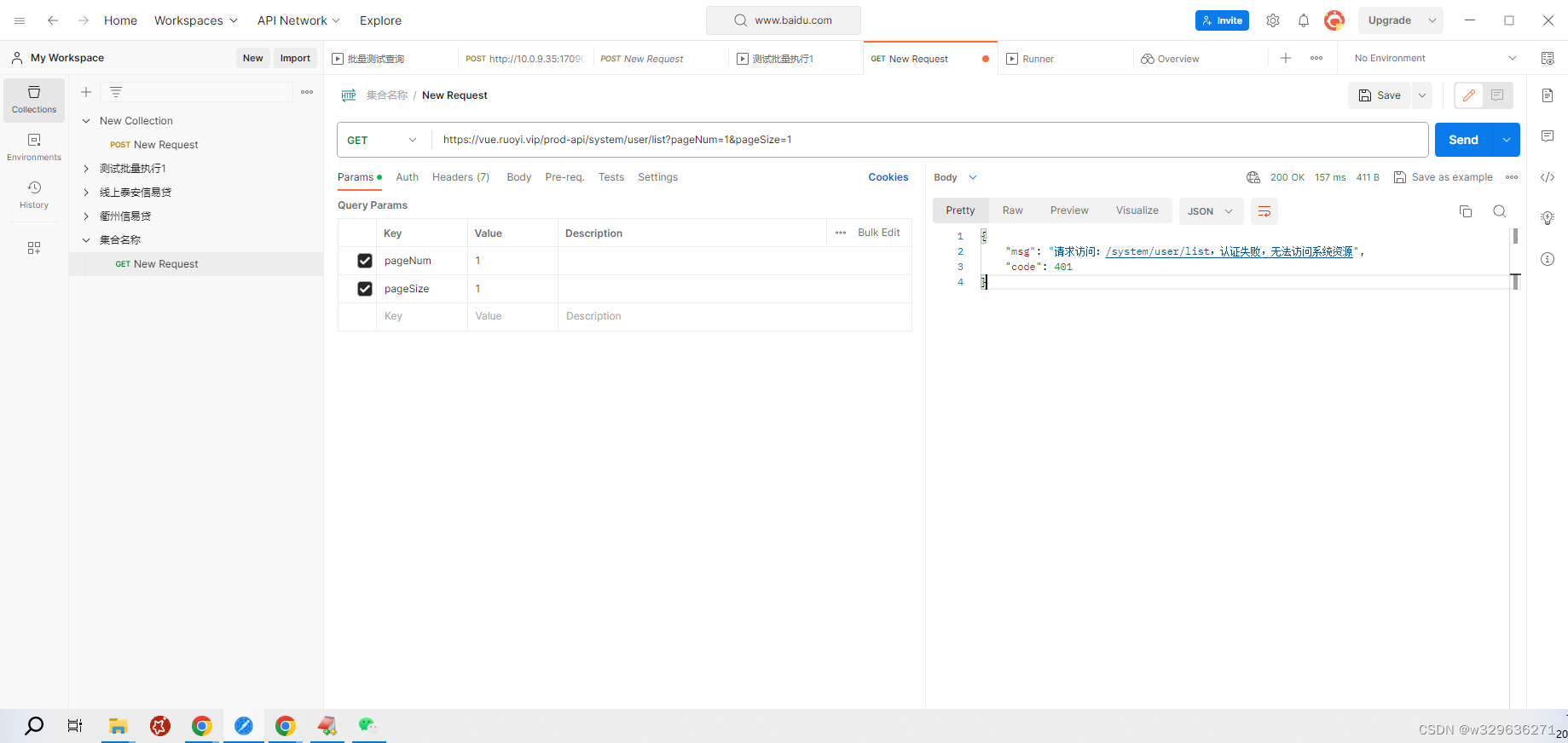
本文介绍: 对于模糊查询的SQL,怎么优先返回等值记录
说明:记录一次SQL改进的方法,希望能对大家有启发。
场景
前端项目有一个输入框,根据输入的银行名称,去模糊查询对应的数据库表,返回结果集,显示到下拉列表中。
