批处理使处理更具并行性。但是,批处理意味着模型独立处理每一列;例如,上面示例中G和F的依赖关系无法学习。
from torchtext.datasets import WikiText2
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
train_iter = WikiText2(split='train')
tokenizer = get_tokenizer('basic_english')
vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>'])
vocab.set_default_index(vocab['<unk>'])
def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor:
"""Converts raw text into a flat Tensor."""
data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
# ``train_iter`` was "consumed" by the process of building the vocab,
# so we have to create it again
train_iter, val_iter, test_iter = WikiText2()
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batchify(data: Tensor, bsz: int) -> Tensor:
"""Divides the data into ``bsz`` separate sequences, removing extra elements
that wouldn't cleanly fit.
Arguments:
data: Tensor, shape ``[N]``
bsz: int, batch size
Returns:
Tensor of shape ``[N // bsz, bsz]``
"""
seq_len = data.size(0) // bsz
data = data[:seq_len * bsz]
data = data.view(bsz, seq_len).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size) # shape ``[seq_len, batch_size]``
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
生成输入和目标序列的函数
get_batch()为 transformer 模型生成一对输入-目标序列。它将源数据细分为长度为bptt的块。对于语言建模任务,模型需要以下单词作为Target。例如,对于bptt值为 2,我们会得到i=0 时的以下两个变量:
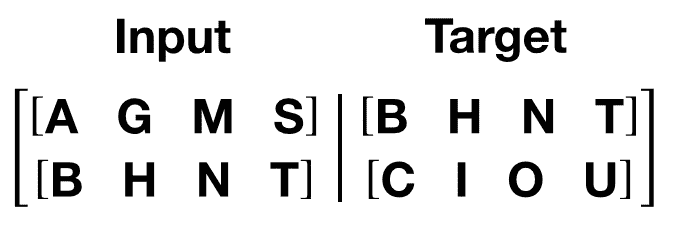
值得注意的是,分块沿着维度 0,与 Transformer 模型中的S维度一致。批处理维度N沿着维度 1。
bptt = 35
def get_batch(source: Tensor, i: int) -> Tuple[Tensor, Tensor]:
"""
Args:
source: Tensor, shape ``[full_seq_len, batch_size]``
i: int
Returns:
tuple (data, target), where data has shape ``[seq_len, batch_size]`` and
target has shape ``[seq_len * batch_size]``
"""
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].reshape(-1)
return data, target
初始化一个实例
模型超参数如下所定义。vocab大小等于词汇对象的长度。
ntokens = len(vocab) # size of vocabulary
emsize = 200 # embedding dimension
d_hid = 200 # dimension of the feedforward network model in ``nn.TransformerEncoder``
nlayers = 2 # number of ``nn.TransformerEncoderLayer`` in ``nn.TransformerEncoder``
nhead = 2 # number of heads in ``nn.MultiheadAttention``
dropout = 0.2 # dropout probability
model = TransformerModel(ntokens, emsize, nhead, d_hid, nlayers, dropout).to(device)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/transformer.py:286: UserWarning:
enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.self_attn.batch_first was not True(use batch_first for better inference performance)
运行模型
我们使用CrossEntropyLoss和SGD(随机梯度下降)优化器。学习率最初设置为 5.0,并遵循StepLR调度。在训练过程中,我们使用nn.utils.clip_grad_norm_来防止梯度爆炸。
import time
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
def train(model: nn.Module) -> None:
model.train() # turn on train mode
total_loss = 0.
log_interval = 200
start_time = time.time()
num_batches = len(train_data) // bptt
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
output = model(data)
output_flat = output.view(-1, ntokens)
loss = criterion(output_flat, targets)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
if batch % log_interval == 0 and batch > 0:
lr = scheduler.get_last_lr()[0]
ms_per_batch = (time.time() - start_time) * 1000 / log_interval
cur_loss = total_loss / log_interval
ppl = math.exp(cur_loss)
print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | '
f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | '
f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}')
total_loss = 0
start_time = time.time()
def evaluate(model: nn.Module, eval_data: Tensor) -> float:
model.eval() # turn on evaluation mode
total_loss = 0.
