本文介绍: Solr 全文检索 之 为索引库添加中文分词器
Solr 全文检索 之 为索引库添加中文分词器
添加中文分词器
1、添加中文分词器的 jar 包
将 Solr 的 contribanalysis-extraslucene-libs 文件夹
目录下的 lucene-analyzers-smartcn-x.x.x.jar 包
复制到 Solr的 serversolr-webappwebappWEB-INFlib 目录下。
如果要添加第三方中文分词器,只要同样将JAR包复制到WEB-INFlib目录下。

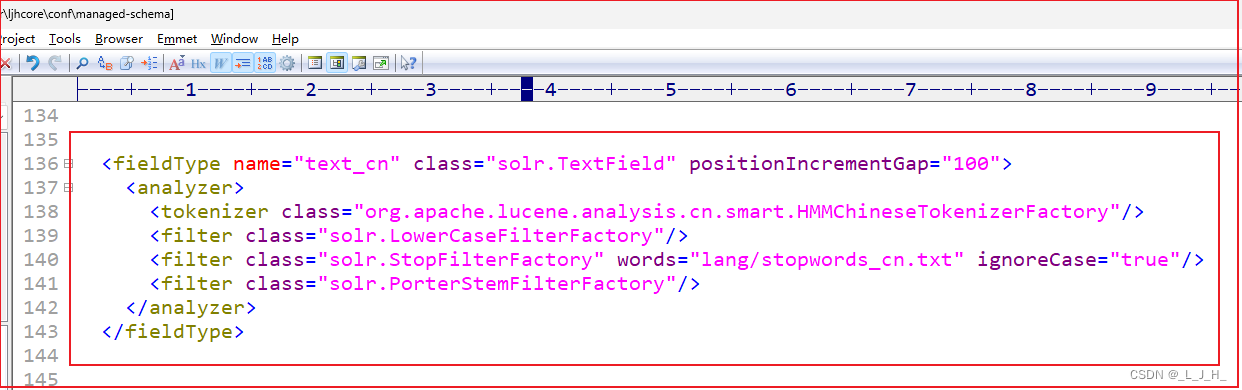
2、修改 managed-schema 配置文件

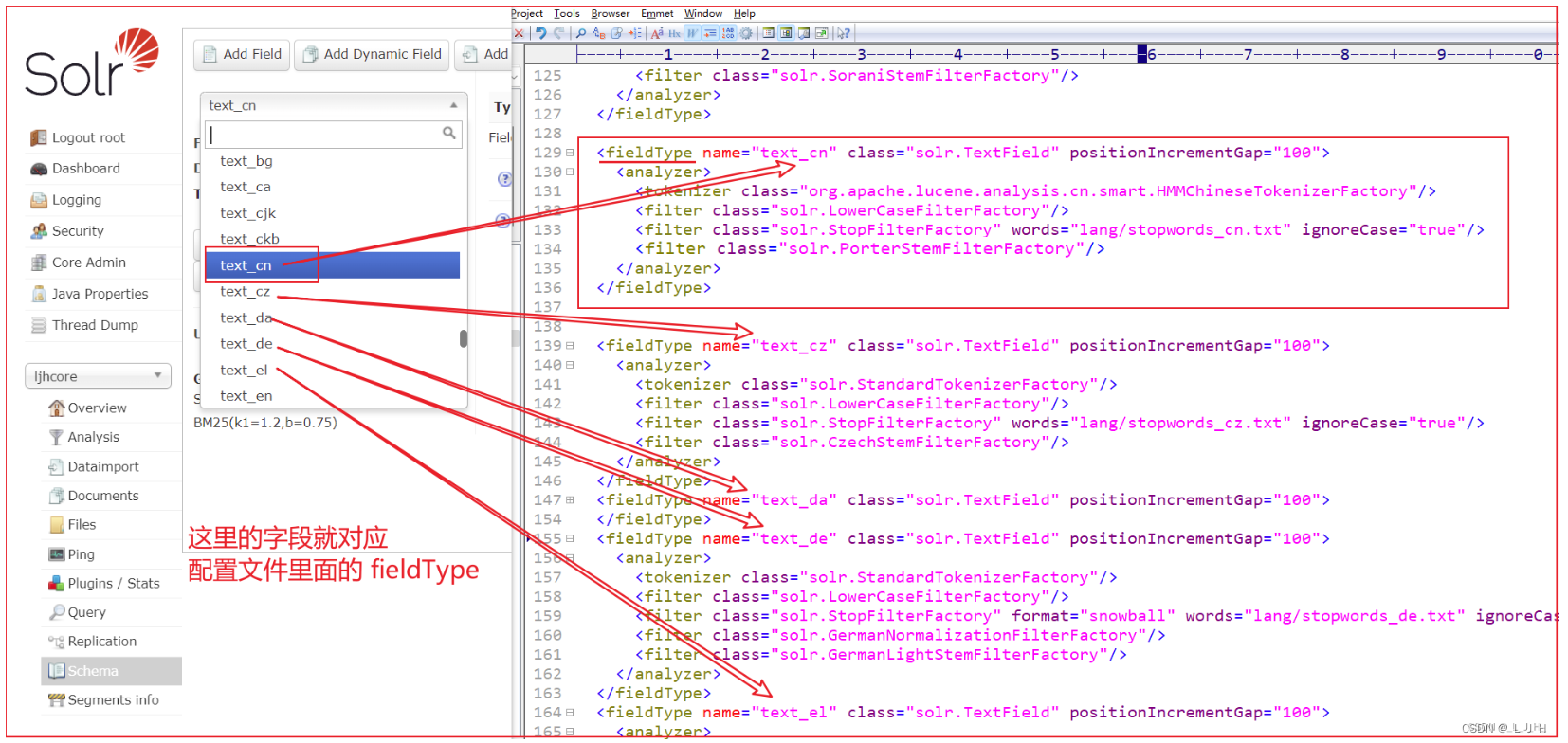
