本文介绍: Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发并于2011年开源。它主要用于解决大规模数据的实时流式处理和数据管道问题。Kafka是一个分布式的发布-订阅消息系统,可以快速地处理高吞吐量的数据流,并将数据实时地分发到多个消费者中。Kafka消息系统由多个broker(服务器)组成,这些broker可以在多个数据中心之间分布式部署,以提供高可用性和容错性。Kafka的基本架构由生产者、消费者和主题(topic)组成。
目录
Kafka介绍
消息队列的作用
消息队列的优势
应用解耦
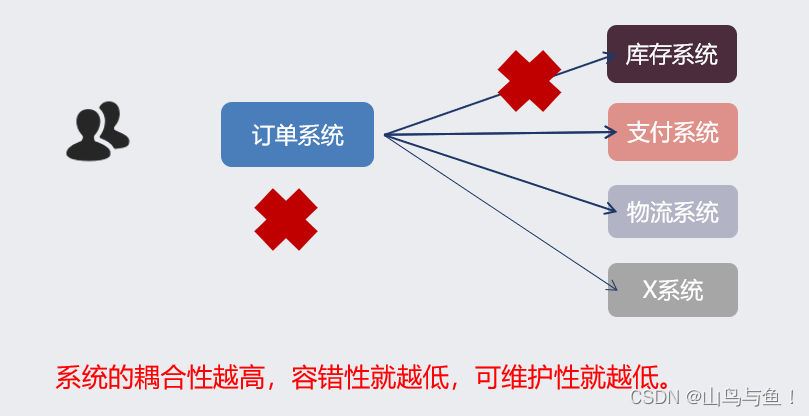

异步提速


削峰填谷



为什么要用Kafka
Kafka下载安装



Kafka快速上手(单机体验)
1. 启动zookeeper服务

2. 启动kafka服务

3. 简单收发消息






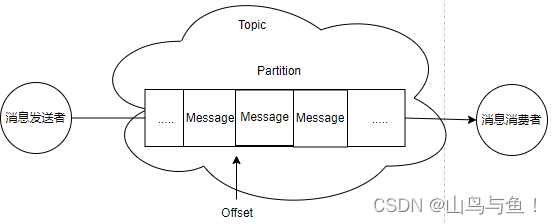
Kakfa的消息传递机制
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