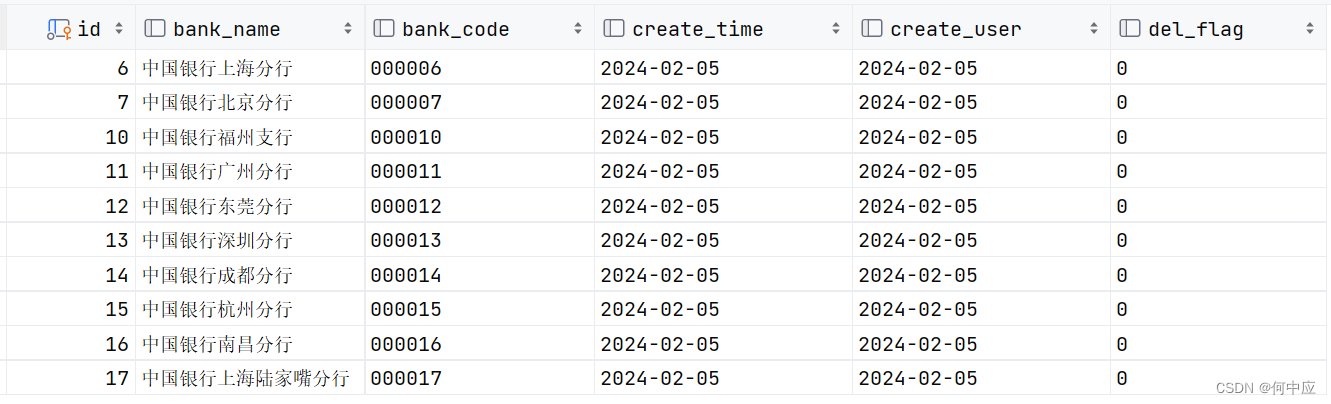
因为银行名称字段包括了分行名,所以结果是模糊查询后可能仍有十几万条记录。考虑到效率和安全,在SQL后面用limit做了个限制,假设只返回了前10条。