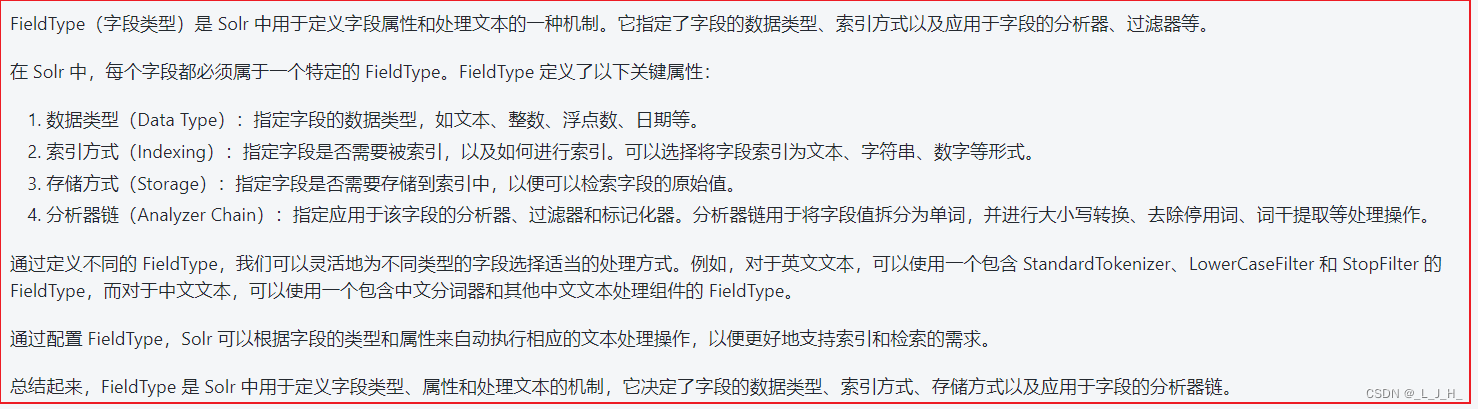
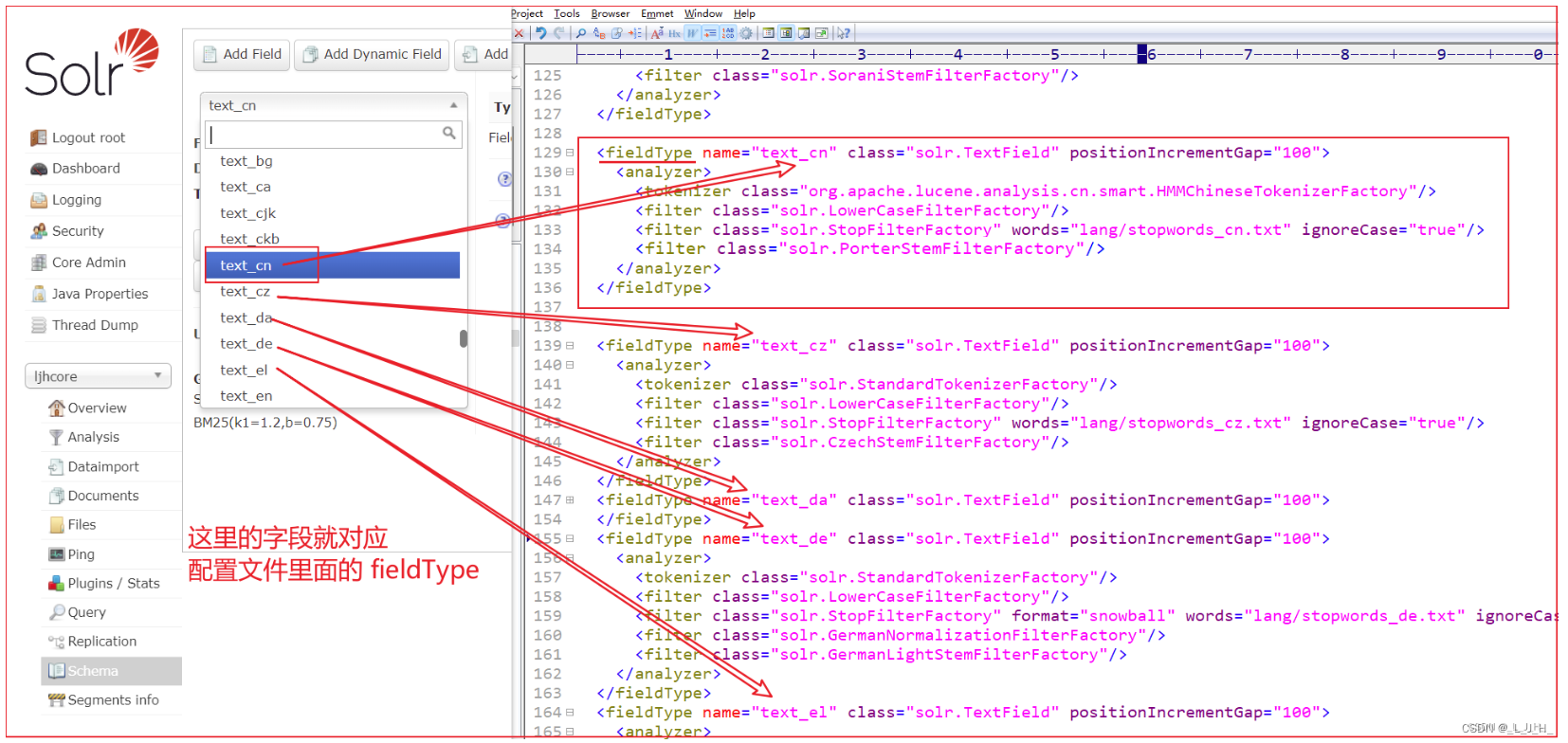
什么是 fieldType
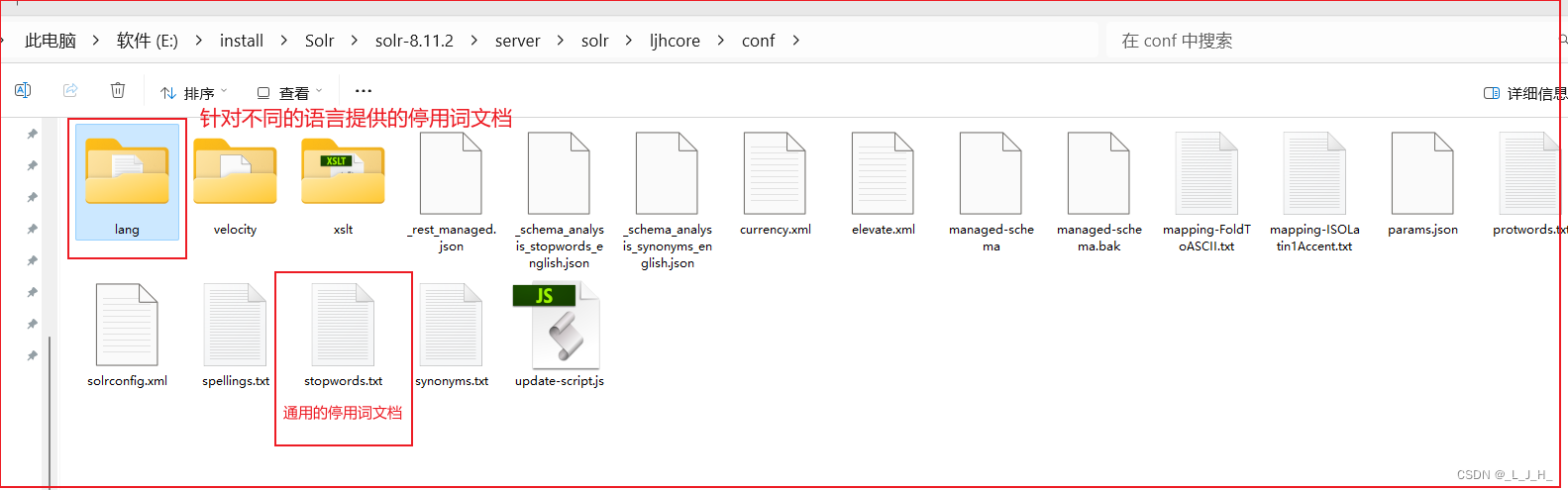
