本文介绍: 如果在正则表达式中有不确定的匹配次数,这个正则在匹配字符串的时候可以分为贪婪和非贪婪两种模式#这样只会选择amnb, +?是取最小的满足匹配规则的# 想让一个小数进行匹配, 因为 . 在正则中是匹配任意字符功能,加个 ,让其功能消失# 放在[] 里 符号失去功能。
一. 正则表达式
1. 匹配次数相关的正则符号
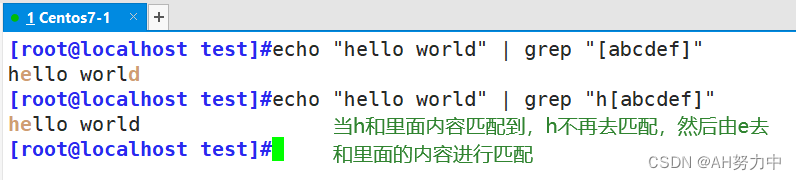
a. ‘+’ 一次或多次(至少一次) ,控制+ 前面元素的次数,看下面事例
b. ‘ * ‘ 任意次数
c. ‘ ? ‘ — 0次或者1次, 最多一次
d. { }
{ N } N次
{ M,N } M到N次
{M,}. 至少M次
{ ,N } 最次
2. 贪婪和非贪婪
1.定义:
2. 贪婪(默认)
3.非贪婪( +?, *?, ??, {M,N}?, {M,}?, {,N}? )
3. match 和 fullmatch
match(正则表达式, 字符串) — 匹配字符串开头
4. 其他符号
1. 分组 ()
1.自动捕获:findall 函数支持自动捕获(findall在获取匹配结果的时候自动获取分组匹配到的结果)
2. 分支 ‘ | ‘
3. 转义字符 在有特殊意义的符号前面加 , 让其功能消失变成一个普通符号。 注意:单独存在有特殊意义(除了d s w等)的符号放在[ ]里面他的功能也会消失,变成普通符号 ( ‘-’ 号只能放在最前或最后面,其他地方要加 – , ^ 也是)
4. 检测类符号 (先匹配,如果匹配成功再检测,检测类所在的位置是否符合要求)
5. re模块
1. fullmatch 、 match、 search
2.findall 、finditer
3. splite(正则表达式,字符串)
4.sub
5.正则参数
a. 1. 忽略大小写 匹配的时候让同一个字母的大写和小写相同
a. 2. 加参数 I (ignorecase) from re import I 也是忽略大小写
b. 单行匹配 (默认是多行匹配)
如何做到 又忽略大小写 又转为单行匹配
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。