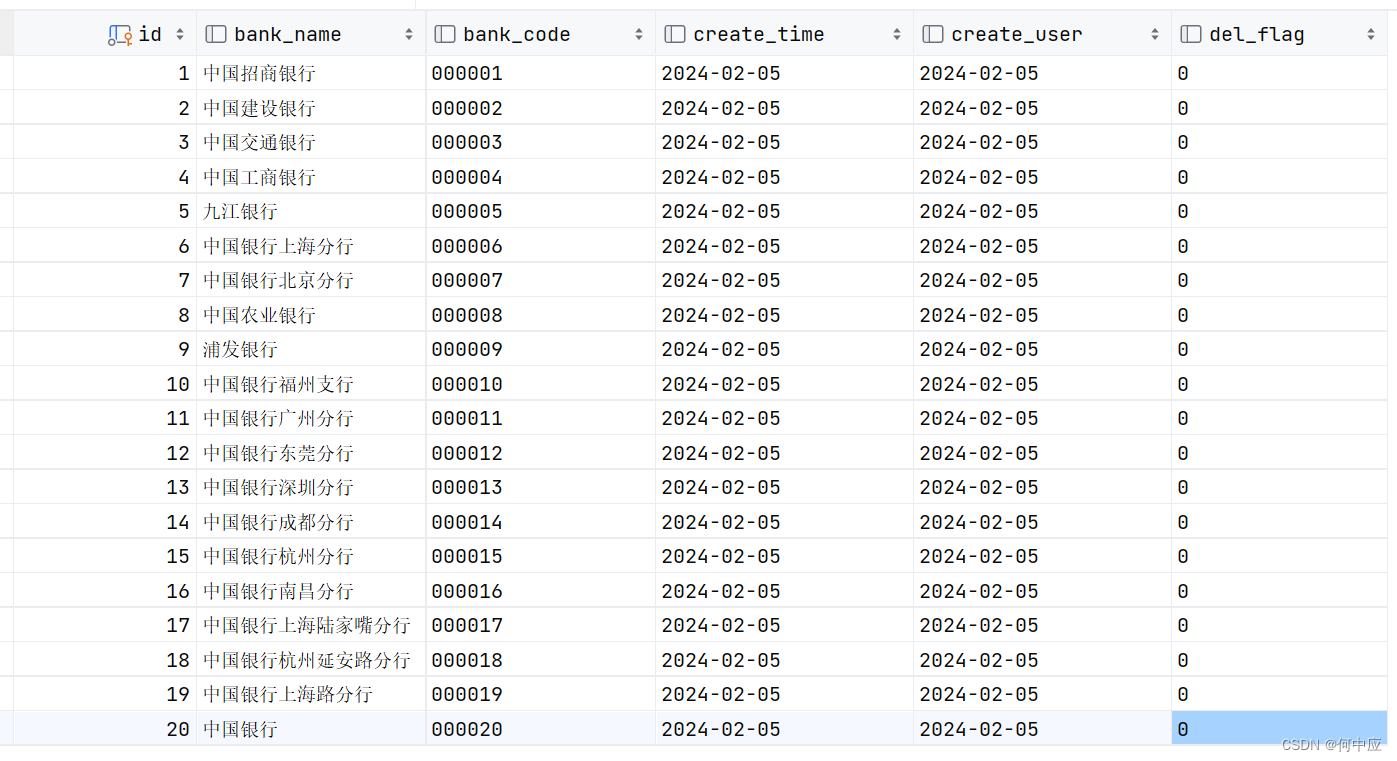
数据库表如下:
但是这会出现一个问题,如下:
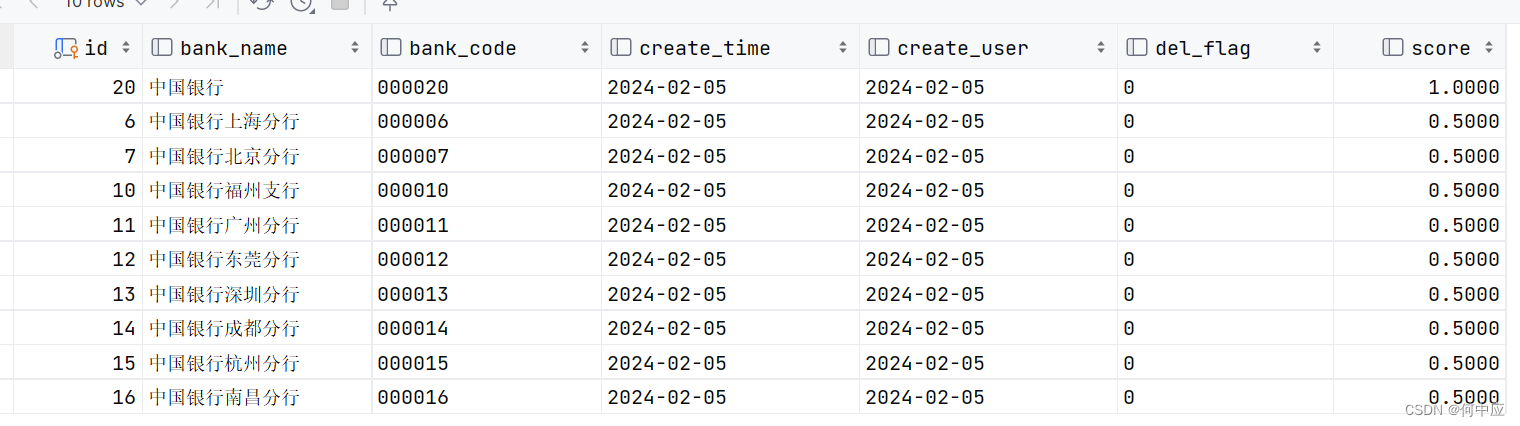
解决
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。