本文介绍: 摘要:http基本原理,http报文解析,http请求过程
Python爬虫逆向系列(更新中):http://t.csdnimg.cn/5gvI3
HTTP 基本原理
在本节中,我们会详细了解 HTTP 的基本原理,了解在浏览器中敲入 URL 到获取网页内容之间发生了什么。了解了这些内容,有助于我们进一步了解爬虫的基本原理。
1.URI 和 URL
这里我们先了解一下 URI 和 URL,URI 的全称为 Uniform Resource Identifier,即统一资源标志符,URL 的全称为 Universal Resource Locator,即统一资源定位符。
举例来说,https://github.com/favicon.ico,它是一个 URL,也是一个 URI。即有这样的一个图标资源,我们用 URL/URI 来唯一指定了它的访问方式,这其中包括了访问协议 https、访问路径(即根目录)和资源名称 favicon.ico。通过这样一个链接,我们便可以从互联网上找到这个资源,这就是 URL/URI。
URL 是 URI 的子集,也就是说每个 URL 都是 URI,但不是每个 URI 都是 URL。那么,怎样的 URI 不是 URL 呢?URI 还包括一个子类叫作 URN,它的全称为 Universal Resource Name,即统一资源名称。URN 只命名资源而不指定如何定位资源,比如 urn:isbn:0451450523 指定了一本书的 ISBN,可以唯一标识这本书,但是没有指定到哪里定位这本书,这就是 URN。URL、URN 和 URI 的关系可以用图表示。

但是在目前的互联网,URN 的使用非常少,所以几乎所有的 URI 都是 URL,所以一般的网页链接我们可以称之为 URL,也可以称之为 URI,我个人习惯称之为 URL。
2.超文本
3.HTTP 和 HTTPS
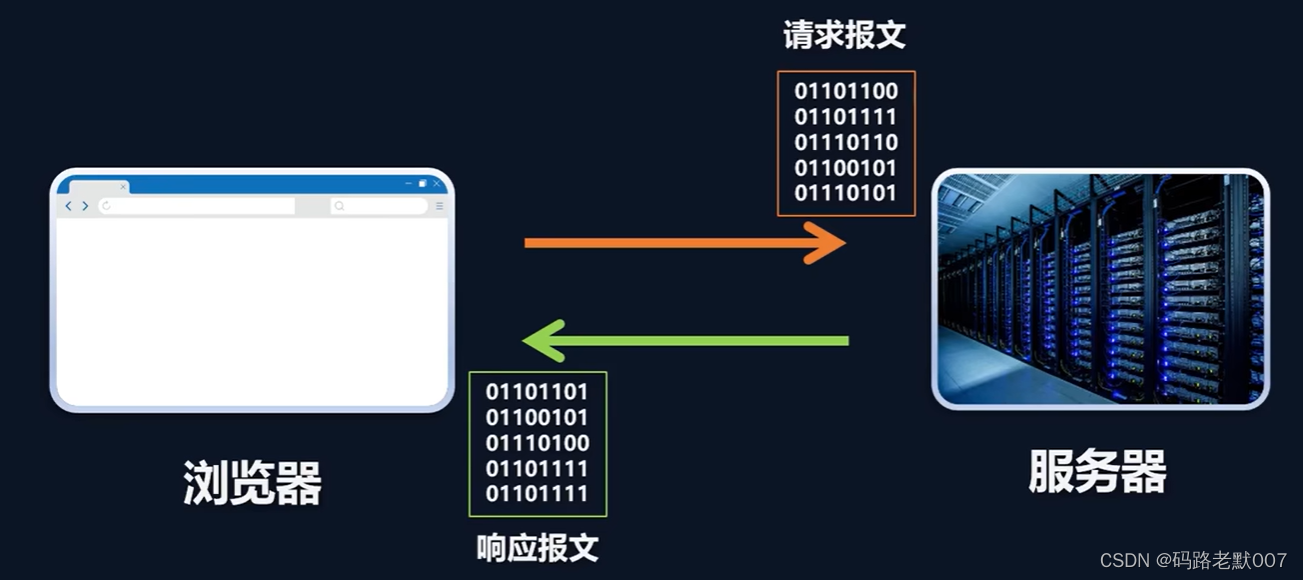
4. HTTP 请求过程
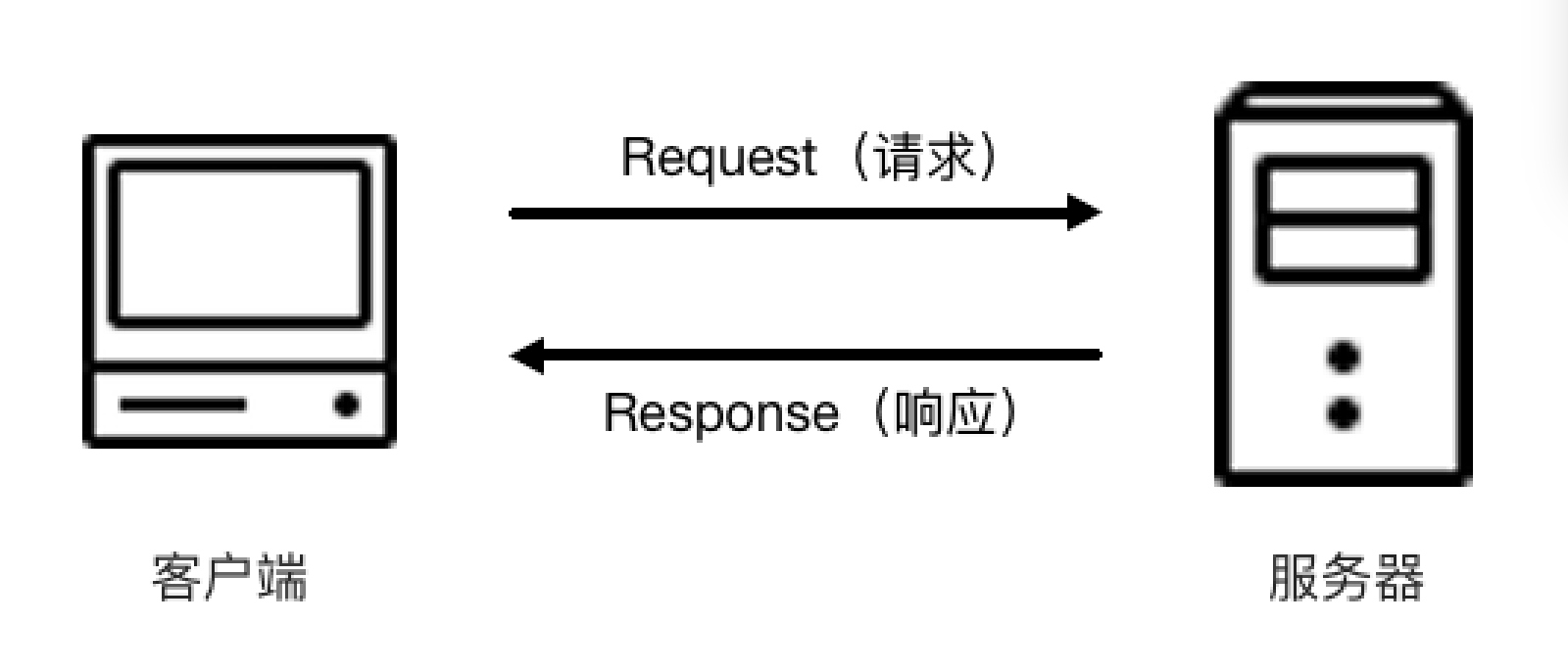

请求
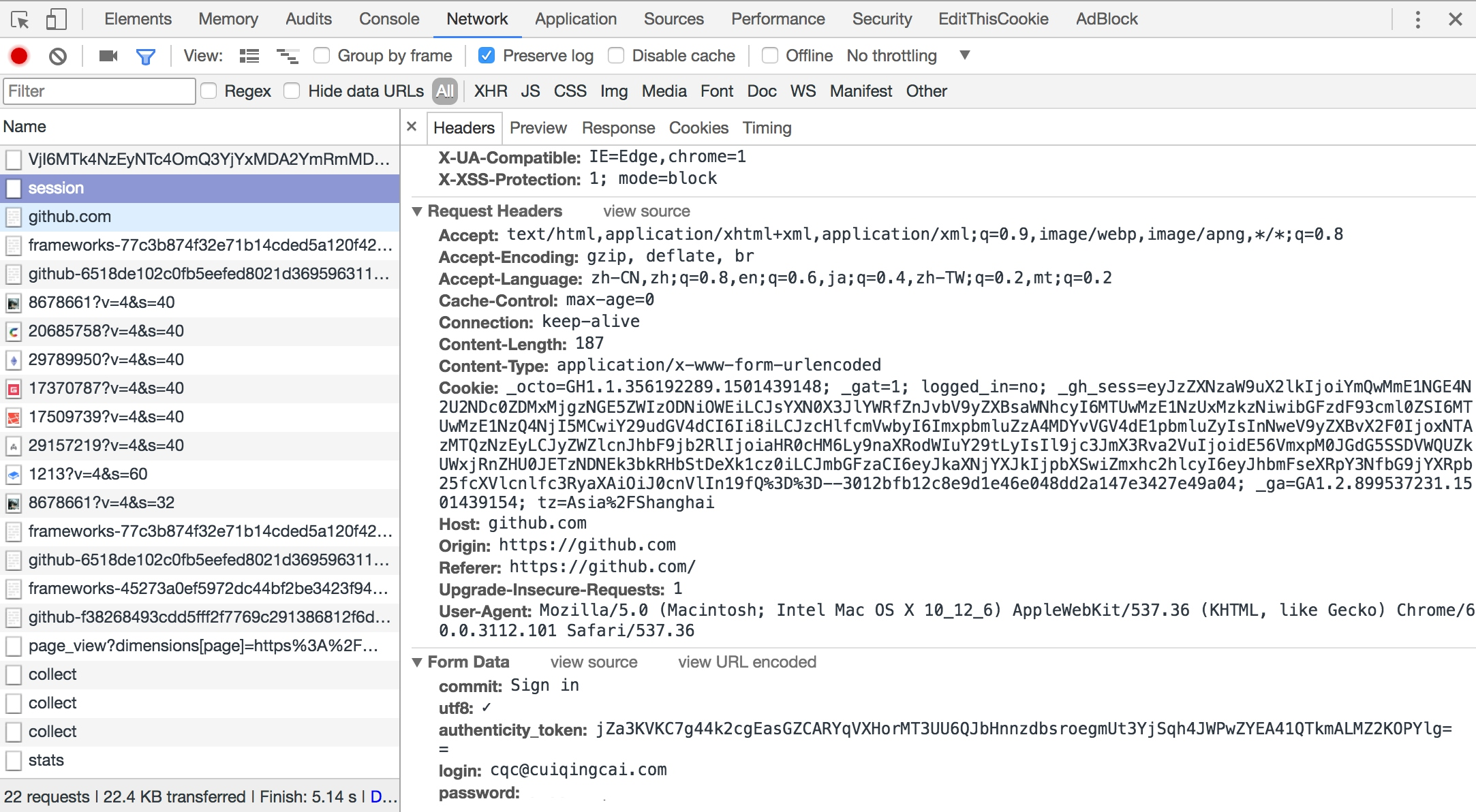
响应
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。