本文介绍: 一步一步、简单易懂的拆解ClickHouse数据库的PreWhere所作的优化
相信看过ClickHouse性能测试报告的同学都很震惊于他超高的OLAP查询性能。于是下一步开始搜索“ClickHouse性能为什么高”看到了例如:列存储、数据压缩、并行处理、向量化引擎 等等一些关键词,对于我们一般人来说,并没有解答心中的疑惑:ClickHouse性能为什么高? 于是想写几篇博文,用通俗、简单的实例和大家一起探讨一下这个问题,希望能通过博文和大家的探讨解答这个疑惑! 针对OLAP类的查询最简单的优化方式就是减少数据扫描范围,故而我们以此作为开篇。
问题: 有一个表(tab01)有10个int类型的字段(col1,col2,col3…col10),这个表中有十亿条数据。
为了简单假定该表没有主键和索引,在本篇中也不考虑任何的数据压缩。
需要完成如下查询:
方案一:行存储
如果该表以行存储的方式存储为一个文件:tab01.dat , 每条数据40字节,那么整个文件大小为40GB,完成上述问题的代码逻辑如下:
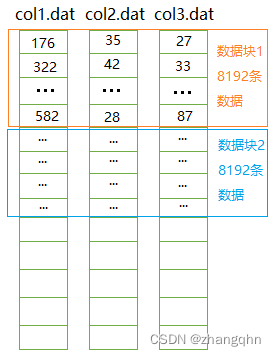
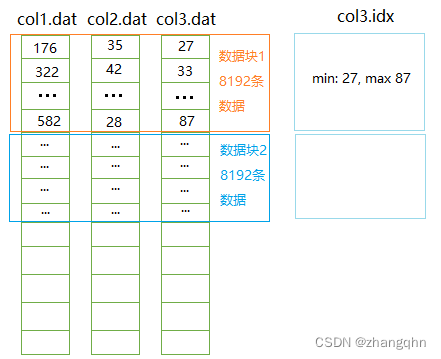
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。