with torch.no_grad():
for i in range(0, eval_data.size(0) - 1, bptt):
data, targets = get_batch(eval_data, i)
seq_len = data.size(0)
output = model(data)
output_flat = output.view(-1, ntokens)
total_loss += seq_len * criterion(output_flat, targets).item()
return total_loss / (len(eval_data) - 1)
循环遍历每个 epoch。如果验证损失是迄今为止最佳的,则保存模型。每个 epoch 后调整学习率。
best_val_loss = float('inf')
epochs = 3
with TemporaryDirectory() as tempdir:
best_model_params_path = os.path.join(tempdir, "best_model_params.pt")
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(model)
val_loss = evaluate(model, val_data)
val_ppl = math.exp(val_loss)
elapsed = time.time() - epoch_start_time
print('-' * 89)
print(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | '
f'valid loss {val_loss:5.2f} | valid ppl {val_ppl:8.2f}')
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), best_model_params_path)
scheduler.step()
model.load_state_dict(torch.load(best_model_params_path)) # load best model states
| epoch 1 | 200/ 2928 batches | lr 5.00 | ms/batch 31.93 | loss 8.19 | ppl 3613.91
| epoch 1 | 400/ 2928 batches | lr 5.00 | ms/batch 28.57 | loss 6.88 | ppl 970.94
| epoch 1 | 600/ 2928 batches | lr 5.00 | ms/batch 28.31 | loss 6.43 | ppl 621.40
| epoch 1 | 800/ 2928 batches | lr 5.00 | ms/batch 28.48 | loss 6.30 | ppl 542.89
| epoch 1 | 1000/ 2928 batches | lr 5.00 | ms/batch 28.46 | loss 6.18 | ppl 484.73
| epoch 1 | 1200/ 2928 batches | lr 5.00 | ms/batch 28.32 | loss 6.15 | ppl 467.52
| epoch 1 | 1400/ 2928 batches | lr 5.00 | ms/batch 28.53 | loss 6.11 | ppl 450.65
| epoch 1 | 1600/ 2928 batches | lr 5.00 | ms/batch 28.45 | loss 6.11 | ppl 450.73
| epoch 1 | 1800/ 2928 batches | lr 5.00 | ms/batch 28.43 | loss 6.02 | ppl 410.39
| epoch 1 | 2000/ 2928 batches | lr 5.00 | ms/batch 28.56 | loss 6.01 | ppl 409.43
| epoch 1 | 2200/ 2928 batches | lr 5.00 | ms/batch 28.47 | loss 5.89 | ppl 361.18
| epoch 1 | 2400/ 2928 batches | lr 5.00 | ms/batch 28.57 | loss 5.97 | ppl 393.23
| epoch 1 | 2600/ 2928 batches | lr 5.00 | ms/batch 28.53 | loss 5.95 | ppl 383.85
| epoch 1 | 2800/ 2928 batches | lr 5.00 | ms/batch 28.59 | loss 5.88 | ppl 357.86
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 87.20s | valid loss 5.78 | valid ppl 324.74
-----------------------------------------------------------------------------------------
| epoch 2 | 200/ 2928 batches | lr 4.75 | ms/batch 28.74 | loss 5.86 | ppl 349.96
| epoch 2 | 400/ 2928 batches | lr 4.75 | ms/batch 28.60 | loss 5.85 | ppl 348.22
| epoch 2 | 600/ 2928 batches | lr 4.75 | ms/batch 28.49 | loss 5.66 | ppl 286.86
| epoch 2 | 800/ 2928 batches | lr 4.75 | ms/batch 28.39 | loss 5.70 | ppl 297.60
| epoch 2 | 1000/ 2928 batches | lr 4.75 | ms/batch 28.55 | loss 5.64 | ppl 282.01
| epoch 2 | 1200/ 2928 batches | lr 4.75 | ms/batch 28.56 | loss 5.67 | ppl 290.49
| epoch 2 | 1400/ 2928 batches | lr 4.75 | ms/batch 28.58 | loss 5.68 | ppl 292.36
| epoch 2 | 1600/ 2928 batches | lr 4.75 | ms/batch 28.64 | loss 5.70 | ppl 299.93
| epoch 2 | 1800/ 2928 batches | lr 4.75 | ms/batch 28.58 | loss 5.64 | ppl 282.54
| epoch 2 | 2000/ 2928 batches | lr 4.75 | ms/batch 28.50 | loss 5.66 | ppl 288.23
| epoch 2 | 2200/ 2928 batches | lr 4.75 | ms/batch 28.46 | loss 5.54 | ppl 254.44
| epoch 2 | 2400/ 2928 batches | lr 4.75 | ms/batch 28.58 | loss 5.65 | ppl 282.92
| epoch 2 | 2600/ 2928 batches | lr 4.75 | ms/batch 28.64 | loss 5.64 | ppl 282.54
| epoch 2 | 2800/ 2928 batches | lr 4.75 | ms/batch 28.57 | loss 5.58 | ppl 263.76
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 86.73s | valid loss 5.65 | valid ppl 282.95
-----------------------------------------------------------------------------------------
| epoch 3 | 200/ 2928 batches | lr 4.51 | ms/batch 28.69 | loss 5.60 | ppl 270.97
| epoch 3 | 400/ 2928 batches | lr 4.51 | ms/batch 28.55 | loss 5.62 | ppl 276.79
| epoch 3 | 600/ 2928 batches | lr 4.51 | ms/batch 28.65 | loss 5.42 | ppl 226.33
| epoch 3 | 800/ 2928 batches | lr 4.51 | ms/batch 28.59 | loss 5.48 | ppl 239.30
| epoch 3 | 1000/ 2928 batches | lr 4.51 | ms/batch 28.51 | loss 5.44 | ppl 229.71
| epoch 3 | 1200/ 2928 batches | lr 4.51 | ms/batch 28.55 | loss 5.48 | ppl 238.78
