本文介绍: 现有的基于 ID 嵌入的方法,虽然只需要一个前向推理,但面临挑战:它们要么需要对众多模型参数进行广泛的微调,缺乏与社区预训练模型的兼容性,要么无法保持高人脸保真度为了解决这些限制,我们引入了 InstantID,这是一种强大的基于扩散模型的解决方案。我们的即插即用模块擅长仅使用单个面部图像处理各种风格的图像个性化,同时确保高保真度为此,我们设计了一种新的,通过施加强语义和弱的空间条件,将人脸和地标图像与文本提示相结合,引导图像生成。
project:https://github.com/InstantID/InstantID
单位:小红书,北大

理解
很有意义的一篇文章,关注于人脸身份信息的保持来控制包含人物的图像生成;通过人脸识别网络的嵌入来保证身份一致性和细节,面部粗糙关键点过controlnet保持空间pose;支持非常丰富的下游任务
问题:
摘要
Introduction
贡献
Related Work
Text-to-image Diffusion Models
不详细介绍了
Subject-driven Image Generation
ID Preserving Image Generation
Method
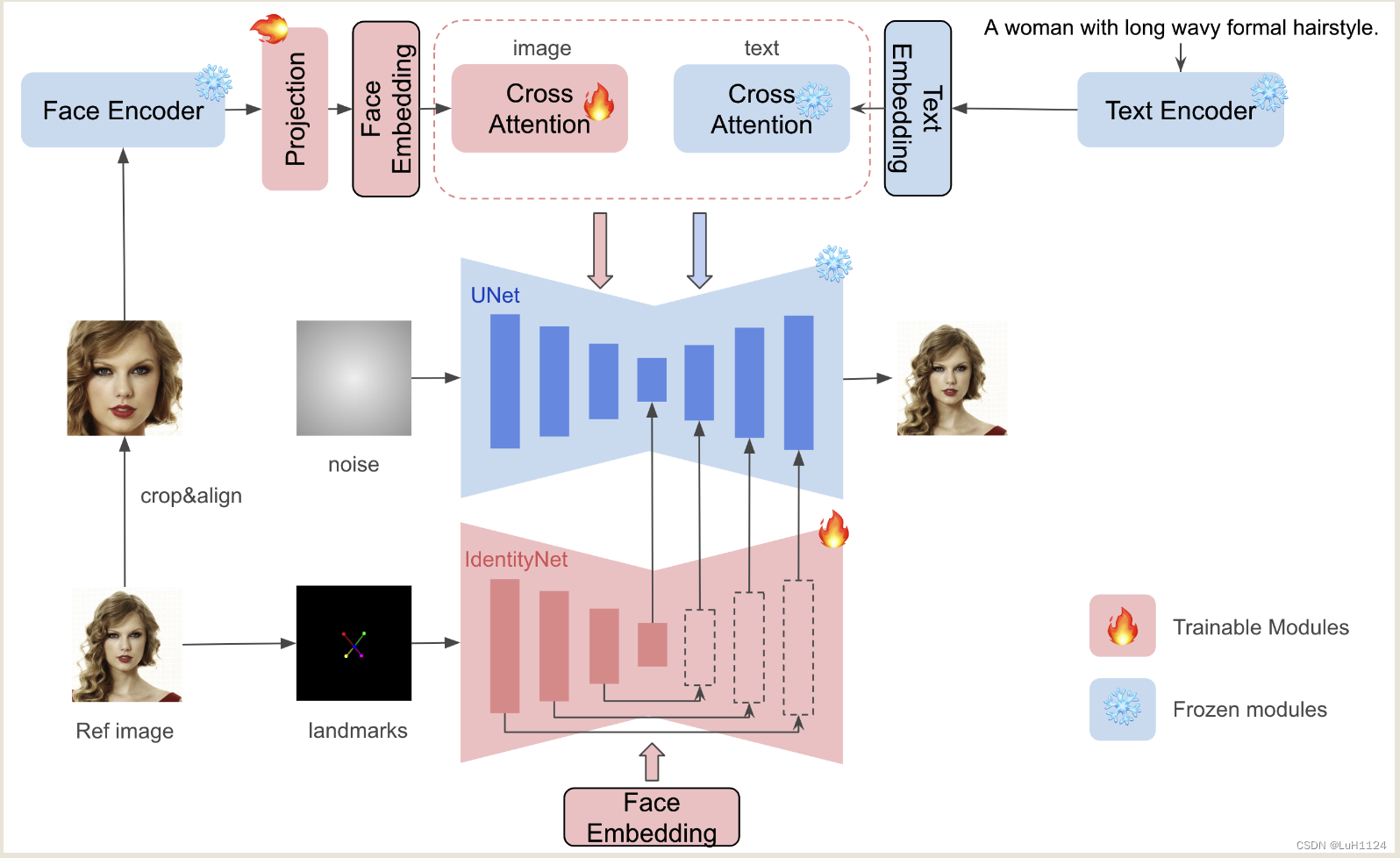
实验

