starrocks官网介绍了starrocks 负载均衡 的实现方式,其中可以 通过代码均衡负载、 通过 JDBC Connector 均衡负载, 通过 ProxySQL 均衡负载 等三种方式实现负载均衡。
本文通过nginx的方式实现flink消费sr数据时的负载均衡。并解决flink在运行sr任务中遇到的问题。
一. 通过nginx实现starrocks负载均衡与故障转移
1. 架构逻辑与nginx配置
大致逻辑:
flink请求Nginx负载均衡服务器,根据规则(hash、轮询)将请求转发到选定的FE_Server 进程。其中
- 9031用于通过jdbc方式与Starrocks进行交互,其中可以在flink任务运行前、后,在jobmanager中执行pre-sql、post-sql。
- 8031用于通过Starrocks的streamload方式来写入数据到Starrocks。
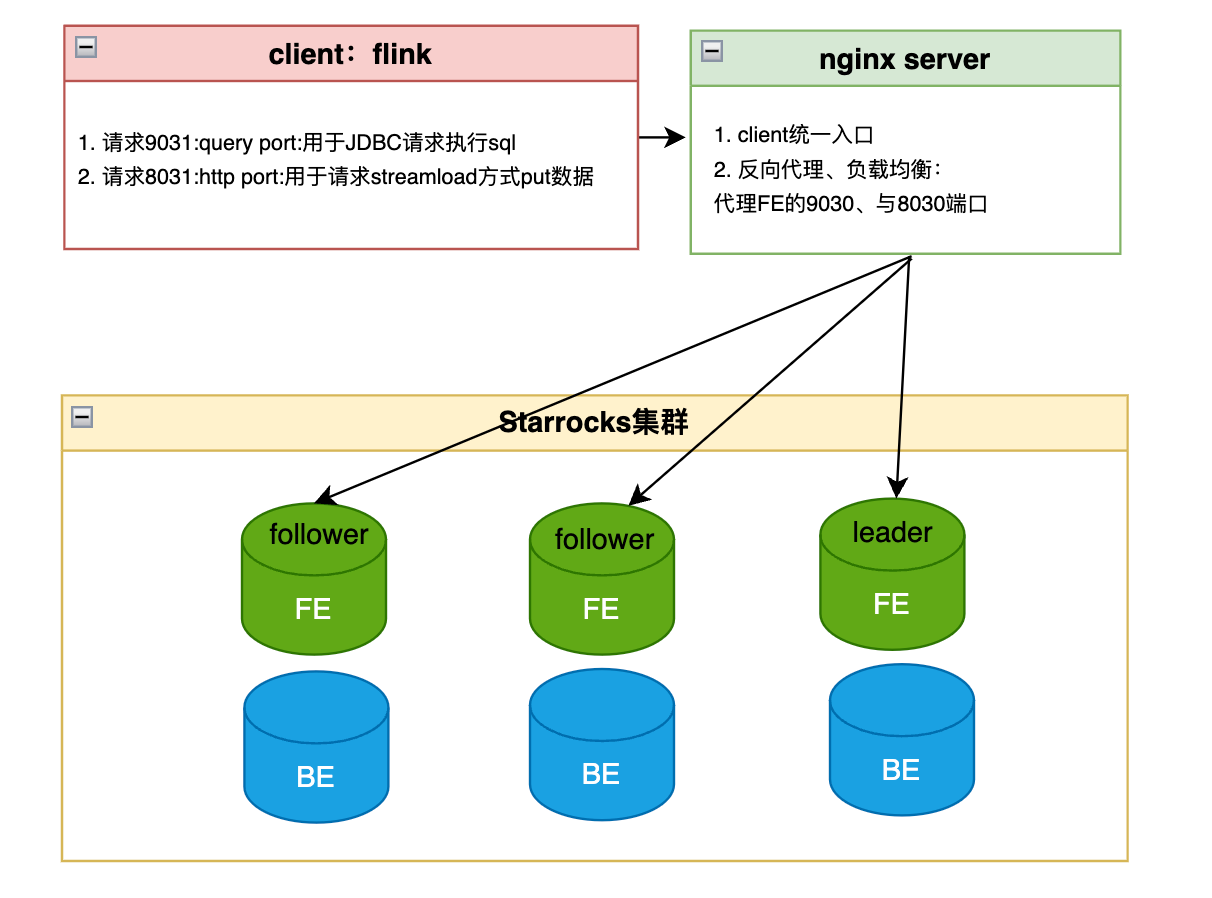
nginx的定位
Nginx作为反向代理,upstream绑定多个FE节点,既可以实现负载均衡,又能实现故障自动切换。
故障转移
- 当请求到某个server失败时(由
proxy_next_upstream判断),nginx会请求下个upstream server。- 当转发请求
max_fails次还未成功,则判断为此机器dead,nginx就不再转发请求到此节点,直到fail_timeout后,nginx将此节点加回运行节点列表。
负载均衡
因为Starrocks中fe只有follower和leader,且follower和leader谁接收请求效果都一致,所以这里设置为轮询规则(默认规则),均匀地(
weight决定)转发请求到各个FE节点。
#user nobody;
worker_processes 4;
events {
worker_connections 1024;
}
# 用于负载均衡flink中对Starrocks的jdbc请求
stream{
upstream starrocks-tcp1{
# hash $remote_add consistent;
server hostname1:9030 weight=1 max_fails=3 fail_timeout=60s; #Leader
server hostname2:9030 weight=1 max_fails=3 fail_timeout=60s; #Follower
server hostname3:9030 weight=1 max_fails=3 fail_timeout=60s; #Follower
}
server
{
#proxy 代理的nginx监听端口,可自行修改
listen 9031;
proxy_pass starrocks-tcp1;
proxy_timeout 60s;
proxy_connect_timeout 30s;
}
}
# 用于负载均衡flink中通过Starrocks的streamload方式put数据到sr的请求
http {
include mime.types;
include /usr/local/nginx/conf.d/*.conf;
client_max_body_size 10240m;
default_type application/octet-stream;
sendfile on;
# 用于管理HTTP长连接生命周期的参数。它定义了一个TCP连接在完成最后一次数据传输后,
# 仍然保持打开状态等待新的请求的最大时间。
keepalive_timeout 600;
upstream starrocks-tcp2
{
#ip_hash;