| epoch 3 | 1400/ 2928 batches | lr 4.51 | ms/batch 28.51 | loss 5.50 | ppl 243.54
| epoch 3 | 1600/ 2928 batches | lr 4.51 | ms/batch 28.56 | loss 5.52 | ppl 248.47
| epoch 3 | 1800/ 2928 batches | lr 4.51 | ms/batch 28.44 | loss 5.46 | ppl 235.26
| epoch 3 | 2000/ 2928 batches | lr 4.51 | ms/batch 28.37 | loss 5.48 | ppl 240.24
| epoch 3 | 2200/ 2928 batches | lr 4.51 | ms/batch 28.43 | loss 5.38 | ppl 217.29
| epoch 3 | 2400/ 2928 batches | lr 4.51 | ms/batch 28.44 | loss 5.47 | ppl 236.64
| epoch 3 | 2600/ 2928 batches | lr 4.51 | ms/batch 28.46 | loss 5.47 | ppl 237.76
| epoch 3 | 2800/ 2928 batches | lr 4.51 | ms/batch 28.49 | loss 5.40 | ppl 220.67
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 86.51s | valid loss 5.61 | valid ppl 273.90
-----------------------------------------------------------------------------------------
在测试数据集上评估最佳模型
test_loss = evaluate(model, test_data)
test_ppl = math.exp(test_loss)
print('=' * 89)
print(f'| End of training | test loss {test_loss:5.2f} | '
f'test ppl {test_ppl:8.2f}')
print('=' * 89)
=========================================================================================
| End of training | test loss 5.52 | test ppl 249.27
=========================================================================================
脚本的总运行时间:(4 分钟 31.006 秒)
下载 Python 源代码:transformer_tutorial.py
下载 Jupyter 笔记本:transformer_tutorial.ipynb
使用 Better Transformer 进行快速 Transformer 推理
原文:
pytorch.org/tutorials/beginner/bettertransformer_tutorial.html译者:飞龙
本教程将 Better Transformer(BT)作为 PyTorch 1.12 版本的一部分进行介绍。在本教程中,我们展示了如何使用 Better Transformer 进行 torchtext 的生产推理。Better Transformer 是一个生产就绪的快速路径,可加速在 CPU 和 GPU 上部署具有高性能的 Transformer 模型。快速路径功能对基于 PyTorch 核心nn.module或 torchtext 的模型透明地工作。
可以通过 Better Transformer 快速路径执行加速的模型是使用以下 PyTorch 核心torch.nn.module类TransformerEncoder、TransformerEncoderLayer和MultiHeadAttention的模型。此外,torchtext 已更新为使用核心库模块以从快速路径加速中受益。 (未来可能会启用其他模块以进行快速路径执行。)
Better Transformer 提供了两种加速类型:
-
为 CPU 和 GPU 实现的原生多头注意力(MHA)以提高整体执行效率。
-
利用 NLP 推理中的稀疏性。由于输入长度可变,输入标记可能包含大量填充标记,处理时可以跳过,从而实现显著加速。
快速路径执行受一些标准的限制。最重要的是,模型必须在推理模式下执行,并且在不收集梯度磁带信息的输入张量上运行(例如,使用 torch.no_grad 运行)。
要在 Google Colab 中查看此示例,请点击这里。
本教程中的 Better Transformer 功能
-
加载预训练模型(在 PyTorch 版本 1.12 之前创建,没有 Better Transformer)
-
在 CPU 上运行和基准推理,使用 BT 快速路径(仅原生 MHA)
-
在(可配置的)设备上运行和基准推理,使用 BT 快速路径(仅原生 MHA)
-
启用稀疏性支持
-
在(可配置的)设备上运行和基准推理,使用 BT 快速路径(原生 MHA + 稀疏性)
附加信息
有关 Better Transformer 的更多信息可以在 PyTorch.Org 博客A Better Transformer for Fast Transformer Inference中找到。
- 设置
1.1 加载预训练模型
我们通过按照torchtext.models中的说明从预定义的 torchtext 模型中下载 XLM-R 模型。我们还将设备设置为在加速器测试上执行。(根据需要启用 GPU 执行环境。)
import torch
import torch.nn as nn
print(f"torch version: {torch.__version__}")
DEVICE = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f"torch cuda available: {torch.cuda.is_available()}")
import torch, torchtext
from torchtext.models import RobertaClassificationHead
from torchtext.functional import to_tensor
xlmr_large = torchtext.models.XLMR_LARGE_ENCODER
classifier_head = torchtext.models.RobertaClassificationHead(num_classes=2, input_dim = 1024)
model = xlmr_large.get_model(head=classifier_head)
transform = xlmr_large.transform()
1.2 数据集设置
我们设置了两种类型的输入:一个小输入批次和一个带有稀疏性的大输入批次。
small_input_batch = [
"Hello world",
"How are you!"
]
big_input_batch = [
"Hello world",
"How are you!",
"""`Well, Prince, so Genoa and Lucca are now just family estates of the
Buonapartes. But I warn you, if you don't tell me that this means war,
if you still try to defend the infamies and horrors perpetrated by
that Antichrist- I really believe he is Antichrist- I will have
nothing more to do with you and you are no longer my friend, no longer
my 'faithful slave,' as you call yourself! But how do you do? I see
I have frightened you- sit down and tell me all the news.`
It was in July, 1805, and the speaker was the well-known Anna
Pavlovna Scherer, maid of honor and favorite of the Empress Marya
Fedorovna. With these words she greeted Prince Vasili Kuragin, a man
of high rank and importance, who was the first to arrive at her
reception. Anna Pavlovna had had a cough for some days. She was, as
she said, suffering from la grippe; grippe being then a new word in
St. Petersburg, used only by the elite."""
