本文介绍: 这篇文章于我而言最大的启发有四点:1. 基于对象存储执行分析需求的数据支持2. 基于对象存储执行分析需求的实践经验3. 使用对象调度器平衡数据检索和数据处理的资源使用,这种思路可以用在很多地方4. 基于对象存储性能存在下降(复杂的cache策略可以部分缓解,这里的研究很多),所以这里其实是成本和性能之间的权衡
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
刷完近N年内数据库顶会的时序数据库论文后,我开始把目光投向相关领域的基础方向,vldb2023这篇《Exploiting Cloud Object Storage for High-Performance Analytics》的名字听起来就是一个有趣的主题,且其涉及的内容也和云时序数据库系统关系颇深。
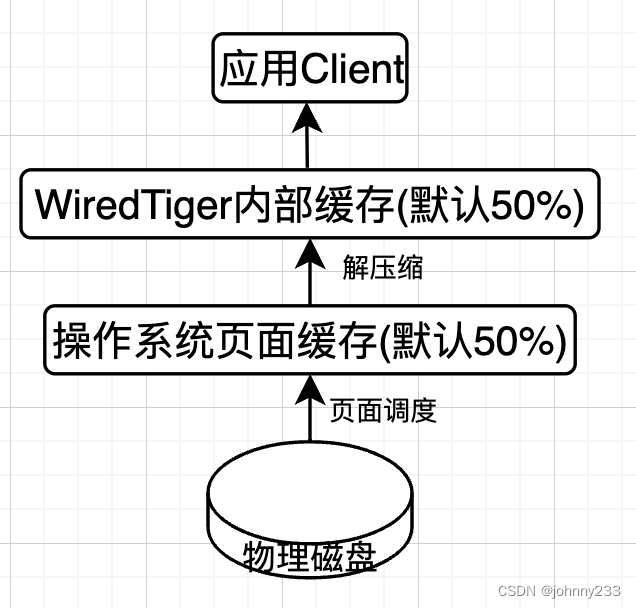
时序数据库本身可以认为是分析性负载,古典的列式存储引擎配合各种奇妙优化后的压缩算法使存储量可以达到原始数据量的百分之十以下(与数据类型有关)。在如今基础架构强调降本增效的大背景下,原本使用Cassandra,Hbase,mysql等不够成本效益的业务倾向于使用时序数据库。一般情况下强大的压缩能力我们认为可以带来成本的大幅度下降,但是在架构不够“弹性”的情况下却无法达到这一美好愿景,举个简单的例子,比如一台16C64G一块3.5T的物理机,分析性需求使得内存和CPU先行到达瓶颈,存储量却大片大片的空余,剩下的存储空间也无法被利用,想要在价格上做到有竞争力,必须提升存储利用率,这里有两个使用存算分离的必要因素:
基于上述考虑,这篇文章事实上是有工程意义的。
以AWS S3为例的对象存储基本特征
成本


时延



吞吐量

最优请求大小

Model for Cloud Storage Retrieval

CLOUD STORAGE INTEGRATION
线程模型概要设计

Object Scheduler
性能

结束语
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。