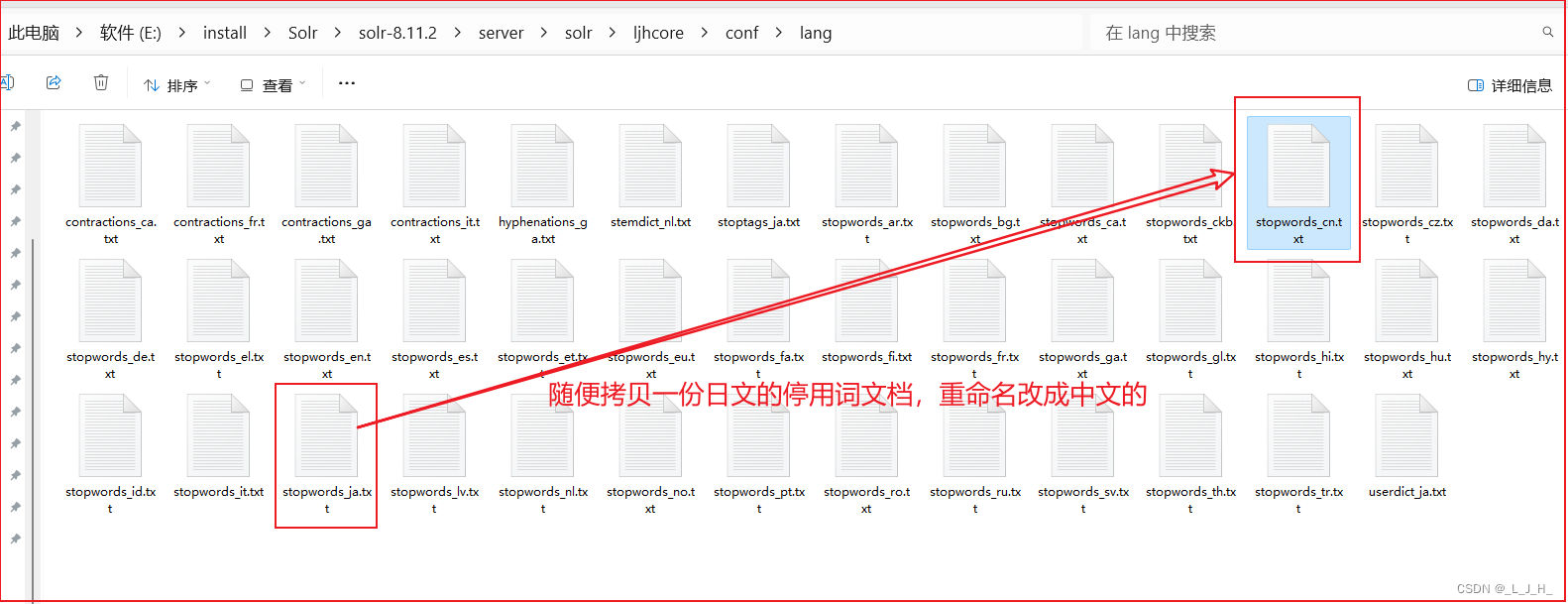
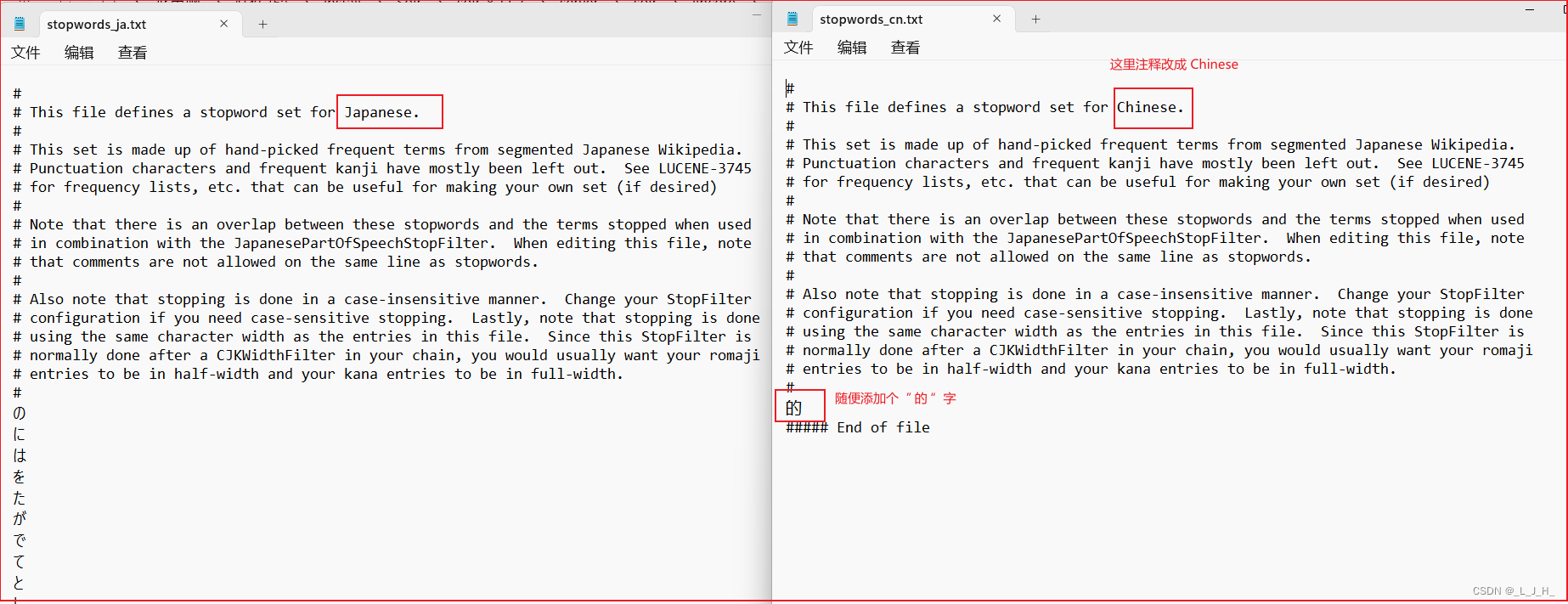
3、添加 停用词文档
4、重启 solr
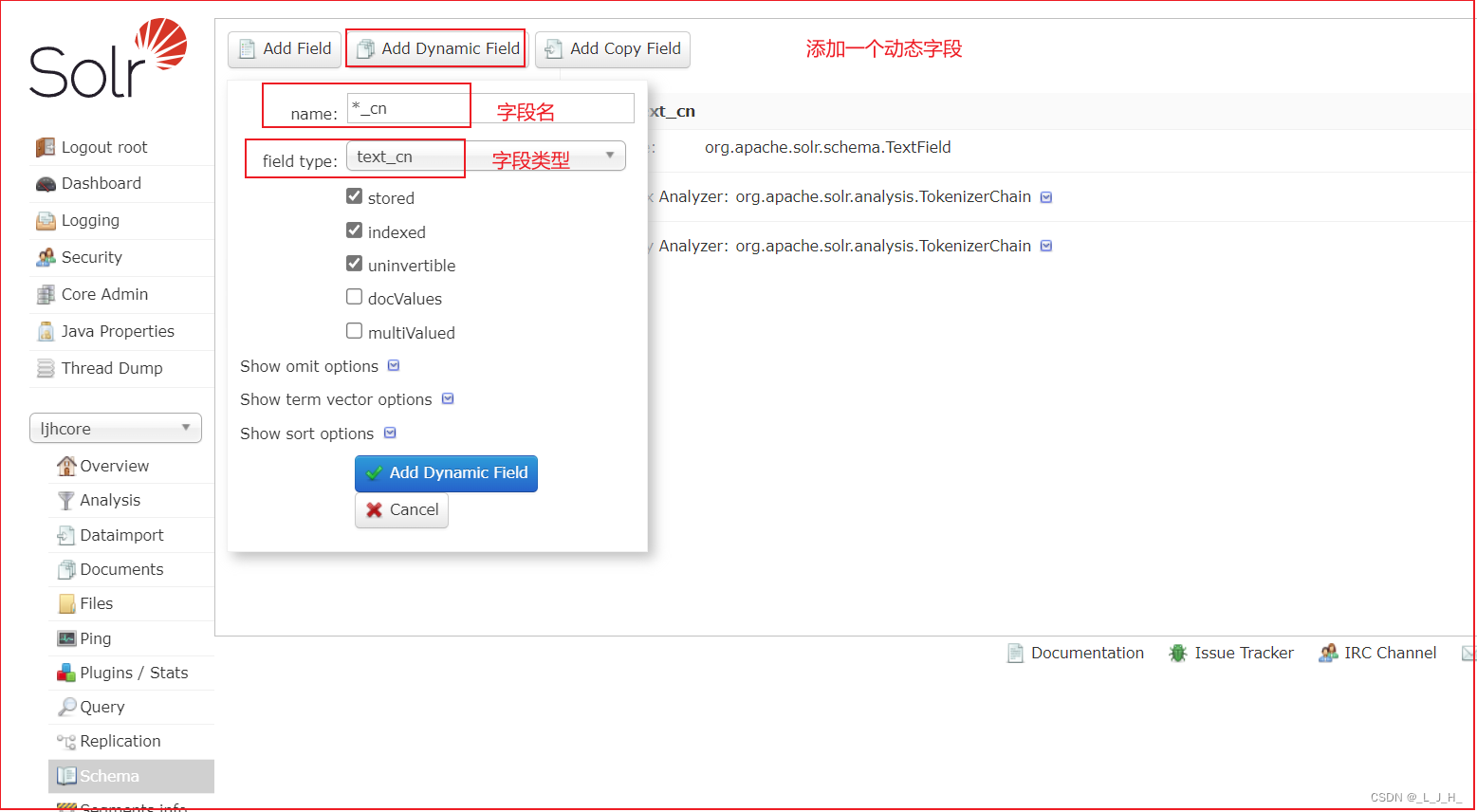
