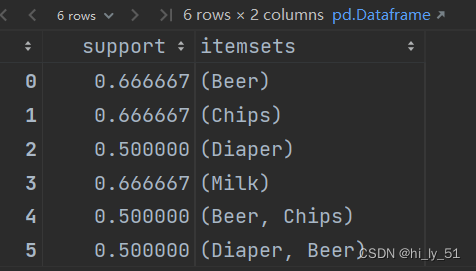
本文介绍: 根据每个数据集特性找到其分割符,如该数据集中的分隔符为,日常中见到的购物数据往往是所购买的数据而不是全部数据。后续在选择频繁项集与确定规则时不需要其他无关属性。数据集中都是字符串组成的,需要转换成数值编码。将展示不需要的字段属性拿出来。lift值越大则相关性越强。
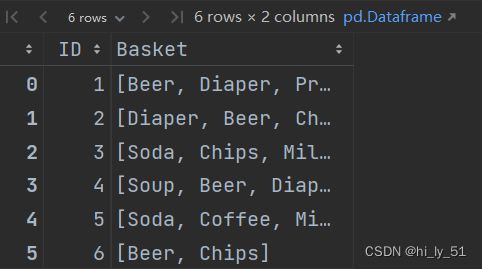
日常中见到的购物数据往往是所购买的数据而不是全部数据
数据集中都是字符串组成的,需要转换成数值编码
将展示不需要的字段属性拿出来
根据每个数据集特性找到其分割符,如该数据集中的分隔符为,




声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