]
接下来,我们选择小批量或大批量输入,预处理输入并测试模型。
input_batch=big_input_batch
model_input = to_tensor(transform(input_batch), padding_value=1)
output = model(model_input)
output.shape
最后,我们设置基准迭代次数:
ITERATIONS=10
- 执行
在 CPU 上运行和基准推理,使用 BT 快速路径(仅原生 MHA)
我们在 CPU 上运行模型,并收集性能信息:
-
第一次运行使用传统(“慢速路径”)执行。
-
第二次运行通过将模型置于推理模式并使用 model.eval()启用 BT 快速路径执行,并使用 torch.no_grad()禁用梯度收集。
当模型在 CPU 上执行时,您会看到改进(其幅度取决于 CPU 模型)。请注意,快速路径概要显示大部分执行时间在本地 TransformerEncoderLayer 实现 aten::_transformer_encoder_layer_fwd 中。
print("slow path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=False) as prof:
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
model.eval()
print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=False) as prof:
with torch.no_grad():
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
在(可配置的)设备上运行和基准推理,使用 BT 快速路径(仅原生 MHA)
我们检查 BT 的稀疏性设置:
model.encoder.transformer.layers.enable_nested_tensor
我们禁用了 BT 的稀疏性:
model.encoder.transformer.layers.enable_nested_tensor=False
我们在设备上运行模型,并收集用于设备上原生 MHA 执行的性能信息:
-
第一次运行使用传统的(“慢路径”)执行。
-
第二次运行通过将模型置于推理模式并使用 model.eval()禁用梯度收集来启用 BT 快速执行路径。
在 GPU 上执行时,您应该看到显着的加速,特别是对于小输入批处理设置:
model.to(DEVICE)
model_input = model_input.to(DEVICE)
print("slow path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
model.eval()
print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:
with torch.no_grad():
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
2.3 在(可配置的)DEVICE 上运行和对比推理,包括 BT 快速执行路径和不包括 BT 快速执行路径(原生 MHA + 稀疏性)
我们启用稀疏性支持:
model.encoder.transformer.layers.enable_nested_tensor = True
我们在 DEVICE 上运行模型,并收集原生 MHA 和稀疏性支持在 DEVICE 上的执行的概要信息:
-
第一次运行使用传统的(“慢路径”)执行。
-
第二次运行通过将模型置于推理模式并使用 model.eval()禁用梯度收集来启用 BT 快速执行路径。
在 GPU 上执行时,您应该看到显着的加速,特别是对于包含稀疏性的大输入批处理设置:
model.to(DEVICE)
model_input = model_input.to(DEVICE)
print("slow path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
model.eval()
print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:
with torch.no_grad():
for i in range(ITERATIONS):
output = model(model_input)
print(prof)
总结
在本教程中,我们介绍了在 torchtext 中使用 PyTorch 核心 Better Transformer 支持 Transformer 编码器模型的快速变压器推理。我们演示了在 BT 快速执行路径可用之前训练的模型中使用 Better Transformer 的方法。我们演示并对比了 BT 快速执行路径模式、原生 MHA 执行和 BT 稀疏性加速的使用。
从头开始的自然语言处理:使用字符级 RNN 对名称进行分类
原文:
pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html译者:飞龙
注意
点击这里下载完整的示例代码
我们将构建和训练一个基本的字符级循环神经网络(RNN)来对单词进行分类。本教程以及其他两个“从头开始”的自然语言处理(NLP)教程 NLP From Scratch: Generating Names with a Character-Level RNN 和 NLP From Scratch: Translation with a Sequence to Sequence Network and Attention,展示了如何预处理数据以建模 NLP。特别是这些教程不使用 torchtext 的许多便利函数,因此您可以看到如何在低级别上处理 NLP 以建模 NLP。
字符级 RNN 将单词作为一系列字符读取 – 在每一步输出一个预测和“隐藏状态”,将其先前的隐藏状态馈送到每个下一步。我们将最终预测视为输出,即单词属于哪个类别。
具体来说,我们将在来自 18 种语言的几千个姓氏上进行训练,并根据拼写预测名称来自哪种语言:
$ python predict.py Hinton
(-0.47) Scottish
(-1.52) English
(-3.57) Irish
$ python predict.py Schmidhuber
(-0.19) German
(-2.48) Czech
(-2.68) Dutch
推荐准备工作
在开始本教程之前,建议您已经安装了 PyTorch,并对 Python 编程语言和张量有基本的了解:
-
pytorch.org/获取安装说明 -
使用 PyTorch 进行深度学习:60 分钟入门以开始使用 PyTorch 并学习张量的基础知识
-
通过示例学习 PyTorch 提供广泛和深入的概述
-
如果您以前是 Lua Torch 用户,请参阅 PyTorch for Former Torch Users
了解 RNN 以及它们的工作原理也会很有用:
-
循环神经网络的不合理有效性展示了一堆现实生活中的例子
-
理解 LSTM 网络专门讨论 LSTMs,但也对 RNNs 有启发性
准备数据
注意
从这里下载数据并将其解压缩到当前目录。
data/names目录中包含 18 个名为[Language].txt的文本文件。每个文件包含一堆名称,每行一个名称,大多数是罗马化的(但我们仍然需要从 Unicode 转换为 ASCII)。
我们最终会得到一个字典,其中包含每种语言的名称列表,{language: [names ...]}。通用变量“category”和“line”(在我们的案例中用于语言和名称)用于以后的可扩展性。
from io import open
import glob
import os
def findFiles(path): return glob.glob(path)
print(findFiles('data/names/*.txt'))
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
print(unicodeToAscii('Ślusàrski'))
# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []
# Read a file and split into lines
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('n')
return [unicodeToAscii(line) for line in lines]
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
['data/names/Arabic.txt', 'data/names/Chinese.txt', 'data/names/Czech.txt', 'data/names/Dutch.txt', 'data/names/English.txt', 'data/names/French.txt', 'data/names/German.txt', 'data/names/Greek.txt', 'data/names/Irish.txt', 'data/names/Italian.txt', 'data/names/Japanese.txt', 'data/names/Korean.txt', 'data/names/Polish.txt', 'data/names/Portuguese.txt', 'data/names/Russian.txt', 'data/names/Scottish.txt', 'data/names/Spanish.txt', 'data/names/Vietnamese.txt']
Slusarski
现在我们有category_lines,一个将每个类别(语言)映射到一系列行(名称)的字典。我们还跟踪了all_categories(只是一个语言列表)和n_categories以供以后参考。
print(category_lines['Italian'][:5])
['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni']
将名称转换为张量
现在我们已经组织好所有的名称,我们需要将它们转换为张量以便使用。
为了表示单个字母,我们使用大小为<1 x n_letters>的“one-hot 向量”。一个 one-hot 向量除了当前字母的索引处为 1 之外,其他位置都填充为 0,例如,"b" = <0 1 0 0 0 ...>。
为了构成一个单词,我们将其中的一堆连接成一个 2D 矩阵<line_length x 1 x n_letters>。
额外的 1 维是因为 PyTorch 假设一切都是批处理 – 我们这里只是使用批处理大小为 1。
import torch
# Find letter index from all_letters, e.g. "a" = 0
def letterToIndex(letter):
return all_letters.find(letter)
# Just for demonstration, turn a letter into a <1 x n_letters> Tensor
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
# Turn a line into a <line_length x 1 x n_letters>,
# or an array of one-hot letter vectors
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
print(letterToTensor('J'))
print(lineToTensor('Jones').size())
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.]])