# 当连续转发请求3次还未成功,则判断为此机器dead,并等待60后重试此机器。
server hostname1:8030 weight=1 max_fails=3 fail_timeout=60s; #Leader
server hostname2:8030 weight=1 max_fails=3 fail_timeout=60s; #Follower
server hostname3:8030 weight=1 max_fails=3 fail_timeout=60s; #Follower
}
server
{
# proxy 代理的nginx监听端口
# 通过监听8031端口下所有请求,将请求转发到sr的8030端口。
listen 8031;
location / {
proxy_pass http://starrocks-tcp2;
# 添加请求头
proxy_set_header expect "100-continue";
# 故障转移策略:当出现如下返回时,nginx将会尝试与下一台机器进行链接。
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
}
2. nginx相关知识:stream模块和http模块
Nginx的stream模块和http模块是用来处理不同类型的流量的。
2.1. stream模块
stream模块被设计来处理TCP和UDP流量。这是非HTTP的普通TCP或UDP流量,可以应用于任何依赖于TCP或UDP的服务,比如邮件服务器、数据库连接甚至自定义的网络协议。
这里通过stream模块实现了Starrocks jdbc协议下的反向代理,如下。flink通过9031端口访问Starrocks时,先经过nginx,然后转发到upstream下某一个server中。
stream{
upstream starrocks-tcp1{
# hash $remote_add consistent;
server hostname1:9030 weight=1 max_fails=3 fail_timeout=60s; #Leader
server hostname2:9030 weight=1 max_fails=3 fail_timeout=60s; #Follower
server hostname3:9030 weight=1 max_fails=3 fail_timeout=60s; #Follower
}
server
{
#proxy 代理的nginx监听端口,可自行修改
listen 9031;
proxy_pass starrocks-tcp1;
proxy_timeout 60s;
proxy_connect_timeout 30s;
}
}
2.2. http模块
http模块主要处理HTTP流量。它为HTTP和HTTPS请求提供了反向代理、负载均衡、缓存等功能。此外,它还可以处理基于HTTP的其他协议,如WebSocket。
flink通过8031端口访问Starrocks时,同样经过nginx,nginx转发请求到的upstream中某台server,最终通过streamload方式将数据写到Starrocks。
# 用于负载均衡flink中通过Starrocks的streamload方式put数据到sr的请求
http {
include mime.types;
include /usr/local/nginx/conf.d/*.conf;
client_max_body_size 10240m;
default_type application/octet-stream;
sendfile on;
# 用于管理HTTP长连接生命周期的参数。它定义了一个TCP连接在完成最后一次数据传输后,
# 仍然保持打开状态等待新的请求的最大时间。
keepalive_timeout 600;
upstream starrocks-tcp2
