本文介绍: 为了解决这些问题,我们有一个非常成熟的方式。Docker 是一个容器管理系统,它可以向虚拟机一样运行多个”虚拟机”(容器),并构成一个集群。因为虚拟机会完整的虚拟出一个计算机来,所以会消耗大量的硬件资源且效率低下,而 Docker 仅提供一个独立的、可复制的运行环境,实际上容器中所有进程依然在主机上的内核中被执行,因此它的效率几乎和主机上的进程一样(接近100%)。本教程将会以 Docker 为底层环境来描述 Hadoop 的使用,如果你不会使用 Docker 并且不了解更好的方式,请学习。
由于 Hadoop 是为集群设计的软件,所以我们在学习它的使用时难免会遇到在多台计算机上配置 Hadoop 的情况,这对于学习者来说会制造诸多障碍,主要有两个:
为了解决这些问题,我们有一个非常成熟的方式 Docker。
Docker 是一个容器管理系统,它可以向虚拟机一样运行多个”虚拟机”(容器),并构成一个集群。因为虚拟机会完整的虚拟出一个计算机来,所以会消耗大量的硬件资源且效率低下,而 Docker 仅提供一个独立的、可复制的运行环境,实际上容器中所有进程依然在主机上的内核中被执行,因此它的效率几乎和主机上的进程一样(接近100%)。
本教程将会以 Docker 为底层环境来描述 Hadoop 的使用,如果你不会使用 Docker 并且不了解更好的方式,请学习 Docker 教程。
Docker 部署
进入 Docker 命令行之后,拉取一个 Linux 镜像作为 Hadoop 运行的环境,这里推荐使用 CentOS 镜像(Debian 和其它镜像暂时会出现一些问题)。
然后通过 docker images 命令可以查看到当前本地的镜像:

创建容器
配置 Java 与 SSH 环境

Hadoop 安装
下载 Hadoop
创建 Hadoop 单机容器
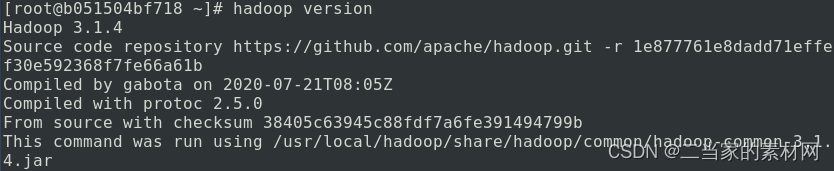 到这里,说明你的 Hadoop 单机版已经配置成功了。
到这里,说明你的 Hadoop 单机版已经配置成功了。声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。