本文介绍: LLMs之Llama2 70B:《Self-Rewarding Language Models自我奖励语言模型》翻译与解读目录《Self-Rewarding Language Models》翻译与解读Abstract5 Conclusion结论6 Limitations限制《Self-Rewarding Language Models》翻译与解读地址文章地址:https://arxiv.org/abs/2401.10020时间2024年1月18日作者Weiz
LLMs之Llama2 70B:《Self-Rewarding Language Models自我奖励语言模型》翻译与解读
目录
《Self-Rewarding Language Models》翻译与解读
《Self-Rewarding Language Models》翻译与解读
Abstract
1 Introduction
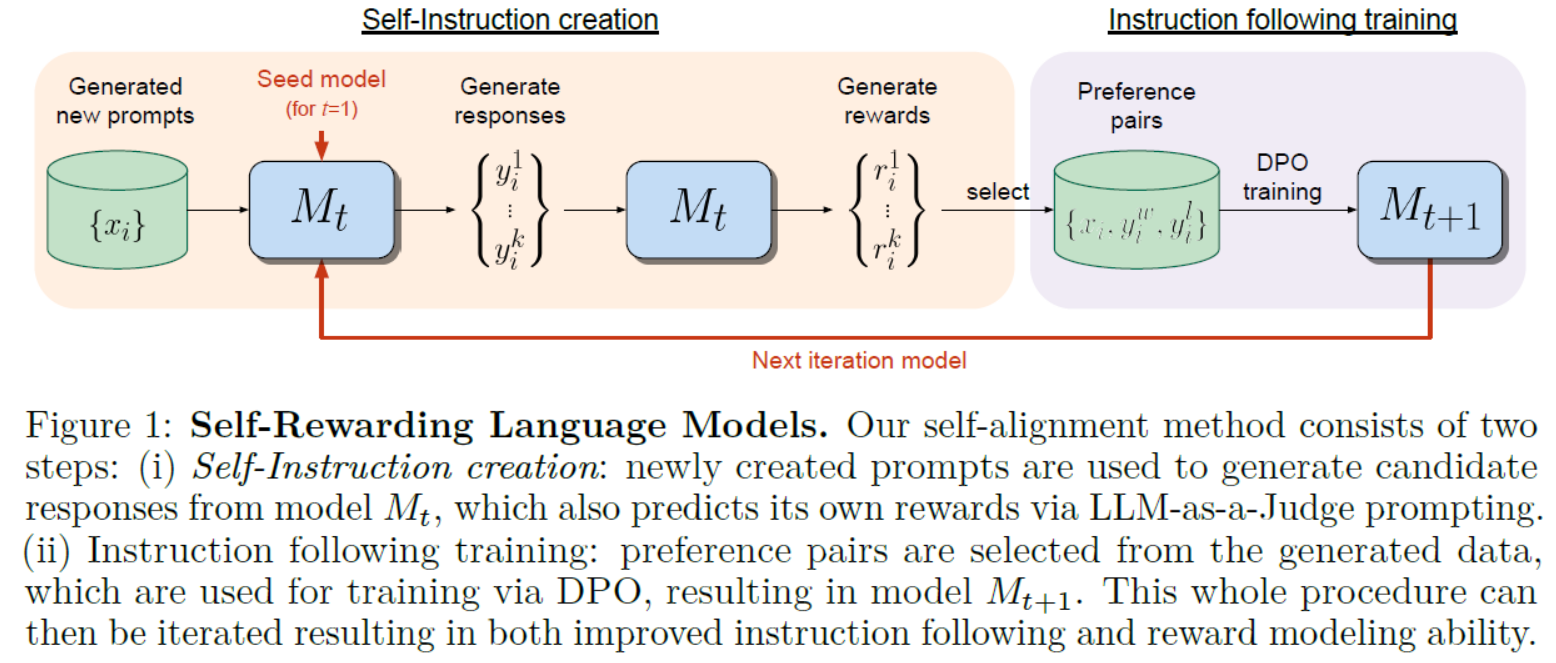
Figure 1: Self-Rewarding Language Models. Our self-alignment method consists of two steps: (i) Self-Instruction creation: newly created prompts are used to generate candidate responses from model Mt, which also predicts its own rewards via LLM-as-a-Judge prompting.(ii) Instruction following training: preference pairs are selected from the generated data, which are used for training via DPO, resulting in model Mt+1. This whole procedure can then be iterated resulting in both improved instruction following and reward modeling ability.图1:自我奖励语言模型。我们的自对齐方法包括两个步骤:(i)自我指令创建:使用新创建的提示从模型Mt中生成候选响应,并通过LLM-as-a-Judge提示预测其自身的奖励。(ii)训练后的指令:从生成的数据中选择偏好对,通过DPO进行训练,得到模型Mt+1。然后,整个过程可以迭代,从而提高指令遵循和奖励建模能力。
5 Conclusion结论
6 Limitations限制
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。