本文介绍: 在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 – 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (create, read, update 及 delete) 做更进一步的描述。
在我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 – 8.x”,我详细讲述了如何建立 Elasticsearch 的客户端连接。我们也详述了如何对数据的写入及一些基本操作。在今天的文章中,我们针对数据的 CRUD (create, read, update 及 delete) 做更进一步的描述。

创建客户端连接接
我们需要安装 Elasticsearch 的依赖包:
我们使用如下的代码来建立一个客户端连接:
在上面,我们需要使用自己的 Elasticsearch 集群的用户信息及证书代替上面的值。更多信息,请详细参阅文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 – 8.x”。
创建文档

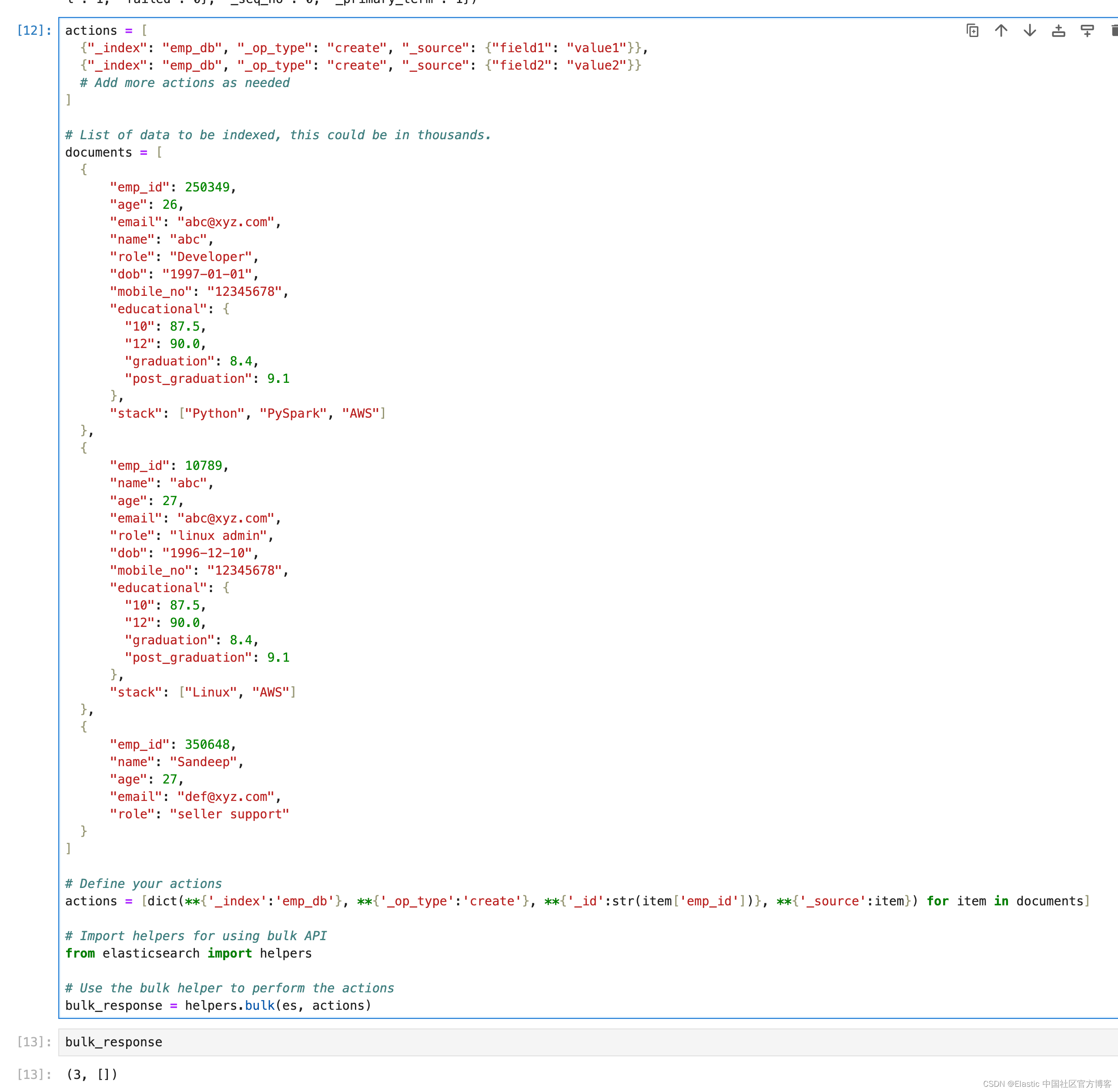
读写操作


更新文档


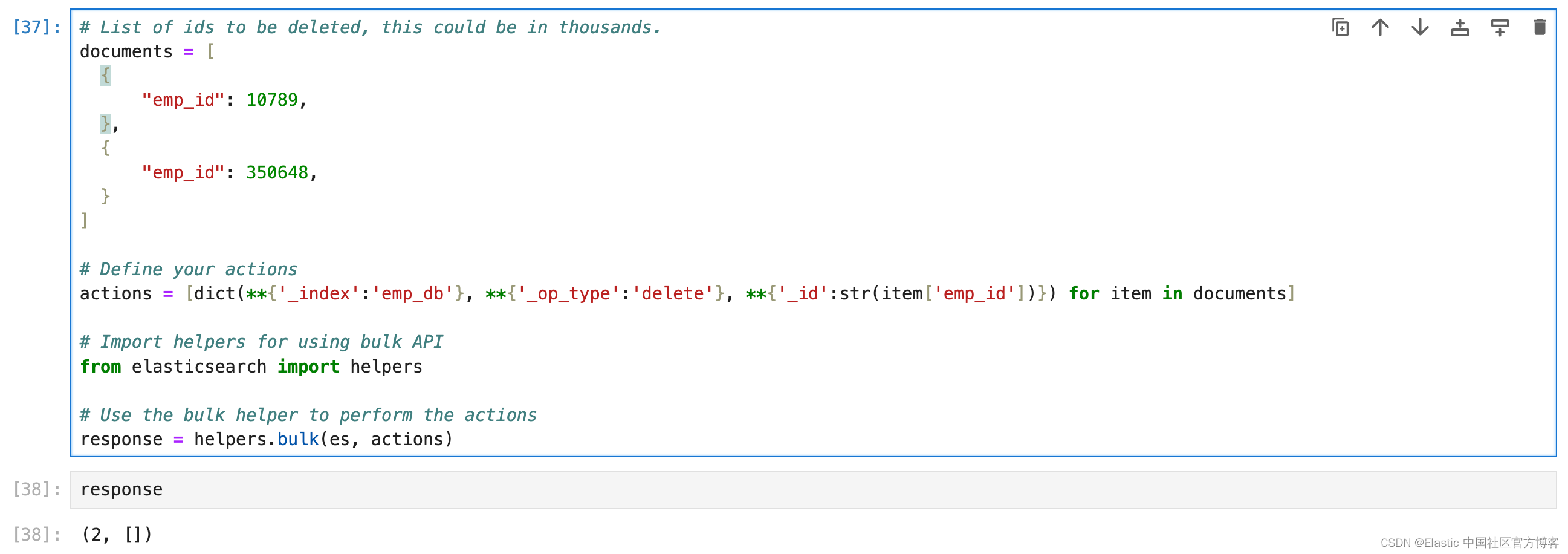
删除文档

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





