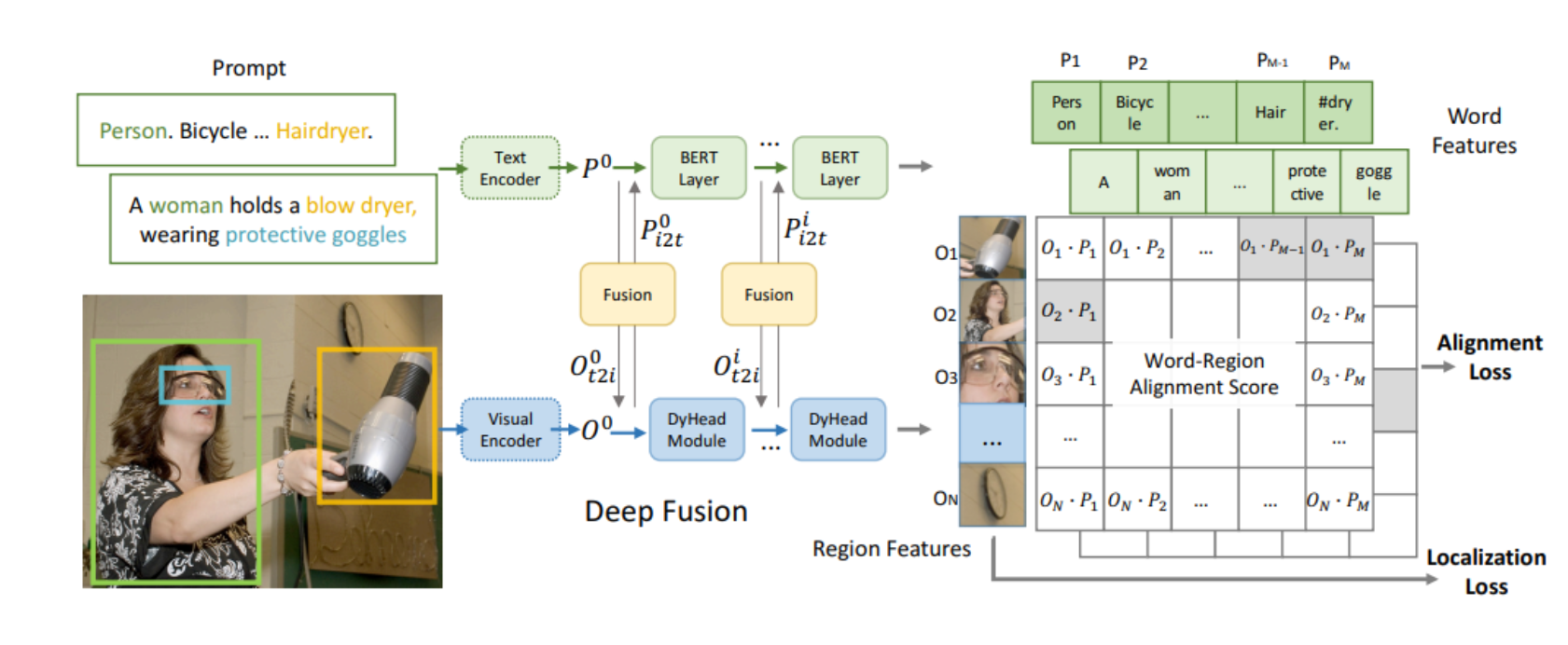
本文介绍: 这篇论文的标题是“Grounding Answers for Visual Questions Asked by Visually Impaired People”,作者是Chongyan Chen, Samreen Anjum, 和 Danna Gurari。论文的重点是在视觉问答(VQA)的领域内,引入了一个新的数据集:VizWiz-VQA-Grounding,这是第一个针对视障人士提出的视觉问题,并在视觉上定位答案的数据集。
一、论文速读
1.1 摘要
1.2 论文概要总结
相关工作
主要贡献
论文主要方法
实验数据
未来研究方向
二、论文精度
2.1 论文试图解决什么问题?
2.2 论文中提到的解决方案之关键是什么?
2.3 用于定量评估的数据集是什么?代码有没有开源?
2.4 下一步呢?有什么工作可以继续深入?
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。