论文名称:Cloud Workload Turning Points Prediction via Cloud Feature-Enhanced Deep Learning
摘要
云工作负载转折点要么是代表工作负载压力的局部峰值点,要么是代表资源浪费的局部谷值点。预测这些关键点对于向系统管理者发出警告、采取预防措施以实现高资源利用率、服务质量(QoS)和投资收益至关重要。现有研究主要只关注于工作负载未来点值的预测,而没有考虑基于趋势的转折点预测。此外,在预测过程中最关键的挑战之一是,传统的趋势预测方法在金融和工业领域等方面虽然取得了成功,但它们表示云特征的能力较弱,这意味着它们无法描述高度变化的云工作负载时间序列。本文提出了一种基于云特征增强的深度学习的新型云工作负载转折点预测方法。首先,我们建立了一个考虑云工作负载特征的云服务器工作负载转折点预测模型。然后,设计了一个云特征增强的深度学习模型用于工作负载转折点预测。在最著名的谷歌集群上的实验展示了我们的模型与最先进模型相比的有效性。据我们所知,本文是第一篇通过云特征增强的深度学习对云工作负载时间序列的基于转折点的趋势预测进行系统研究的文章。
索引术语——云计算,转折点预测,深度学习,云特征增强,时间序列分析
1 引言
过去十年,云计算的商业使用需求激增,其高可扩展性、灵活性和成本效益特性能够满足新兴的大规模计算需求。云计算现在正日益成为不可或缺的计算基础设施[1],[2],[3],这得益于其高可扩展性、动态资源共享、细粒度资源调度等优点。云工作负载是一个重要的时间序列,由云数据中心执行期间的时间戳、事件类型和机器工作负载的事件记录组成,对于分析云工作负载的波动非常重要。准确预测云工作负载趋势是实现细粒度高资源利用率、服务质量和云数据中心经济利润的关键步骤。
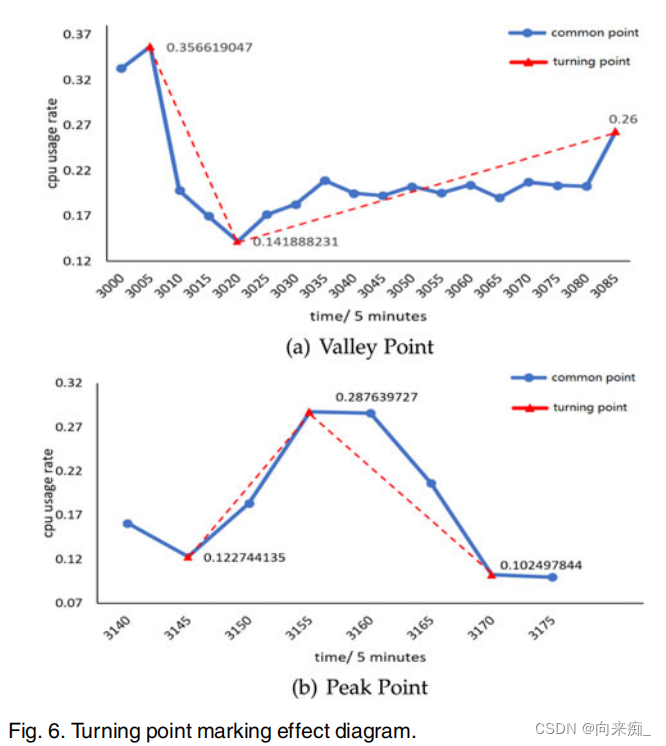
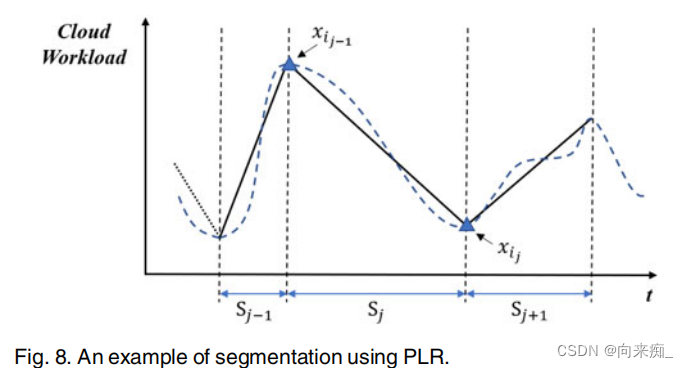
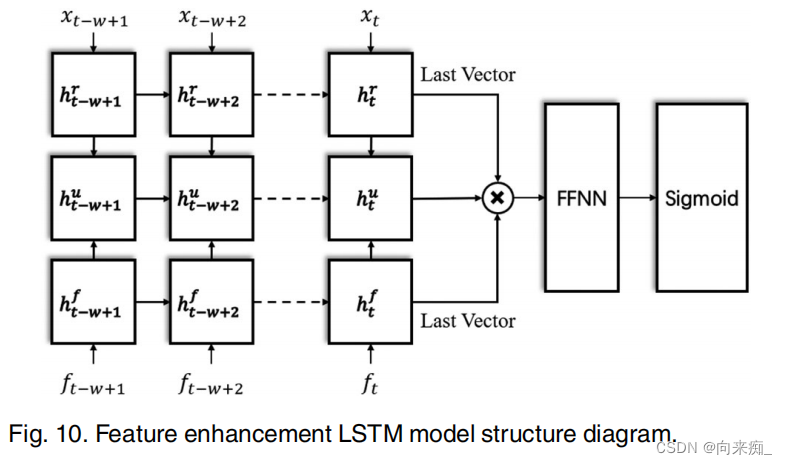
趋势预测任务可以分为三类:i) 预测下一个点相对于当前点是上升还是下降[4];ii) 预测下一个趋势段的斜率和持续时间[5];iii) 预测下一个点是否为转折点[6]。然而,随着云工作负载规模的增加,准确预测云工作负载趋势仍然是一个巨大的挑战,因为云数据中心的工作负载呈现出越来越高的变异性和波动性[7],[8],[9]。以谷歌集群追踪数据为例,这是最著名的云工作负载追踪之一,图1展示了工作负载的波动(谷歌云服务集群中服务器编号为207776314的CPU工作负载)。从图1中我们可以看到,工作负载序列随时间持续波动,包括一些代表工作负载压力的局部峰值点或通常代表资源浪费的局部谷值点。这些点被称为云工作负载转折点。然而,现有的云工作负载预测方法更多地关注于未来工作负载点值的预测方法,这些方法生成预测工作负载的单个点的预期值。对于以未来工作负载点值为中心的预测,尽管可以预测未来的工作负载值,但很难推断出动态变化趋势,即是否存在代表工作负载压力的局部峰值或代表资源浪费的局部谷值,因为我们只知道每个点的值,但无法判断最关键的特征是峰值点还是谷值点。即,现有的点值研究更多地关注于特定值,而不是它是谷值点还是峰值点。此外,传统的以工作负载点值为中心的预测基于回归理论、启发式方法或传统神经网络,这需要明显的模式或清晰的工作负载趋势才能进行准确预测。最近,为了处理高度非线性的工作负载,一些深度学习模型已经引起了人们对工作负载预测[10],[11]的日益浓厚的兴趣。