{
#ip_hash;
# 当连续转发请求3次还未成功,则判断为此机器dead,并等待60后重试此机器。
server hostname1:8030 weight=1 max_fails=3 fail_timeout=60s; #Leader
server hostname2:8030 weight=1 max_fails=3 fail_timeout=60s; #Follower
server hostname3:8030 weight=1 max_fails=3 fail_timeout=60s; #Follower
}
server
{
# proxy 代理的nginx监听端口
# 通过监听8031端口下所有请求,将请求转发到sr的8030端口。
listen 8031;
location / {
proxy_pass http://starrocks-tcp2;
# 添加请求头
proxy_set_header expect "100-continue";
# 故障转移策略:当出现如下返回时,nginx将会尝试与下一台机器进行链接。
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
}
总的来说,stream模块适用于处理TCP或UDP流量,而http模块则用来处理HTTP及HTTPS流量。
二. 使用flink 消费SR实战
简述: 通过flink sql 实现source SR->sink SR的任务。
说明:flink版本1.16.1,数据量为3300万左右,并发为1,任务时长为1小时5分钟。
以下是在使用flink运行SR任务遇到的问题与解决方式
1. Expect: 100-continue 问题
1.1. Expect: 100-continue的逻辑
http clients发送带有Expect: 100-continueheader的post(put)请求时,是在告诉server端我准备要发送大负载的数据了。
server端接收到此请求时,可以做如下response:
- 拒绝:通过返回401/405并逐步关闭连接来拒绝请求。
- 接受:通过发送100 Continue,之后客户端将发送有效载荷。
- 要求客户端以未更改的方式重新发送原始请求(包括原始头部和有效载荷),通过回复一个
417 Expectation Failed。
curl在即将发送大型有效载荷时,它会自动发送
Expect: 100-continue头部。curl 命令添加Expect: 100-continueheader请求时,等待server的response。server评估Content-Lengthheader值,然后决定是否终止请求或接受。
在等待(默认)一秒钟获取response后,curl将数据发送到POST请求的主体中。
参考:
About the HTTP Expect: 100-continue header
the Expect header is all about
1.2. 问题分析与解决
当通过flink通过streamload(http client)方式put数据到SR之前,添加了100-continue
String loadUrl =
host
+ "/api/"
+ bufferEntity.getDatabase()
+ "/"
+ bufferEntity.getTable()
+ "/_stream_load";
try (CloseableHttpClient httpclient = httpClientBuilder.build()) {
HttpPut httpPut = new HttpPut(loadUrl);
...
httpPut.setHeader("Expect", "100-continue");
...
