20.26.204:6379> type nginx_access
list
172.20.26.204:6379> LRANGE nginx_access 1 18
1) “{“@timestamp”:”2020-09-06T09:46:56.057Z”,”@metadata”:{“beat”:”filebeat”,”type”:”doc”,”version”:”6.4.2″},”source”:”/var/log/nginx/access.log”,”offset”:21682,”tags”:[“access”],”prospector”:{“type”:”log”},”beat”:{“name”:”localhost”,”hostname”:”localhost”,”version”:”6.4.2″},”json”:{},”message”:”192.168.88.102 – – [06/Sep/2020:17:46:50 +0800] \”GET / HTTP/1.1\” 304 0 \”-\” \”Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36\” \”-\””,”input”:{“type”:”log”},”host”:{“name”:”localhost”}}”
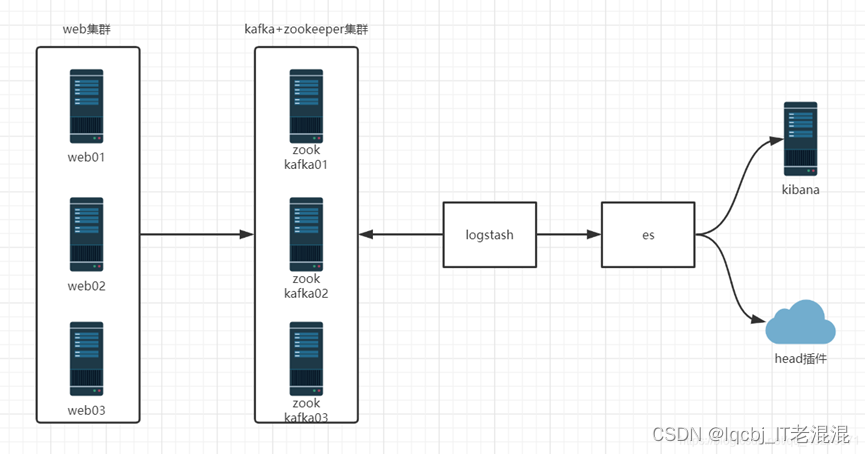
十二、使用Kafka做缓存收集日志
结构图
kafka原理图

kafka是分布式发布-订阅消息系统
zookeeper:存储了一些关于 consumer 和 broker 的信息
producer 直接连接 Broker
zookeeper:保存了topic相关配置,例如topic列表,每个topic的 partition数量、副本的位置,这些分区信息及与Broker的对应关系所有, topic的访问控制信息也是由zookeeper维护的,记录消息分区与consumer之间的关系
broker:多个broker,其中一个会被选举为控制器。从多个broker中选出控制器,这个工作就是zookeeper负责的控制器负责管理整个集群所有分区和副本的控制,例如某个分区的leader故障了,控制器会选择新的leader
Producer:直接连接Broker
partition:一个topic可以分为多个partion,每个partion是一个有序的队列。
Broker:缓存代理,kafka集群中的一台或多台服务器统称broker,存储topic
topic:kafka处理资源的消息源(feeds of messages)的不同分类
原文地址:https://blog.csdn.net/lqcbj/article/details/135933228
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_66103.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!