5、添加【*_cn】动态字段,并为该字段设置中文分词器
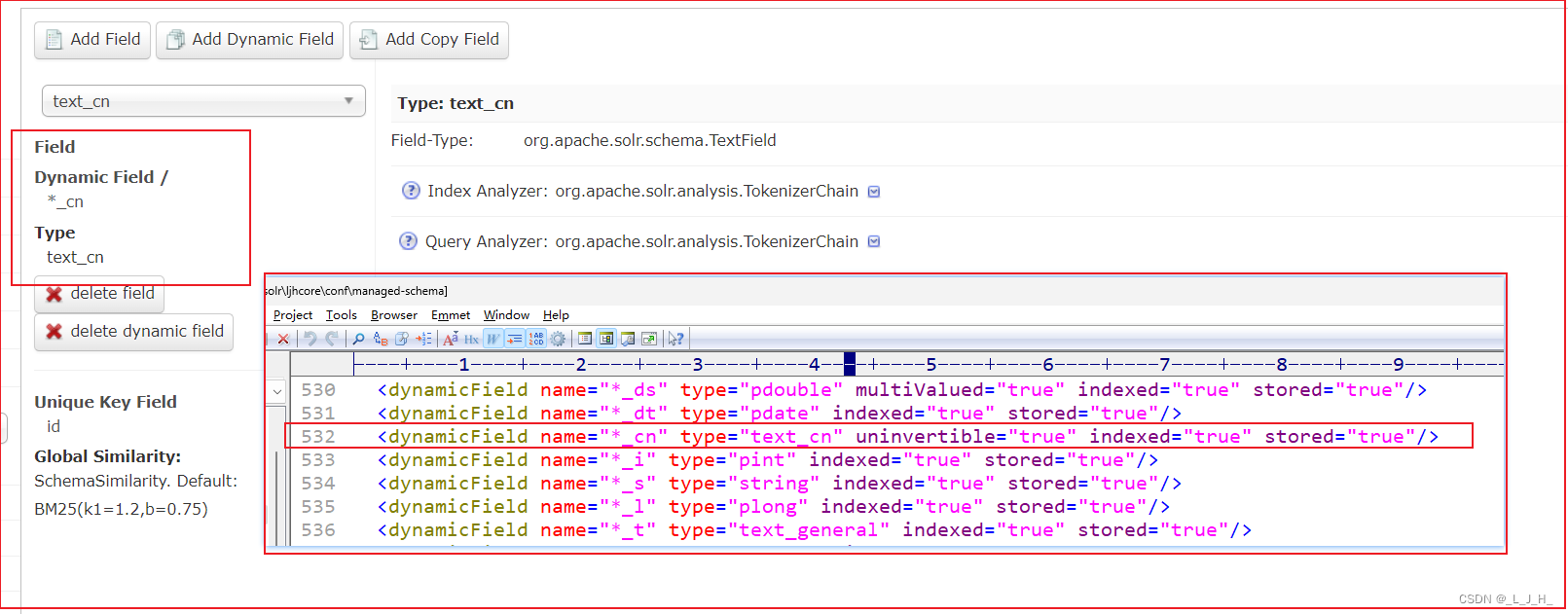
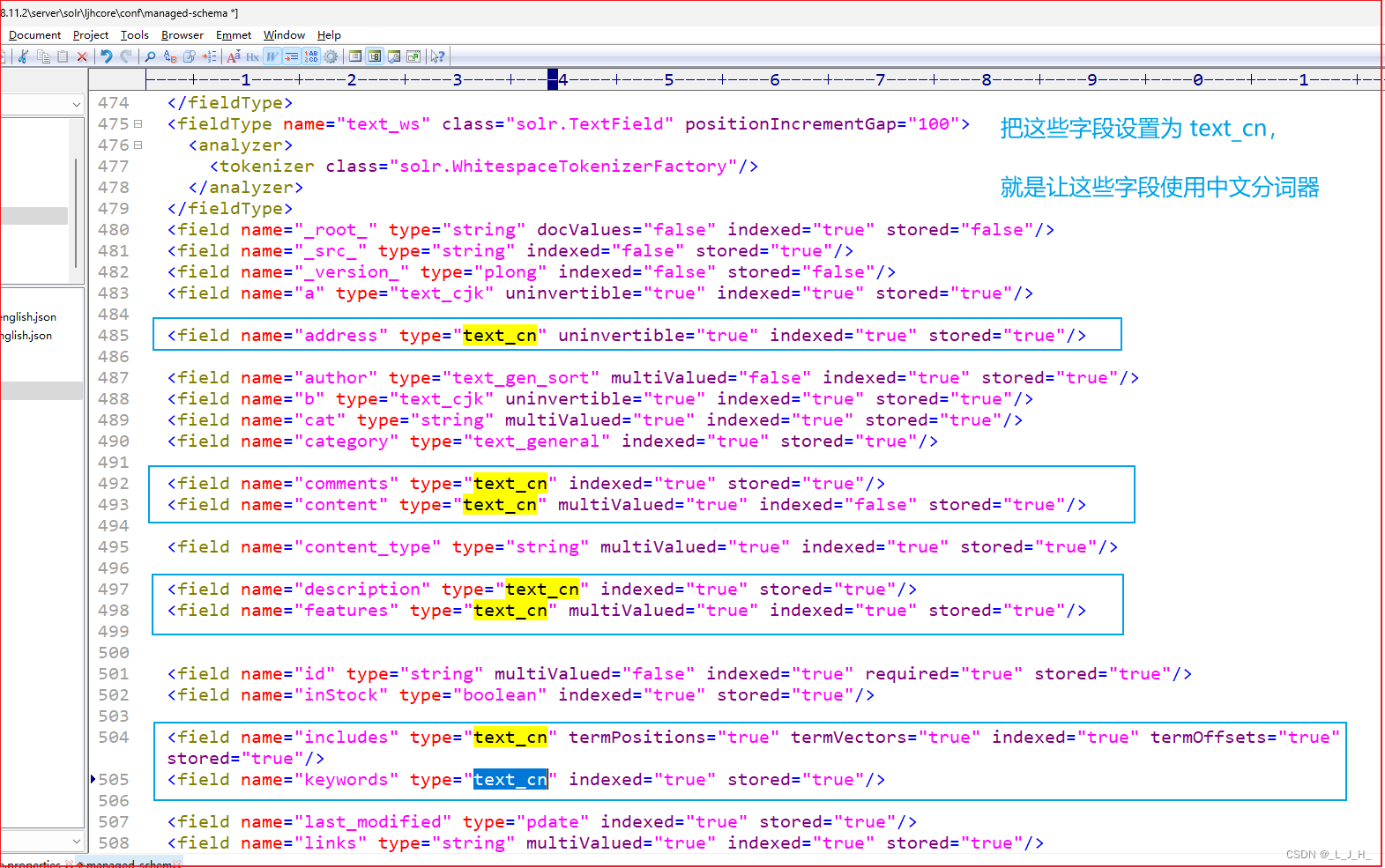