torch.Size([5, 1, 57])
创建网络
在自动求导之前,在 Torch 中创建一个循环神经网络涉及在几个时间步上克隆层的参数。这些层保存了隐藏状态和梯度,现在完全由图本身处理。这意味着您可以以非常“纯粹”的方式实现 RNN,就像常规的前馈层一样。
这个 RNN 模块(主要是从PyTorch for Torch 用户教程中复制的)只是在输入和隐藏状态上操作的 2 个线性层,输出后是一个LogSoftmax层。
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.h2o(hidden)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)
要运行此网络的一步,我们需要传递一个输入(在我们的情况下,是当前字母的张量)和一个先前的隐藏状态(最初我们将其初始化为零)。我们将得到输出(每种语言的概率)和下一个隐藏状态(我们将其保留到下一步)。
input = letterToTensor('A')
hidden = torch.zeros(1, n_hidden)
output, next_hidden = rnn(input, hidden)
为了提高效率,我们不希望为每一步创建一个新的张量,因此我们将使用lineToTensor代替letterToTensor并使用切片。这可以通过预先计算批量张量来进一步优化。
input = lineToTensor('Albert')
hidden = torch.zeros(1, n_hidden)
output, next_hidden = rnn(input[0], hidden)
print(output)
tensor([[-2.9083, -2.9270, -2.9167, -2.9590, -2.9108, -2.8332, -2.8906, -2.8325,
-2.8521, -2.9279, -2.8452, -2.8754, -2.8565, -2.9733, -2.9201, -2.8233,
-2.9298, -2.8624]], grad_fn=<LogSoftmaxBackward0>)
如您所见,输出是一个<1 x n_categories>张量,其中每个项目都是该类别的可能性(可能性越高,越可能)。
训练
为训练做准备
在进行训练之前,我们应该编写一些辅助函数。第一个是解释网络输出的函数,我们知道它是每个类别的可能性。我们可以使用Tensor.topk来获取最大值的索引:
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
print(categoryFromOutput(output))
('Scottish', 15)
我们还希望快速获取一个训练示例(一个名称及其语言):
import random
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
def randomTrainingExample():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
for i in range(10):
category, line, category_tensor, line_tensor = randomTrainingExample()
print('category =', category, '/ line =', line)
category = Chinese / line = Hou
category = Scottish / line = Mckay
category = Arabic / line = Cham
category = Russian / line = V'Yurkov
category = Irish / line = O'Keeffe
category = French / line = Belrose
category = Spanish / line = Silva
category = Japanese / line = Fuchida
category = Greek / line = Tsahalis
category = Korean / line = Chang
训练网络
现在训练这个网络所需的全部工作就是向其展示一堆示例,让它猜测,并告诉它是否错误。
对于损失函数,nn.NLLLoss是合适的,因为 RNN 的最后一层是nn.LogSoftmax。
criterion = nn.NLLLoss()
每次训练循环将:
-
创建输入和目标张量
-
创建一个初始化的零隐藏状态
-
逐个读取每个字母
- 保留下一个字母的隐藏状态
-
将最终输出与目标进行比较
-
反向传播
-
返回输出和损失
learning_rate = 0.005 # If you set this too high, it might explode. If too low, it might not learn
def train(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
loss = criterion(output, category_tensor)
loss.backward()
# Add parameters' gradients to their values, multiplied by learning rate
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
现在我们只需运行一堆示例。由于train函数返回输出和损失,我们可以打印其猜测并跟踪损失以绘图。由于有成千上万的示例,我们仅打印每print_every个示例,并计算损失的平均值。
import time
import math
n_iters = 100000
print_every = 5000
plot_every = 1000
# Keep track of losses for plotting
current_loss = 0
all_losses = []
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
start = time.time()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# Print ``iter`` number, loss, name and guess
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# Add current loss avg to list of losses
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
5000 5% (0m 29s) 2.6379 Horigome / Japanese ✓
10000 10% (0m 58s) 2.0172 Miazga / Japanese ✗ (Polish)
15000 15% (1m 29s) 0.2680 Yukhvidov / Russian ✓
20000 20% (1m 58s) 1.8239 Mclaughlin / Irish ✗ (Scottish)