try (CloseableHttpResponse resp = httpclient.execute(httpPut)) {
HttpEntity respEntity = getHttpEntity(resp);
if (respEntity == null) return null;
return (Map<String, Object>) JSON.parse(EntityUtils.toString(respEntity));
}
}
但实际运行过程当中出现:
2024-01-22 18:04:01,875 INFO com.dtstack.chunjun.connector.starrocks.streamload.StarRocksStreamLoadVisitor
- [dealStreamLoadResult] get loadResult msg = There is no 100-continue header
2024-01-22 18:04:01,875 INFO
com.dtstack.chunjun.connector.starrocks.streamload.StarRocksStreamLoadVisitor
- [dealStreamLoadResult] get loadResult status = FAILED
简化日志:{"status":"FAILED","msg":"There is no 100-continue header"}
也就说nginx转发请求时丢掉了Expect: 100-continue 的header,至于为什么丢失,这里暂不分析。
那既然这样我们在http模块中添加Expect: 100-continue header。如下。添加之后数据写入问题解决。
server
{
# proxy 代理的nginx监听端口
# 通过监听8031端口下所有请求,将请求转发到sr的8030端口。
listen 8031;
location / {
proxy_pass http://starrocks-tcp2;
# 添加请求头
proxy_set_header expect "100-continue";
# 故障转移策略:当出现如下返回时,nginx将会尝试与下一台机器进行链接。
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
2.no live upstreams while connecting to upstream
问题描述:当任务运行到40多分钟时,出现如下报错
2024/01/24 14:53:14 [error] 6581#0: *3093 no live upstreams while connecting to upstream, client: xxx,
server: , request: "PUT /api/radar_test/test_qnmanager_data/_stream_load HTTP/1.1", upstream:
"http://starrocks-tcp2/api/radar_test/test_qnmanager_data/_stream_load", host: "nginx-node:8031"
2024/01/24 14:53:16 [error] 6581#0: *3095 no live upstreams while connecting to upstream, client: xxx,
server: , request: "PUT /api/radar_test/test_qnmanager_data/_stream_load HTTP/1.1", upstream:
"http://starrocks-tcp2/api/radar_test/test_qnmanager_data/_stream_load", host: "nginx-node:8031"
导致任务失败。日志大概的意思是:使用的是 HTTP/1.1 在nginx接收客户端的请求后,转发到SR集群,出现no live upstreams while connecting to upstream 的错误,也就是说SR集群中的FE不能提供服务,或者nginx不能提供可用的FE服务器。
no live upstreams while connecting to upstream错误解释:当链接upstreams没有在线的upstreams。upstreams指的是被代理的服务端,upstream块中server节点们。
排查:
查看SR fe节点状态,如下fe节点正常。
mysql -hHost1 -P9031 -uroot -p1111 radar_test
SHOW PROC '/frontends';
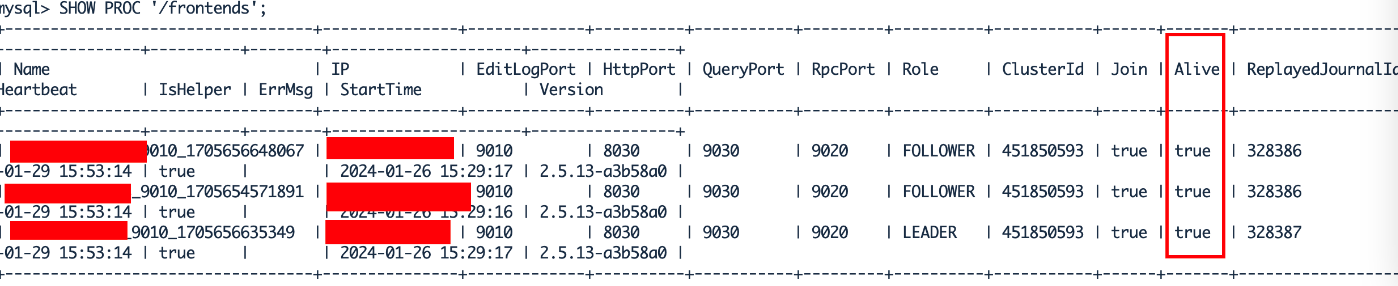
此时基本可以确定是nginx不能发送向SR的FEs发送请求,导致flink任务失败。
通过前面的分析,目前可能的情况有:
- 上游服务器连接超时: Nginx 在尝试连接上游服务器时,如果超过了设定的连接超时时间,可能会将该服务器标记为不可用。确保连接超时时间配置合理,不要设置得过短。
- 上游服务器端口问题: 确保 Nginx 配置中指定的上游服务器端口是正确的,而且上游服务器正在监听该端口。
- DNS 解析问题: 如果上游服务器使用域名而不是 IP 地址配置,可能存在 DNS 解析问题。确保 DNS 配置正确,可以通过手动进行 DNS 查询来检查。
分别分析:
- nginx监听端口的问题,如下端口没有问题:
- dns也没有问题
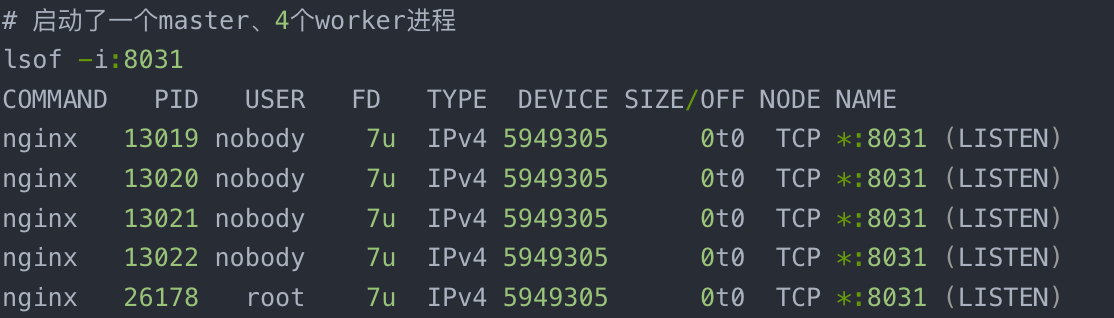

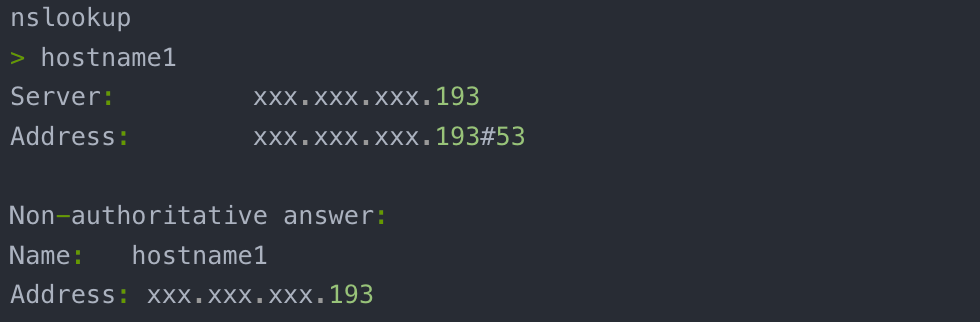
- 上游服务器连接超时
先看之前nginx的配置:
http {
...