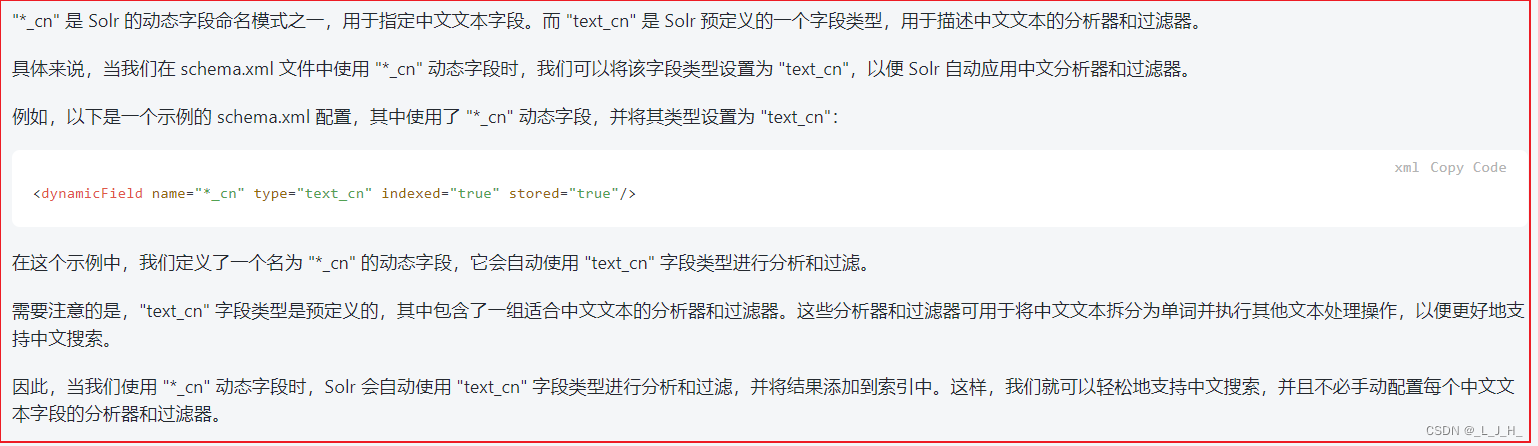
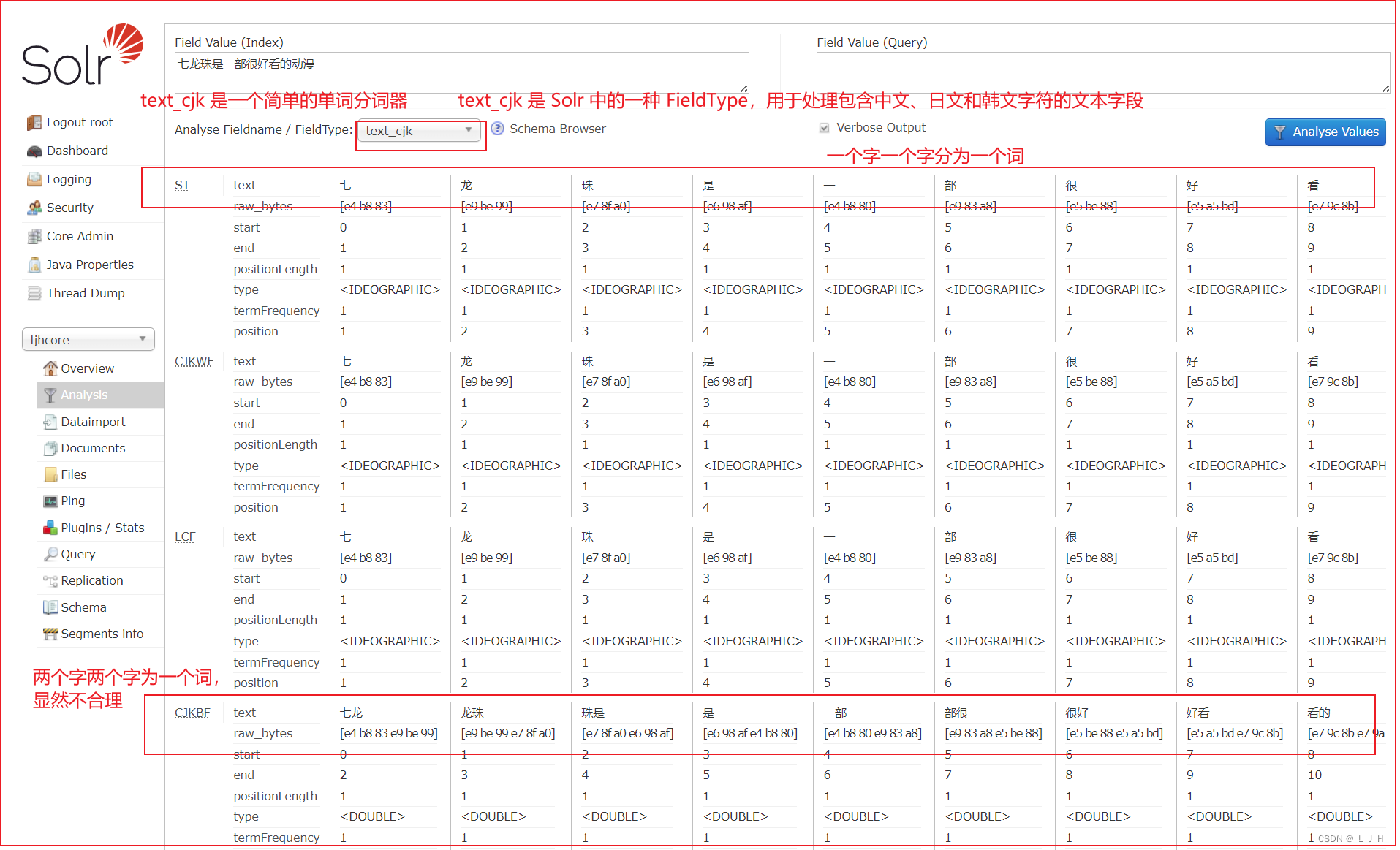
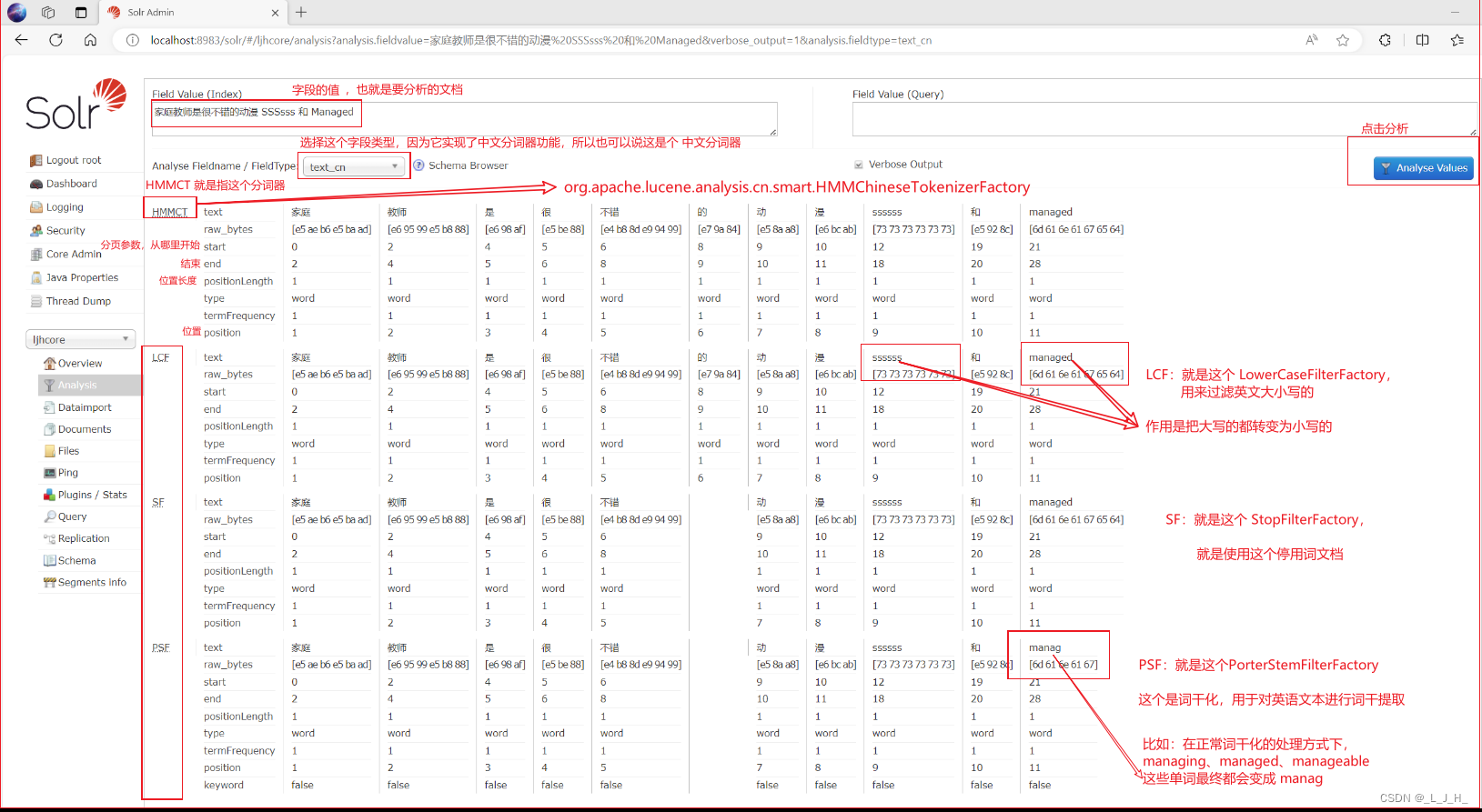
6、演示分词器的区别