25000 25% (2m 29s) 0.6978 Banh / Vietnamese ✓
30000 30% (2m 58s) 1.7433 Machado / Japanese ✗ (Portuguese)
35000 35% (3m 28s) 0.0340 Fotopoulos / Greek ✓
40000 40% (3m 58s) 1.4637 Quirke / Irish ✓
45000 45% (4m 28s) 1.9018 Reier / French ✗ (German)
50000 50% (4m 57s) 0.9174 Hou / Chinese ✓
55000 55% (5m 27s) 1.0506 Duan / Vietnamese ✗ (Chinese)
60000 60% (5m 57s) 0.9617 Giang / Vietnamese ✓
65000 65% (6m 27s) 2.4557 Cober / German ✗ (Czech)
70000 70% (6m 57s) 0.8502 Mateus / Portuguese ✓
75000 75% (7m 26s) 0.2750 Hamilton / Scottish ✓
80000 80% (7m 56s) 0.7515 Maessen / Dutch ✓
85000 85% (8m 26s) 0.0912 Gan / Chinese ✓
90000 90% (8m 55s) 0.1190 Bellomi / Italian ✓
95000 95% (9m 25s) 0.0137 Vozgov / Russian ✓
100000 100% (9m 55s) 0.7808 Tong / Vietnamese ✓
绘制结果
绘制all_losses中的历史损失可以显示网络的学习情况:
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)
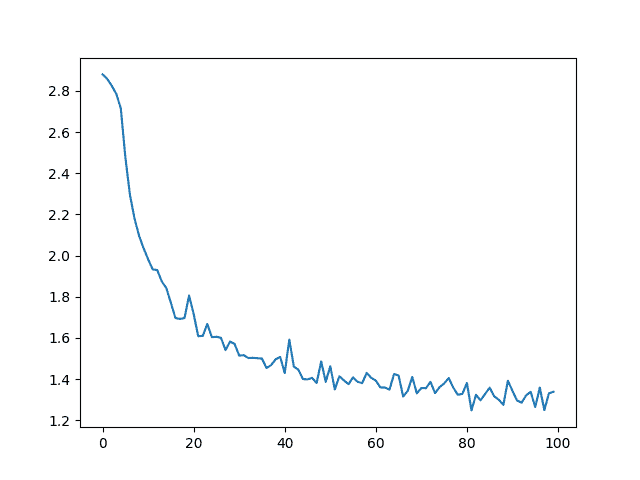
[<matplotlib.lines.Line2D object at 0x7f4d28129de0>]
评估结果
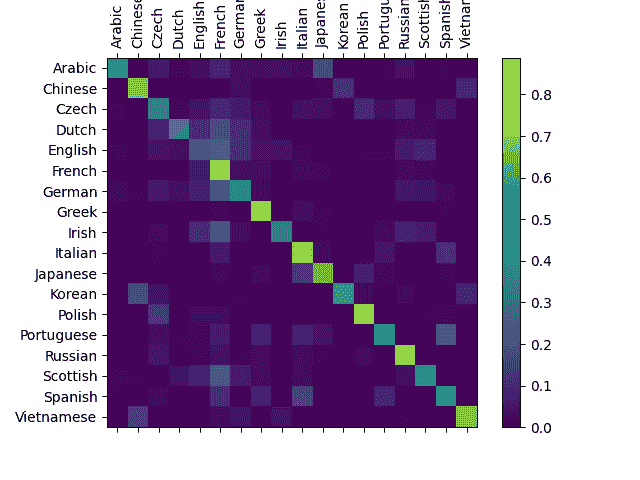
为了查看网络在不同类别上的表现如何,我们将创建一个混淆矩阵,指示对于每种实际语言(行),网络猜测的是哪种语言(列)。为了计算混淆矩阵,一堆样本通过网络运行evaluate(),这与train()相同,但没有反向传播。
# Keep track of correct guesses in a confusion matrix
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
# Just return an output given a line
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
# Go through a bunch of examples and record which are correctly guessed
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample()
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()
/var/lib/jenkins/workspace/intermediate_source/char_rnn_classification_tutorial.py:445: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
/var/lib/jenkins/workspace/intermediate_source/char_rnn_classification_tutorial.py:446: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
您可以从主轴上的亮点中挑选出显示它错误猜测的语言,例如将韩语错误猜测为中文,将意大利语错误猜测为西班牙语。它在希腊语方面表现得非常好,但在英语方面表现非常糟糕(可能是因为与其他语言的重叠)。
在用户输入上运行
def predict(input_line, n_predictions=3):
print('n> %s' % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
# Get top N categories
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print('(%.2f) %s' % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')
> Dovesky
(-0.57) Czech
(-0.97) Russian
(-3.43) English
> Jackson
(-1.02) Scottish
(-1.49) Russian
(-1.96) English
> Satoshi
(-0.42) Japanese
(-1.70) Polish
(-2.74) Italian
脚本的最终版本在Practical PyTorch 存储库中将上述代码拆分为几个文件:
-
data.py(加载文件) -
model.py(定义 RNN) -
train.py(运行训练) -
predict.py(使用命令行参数运行predict()) -
server.py(使用bottle.py作为 JSON API 提供预测)
运行train.py以训练并保存网络。
运行predict.py并输入一个名称以查看预测:
$ python predict.py Hazaki
(-0.42) Japanese
(-1.39) Polish
(-3.51) Czech
运行server.py并访问localhost:5533/Yourname以获取预测的 JSON 输出。
练习
-
尝试使用不同的行 -> 类别数据集,例如:
-
任何单词 -> 语言
-
首先姓名 -> 性别
-
角色名称 -> 作者
-
页面标题 -> 博客或子论坛
-
-
通过一个更大和/或更好形状的网络获得更好的结果
-
添加更多线性层
-
尝试
nn.LSTM和nn.GRU层 -
将多个这些 RNN 组合成一个更高级的网络
-
脚本的总运行时间:(10 分钟 4.936 秒)
下载 Python 源代码:char_rnn_classification_tutorial.py
下载 Jupyter 笔记本:char_rnn_classification_tutorial.ipynb
从零开始的 NLP:使用字符级 RNN 生成名字
原文:
pytorch.org/tutorials/intermediate/char_rnn_generation_tutorial.html译者:飞龙
注意
点击这里下载完整的示例代码
这是我们关于“从零开始的 NLP”的三个教程中的第二个。在第一个教程中,我们使用 RNN 将名字分类到其语言来源。这一次我们将转而生成不同语言的名字。
> python sample.py Russian RUS
