本文介绍: 由于最近频繁在java、python、go三种开发语言中不断切换,有时候针对基础的数据结构和日常操作搞混了,因此本文进行相关梳理。文中涉及的相关数据结构和日常操作并不复杂,权当增强记忆和理解。
由于最近频繁在java、python、go三种开发语言中不断切换,有时候针对基础的数据结构和日常操作搞混了,因此本文进行相关梳理。文中涉及的相关数据结构和日常操作并不复杂,权当增强记忆和理解。
1. Java
Java 自带了各种 Map 类。这些 Map 类可归为三种类型:
其中HashMap是最常用的,其他类型的Map根据使用,本文重点介绍HashMap
1.1 基础操作
1.1.1 数据结构和定义方式
1.1.2 增加
1.1.3 修改
1.1.4 查询
1.1.5 删除
1.1.6 获取总长度
1.1.7 按key排序
HashMap本身本身无序,如果需要排序,可以单独整理出key作为列表,然后形成排序,通过有序的key获取对应的value。
1.1.8 按value排序
1.1.9 遍历
1.2 常用其他方法
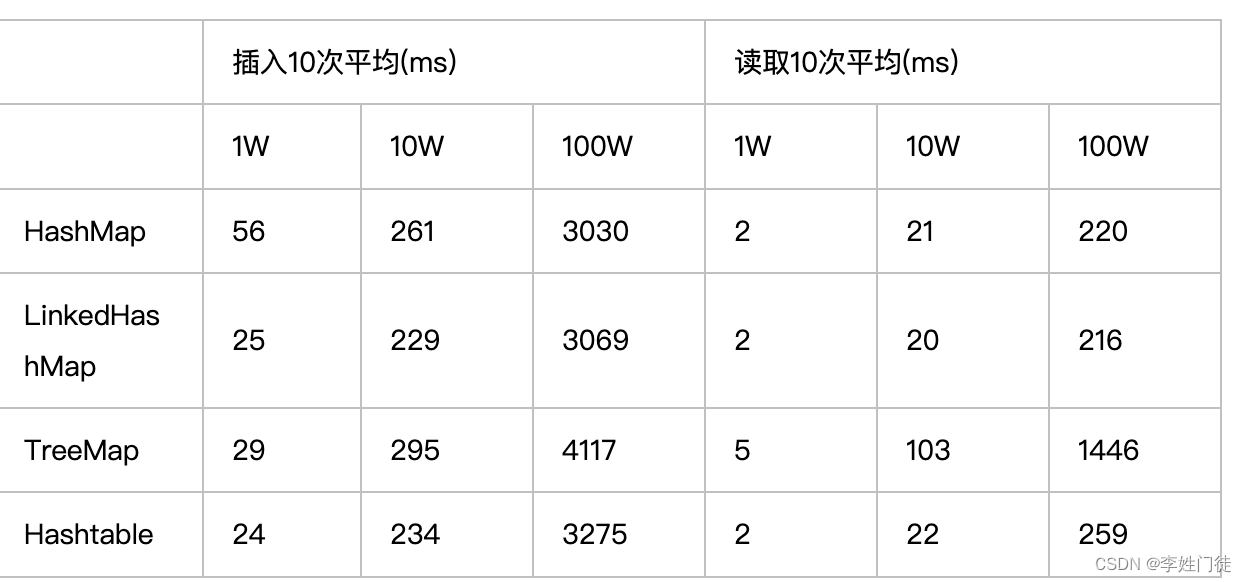
1.2.1 几种数据结构的对比
1.2.1 数据拷贝
1.2.1.1 赋值实现浅拷贝
1.2.1.1 Map.putAll()实现浅拷贝
1.2.1.1 HashMap.putAll()实深拷贝
2. Go
2.1基础操作
2.1.1 数据结构和定义方式
2.1.2 增加
2.1.3 修改
2.1.4 查询
2.1.5 删除
2.1.6 获取总长度
2.1.7 按key排序
2.1.8 按value排序
2.1.9 遍历
2.1.10 数据拷贝
2.1.10.1 赋值实现浅拷贝
2.1.10.2 赋值实现深拷贝
3. Python
3.1 列表
3.1.1 数据结构和定义方式
3.1.2 增加
3.1.3 修改
3.1.4 查询
3.1.5 删除
3.1.6 获取总长度
3.1.7 按key排序
3.1.8 按value排序
3.1.9 遍历
3.1.10 数据拷贝
3.1.10.1 赋值实现浅拷贝
3.1.10.2 赋值实现深拷贝
3.1.10.2 copy.copy()实现浅拷贝
2.3.4 copy.deepcopy()实现深拷贝
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[H数据结构] lc295. 数据流的中位数(对顶堆+技巧+思维+代码实现)](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)