演示 text_cjk 这个简单的分词器
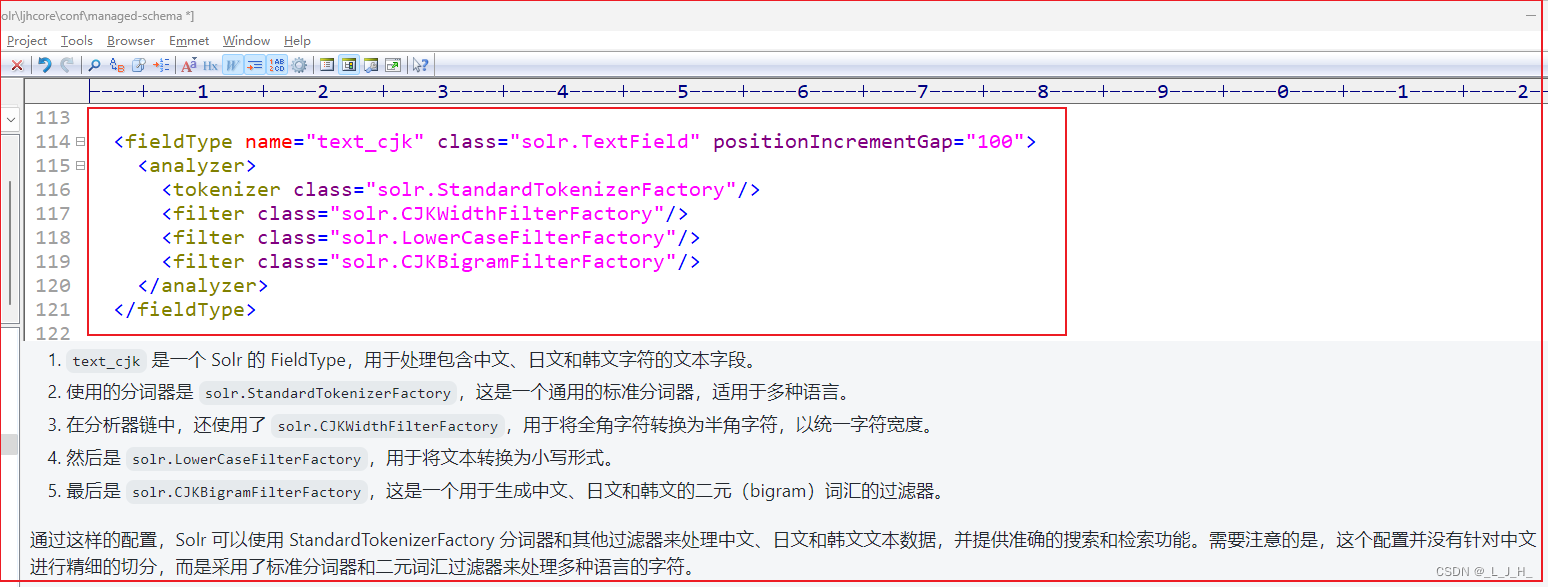
演示 text_cn 这个中文分词器
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。