# 用于管理HTTP长连接生命周期的参数。它定义了一个TCP连接在完成最后一次数据传输后,
# 仍然保持打开状态等待新的请求的最大时间。
# keepalive_timeout 60;
keepalive_timeout 600;
upstream starrocks-tcp2
{
#ip_hash;
# 当连续转发请求1次还未成功,则判断为此机器dead,并等待600后重试此机器。
server hostname1:8030 weight=1 max_fails=1 fail_timeout=600s; #Leader
server hostname2:8030 weight=1 max_fails=1 fail_timeout=600s; #Follower
server hostname3:8030 weight=1 max_fails=1 fail_timeout=600s; #Follower
}
server
{
listen 8031;
location / {
proxy_pass http://starrocks-tcp2;
proxy_set_header expect "100-continue";
# 故障转移策略:当出现如下返回时,nginx将会尝试与下一台机器进行链接。
# proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
}
}
}
问题分析:
flink写3000万数据到SR是频繁触发请求的场景,很容易导致请求失败,这里关于故障转移的配置为:
max_fails=1、fail_timeout=600s,意思是只要请求失败,就将server判定为dead,并且10分钟之后才重试,那这里就有可能出现:三台节点某次处理请求都失败,导致长达10分钟upstream不可用,即报错:no live upstreams while connecting to upstream。
改进配置:max_fails=3 fail_timeout=60s,降低server故障转移的频率与缩短故障时间,降低因为请求导致的高故障率。
其次改进TCP连接超时时间keepalive_timeout 60;,避免过长的时间导致TCP空闲连接浪费资源。
再有丰富nginx捕获异常的能力:proxy_next_upstream error timeout http_500 http_502 http_503 http_504;。
3.recv() failed (104: Connection reset by peer) while reading response header from upstream(ing)
recv() failed (104: Connection reset by peer) 表示nginx接收客户端的数据时连接被对端(peer)重置。
参考:
Connection reset by peer 错误定位
4.transmit chunk rpc failed
2024-01-24 18:13:31,621 WARN org.apache.flink.runtime.taskmanager.Task - Source: source[1] -> Sink: sink[2] (1/1)#0 (a4cbae5aa8bbd03aaf344721b498f489_cbc357ccb763df2852fee8c4fc7d55f2_0_0) switched from RUNNING to FAILED with failure cause: com.dtstack.chunjun.throwable.ChunJunRuntimeException: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: transmit chunk rpc failed:10304bfb-ba98-11ee-ab87-1070fda9b63f
at com.dtstack.chunjun.connector.jdbc.source.JdbcInputFormat.nextRecordInternal(JdbcInputFormat.java:227)
at com.dtstack.chunjun.source.format.BaseRichInputFormat.nextRecord(BaseRichInputFormat.java:199)
at com.dtstack.chunjun.source.format.BaseRichInputFormat.nextRecord(BaseRichInputFormat.java:67)
at com.dtstack.chunjun.source.DtInputFormatSourceFunction.run(DtInputFormatSourceFunction.java:125)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:333)
Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: transmit chunk rpc failed:10304bfb-ba98-11ee-ab87-1070fda9b63f
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
at com.mysql.jdbc.Util.getInstance(Util.java:408)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:944)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3933)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3869)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:864)
at com.mysql.jdbc.MysqlIO.nextRow(MysqlIO.java:1992)
at com.mysql.jdbc.RowDataDynamic.nextRecord(RowDataDynamic.java:366)
at com.mysql.jdbc.RowDataDynamic.next(RowDataDynamic.java:346)
at com.mysql.jdbc.ResultSetImpl.next(ResultSetImpl.java:6303)
at com.dtstack.chunjun.connector.jdbc.source.JdbcInputFormat.nextRecordInternal(JdbcInputFormat.java:224)
... 6 more
flink任务为source:SR -> sink: SR ,其中通过jdbc的方式拉取SR数据,在任务执行50分钟时出现此错误:传输rpc数据块时失败。有可能是jdbc链接设置的问题,也有可能是SR传输数据时的问题。这里通过设置SR参数:brpc_socket_max_unwritten_bytes=8589934592,增大传输数据的大小,解决问题。
原文地址:https://blog.csdn.net/hiliang521/article/details/136030331
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_67055.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!