定性实验

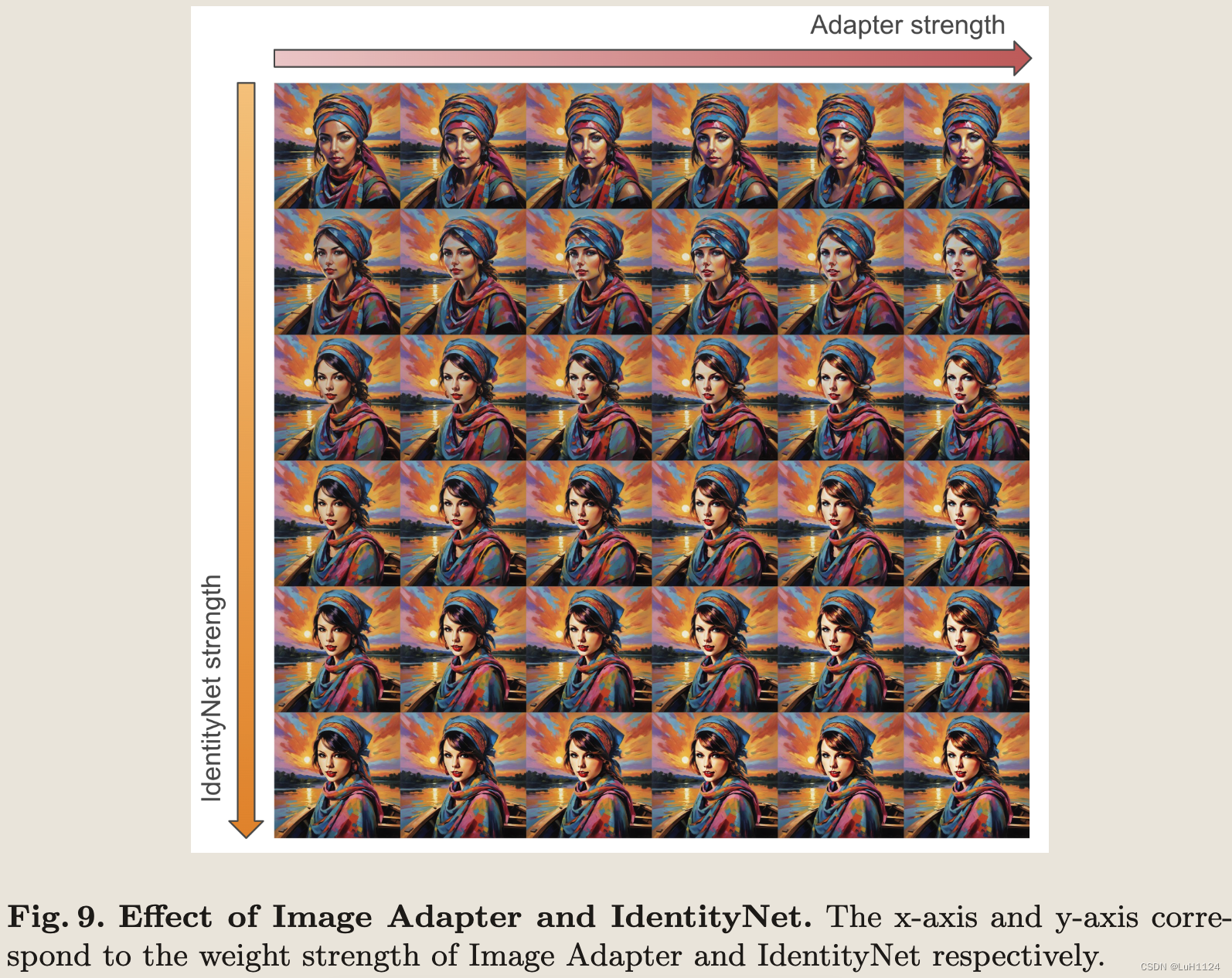
消融实验

与先前方法的对比



富有创意的更多任务
新视角合成