Rovakov
Uantov
Shavakov
> python sample.py German GER
Gerren
Ereng
Rosher
> python sample.py Spanish SPA
Salla
Parer
Allan
> python sample.py Chinese CHI
Chan
Hang
Iun
我们仍然手工制作一个小型 RNN,其中包含几个线性层。最大的区别是,我们不是在读取名字的所有字母后预测类别,而是输入一个类别,并逐个输出一个字母。循环地预测字符以形成语言(这也可以用单词或其他更高级别的结构来完成)通常被称为“语言模型”。
推荐阅读:
我假设您至少已经安装了 PyTorch,了解 Python,并理解张量:
-
pytorch.org/安装说明 -
使用 PyTorch 进行深度学习:60 分钟入门 以一般性的 PyTorch 开始
-
使用示例学习 PyTorch 进行广泛和深入的概述
-
PyTorch for Former Torch Users 如果您以前是 Lua Torch 用户
了解 RNN 以及它们的工作原理也会很有用:
-
循环神经网络的非凡有效性展示了一堆真实生活中的例子
-
理解 LSTM 网络 是关于 LSTMs 的,但也对 RNNs 有一般性的信息
我还建议查看之前的教程,从零开始的 NLP:使用字符级 RNN 对名字进行分类
准备数据
注意
从这里下载数据并将其解压到当前目录。
有关此过程的更多详细信息,请参阅上一个教程。简而言之,有一堆纯文本文件data/names/[Language].txt,每行一个名字。我们将行拆分为数组,将 Unicode 转换为 ASCII,最终得到一个字典{language: [names ...]}。
from io import open
import glob
import os
import unicodedata
import string
all_letters = string.ascii_letters + " .,;'-"
n_letters = len(all_letters) + 1 # Plus EOS marker
def findFiles(path): return glob.glob(path)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
# Read a file and split into lines
def readLines(filename):
with open(filename, encoding='utf-8') as some_file:
return [unicodeToAscii(line.strip()) for line in some_file]
# Build the category_lines dictionary, a list of lines per category
category_lines = {}
all_categories = []
for filename in findFiles('data/names/*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
if n_categories == 0:
raise RuntimeError('Data not found. Make sure that you downloaded data '
'from https://download.pytorch.org/tutorial/data.zip and extract it to '
'the current directory.')
print('# categories:', n_categories, all_categories)
print(unicodeToAscii("O'Néàl"))
# categories: 18 ['Arabic', 'Chinese', 'Czech', 'Dutch', 'English', 'French', 'German', 'Greek', 'Irish', 'Italian', 'Japanese', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Scottish', 'Spanish', 'Vietnamese']
O'Neal
创建网络
这个网络扩展了上一个教程的 RNN,增加了一个额外的参数用于类别张量,该参数与其他参数一起连接。类别张量是一个独热向量,就像字母输入一样。
我们将解释输出为下一个字母的概率。在采样时,最有可能的输出字母将被用作下一个输入字母。
我添加了第二个线性层o2o(在隐藏和输出合并后)以增加其处理能力。还有一个 dropout 层,它会随机将其输入的部分置零以给定的概率(这里是 0.1),通常用于模糊输入以防止过拟合。在网络末尾使用它是为了故意增加一些混乱并增加采样的多样性。

import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
input_combined = torch.cat((category, input, hidden), 1)
hidden = self.i2h(input_combined)
output = self.i2o(input_combined)
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
训练
准备训练
首先,编写帮助函数以获取随机的(类别,行)对:
import random
# Random item from a list
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
# Get a random category and random line from that category
def randomTrainingPair():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
return category, line
对于每个时间步(即训练单词中的每个字母),网络的输入将是(类别,当前字母,隐藏状态),输出将是(下一个字母,下一个隐藏状态)。因此,对于每个训练集,我们需要类别、一组输入字母和一组输出/目标字母。
由于我们正在预测每个时间步的下一个字母,所以字母对是来自行中连续字母的组 – 例如对于"ABCD<EOS>",我们将创建(“A”, “B”), (“B”, “C”), (“C”, “D”), (“D”, “EOS”)。

类别张量是一个大小为<1 x n_categories>的独热张量。在训练时,我们在每个时间步将其馈送到网络中 – 这是一个设计选择,它可以作为初始隐藏状态的一部分或其他策略的一部分。
# One-hot vector for category
def categoryTensor(category):
li = all_categories.index(category)
tensor = torch.zeros(1, n_categories)
tensor[0][li] = 1
return tensor