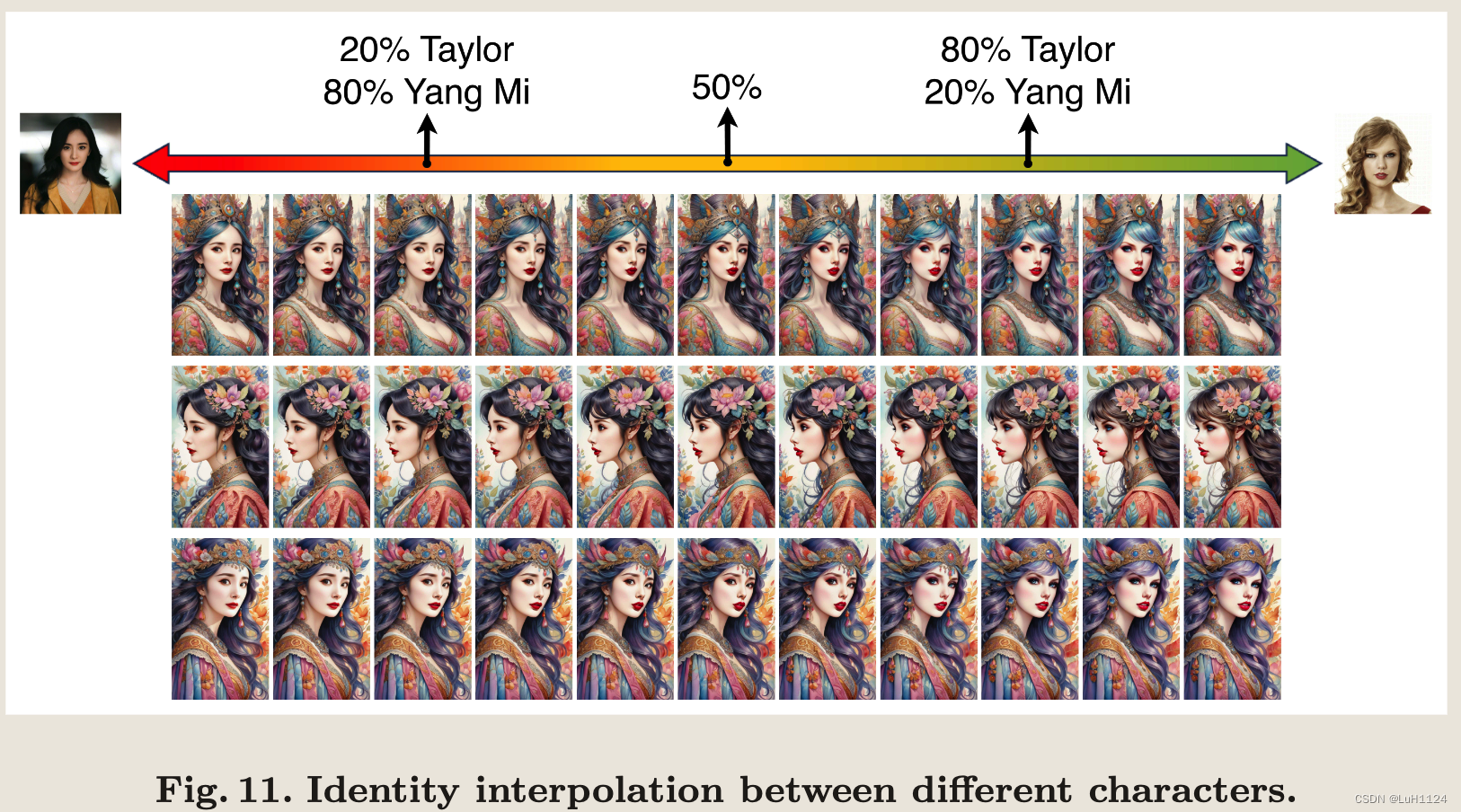
身份插值
多身份区域控制合成

结论和未来工作
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。