# One-hot matrix of first to last letters (not including EOS) for input
def inputTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li in range(len(line)):
letter = line[li]
tensor[li][0][all_letters.find(letter)] = 1
return tensor
# ``LongTensor`` of second letter to end (EOS) for target
def targetTensor(line):
letter_indexes = [all_letters.find(line[li]) for li in range(1, len(line))]
letter_indexes.append(n_letters - 1) # EOS
return torch.LongTensor(letter_indexes)
为了方便训练,我们将创建一个randomTrainingExample函数,该函数获取一个随机的(类别,行)对,并将它们转换为所需的(类别,输入,目标)张量。
# Make category, input, and target tensors from a random category, line pair
def randomTrainingExample():
category, line = randomTrainingPair()
category_tensor = categoryTensor(category)
input_line_tensor = inputTensor(line)
target_line_tensor = targetTensor(line)
return category_tensor, input_line_tensor, target_line_tensor
训练网络
与分类不同,分类只使用最后一个输出,我们在每一步都在做预测,因此我们在每一步都在计算损失。
自动微分的魔力使您可以简单地在每一步总结这些损失,并在最后调用反向传播。
criterion = nn.NLLLoss()
learning_rate = 0.0005
def train(category_tensor, input_line_tensor, target_line_tensor):
target_line_tensor.unsqueeze_(-1)
hidden = rnn.initHidden()
rnn.zero_grad()
loss = torch.Tensor([0]) # you can also just simply use ``loss = 0``
for i in range(input_line_tensor.size(0)):
output, hidden = rnn(category_tensor, input_line_tensor[i], hidden)
l = criterion(output, target_line_tensor[i])
loss += l
loss.backward()
for p in rnn.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item() / input_line_tensor.size(0)
为了跟踪训练需要多长时间,我添加了一个timeSince(timestamp)函数,它返回一个可读的字符串:
import time
import math
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
训练就像往常一样 – 多次调用 train 并等待几分钟,每print_every个示例打印当前时间和损失,并在all_losses中保留每plot_every个示例的平均损失以供稍后绘图。
rnn = RNN(n_letters, 128, n_letters)
n_iters = 100000
print_every = 5000
plot_every = 500
all_losses = []
total_loss = 0 # Reset every ``plot_every`` ``iters``
start = time.time()
for iter in range(1, n_iters + 1):
output, loss = train(*randomTrainingExample())
total_loss += loss
if iter % print_every == 0:
print('%s (%d %d%%) %.4f' % (timeSince(start), iter, iter / n_iters * 100, loss))
if iter % plot_every == 0:
all_losses.append(total_loss / plot_every)
total_loss = 0
0m 9s (5000 5%) 3.1506
0m 18s (10000 10%) 2.5070
0m 28s (15000 15%) 3.3047
0m 37s (20000 20%) 2.4247
0m 47s (25000 25%) 2.6406
0m 56s (30000 30%) 2.0266
1m 5s (35000 35%) 2.6520
1m 15s (40000 40%) 2.4261
1m 24s (45000 45%) 2.2302
1m 33s (50000 50%) 1.6496
1m 43s (55000 55%) 2.7101
1m 52s (60000 60%) 2.5396
2m 1s (65000 65%) 2.5978
2m 11s (70000 70%) 1.6029
2m 20s (75000 75%) 0.9634
2m 29s (80000 80%) 3.0950
2m 39s (85000 85%) 2.0512
2m 48s (90000 90%) 2.5302
2m 57s (95000 95%) 3.2365
3m 7s (100000 100%) 1.7113
绘制损失
从all_losses中绘制历史损失显示网络学习:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(all_losses)
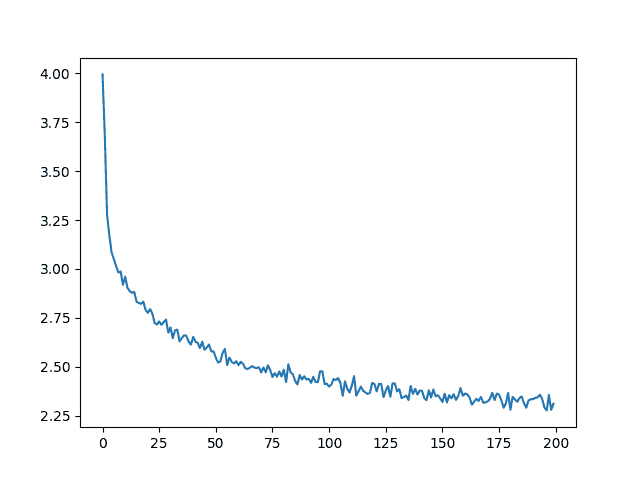
[<matplotlib.lines.Line2D object at 0x7fcf36ff04c0>]
对网络进行采样
为了采样,我们给网络一个字母,并询问下一个是什么,将其作为下一个字母馈送进去,并重复,直到 EOS 令牌。
-
为输入类别、起始字母和空隐藏状态创建张量
-
创建一个字符串
output_name,以起始字母开始 -
在最大输出长度之内,
-
将当前字母馈送到网络
-
从最高输出中获取下一个字母,并获取下一个隐藏状态
-
如果字母是 EOS,则在此停止
-
如果是常规字母,则添加到
output_name并继续
-
-
返回最终名称
注意
与其必须给出一个起始字母,另一种策略是在训练中包含一个“字符串开始”标记,并让网络选择自己的起始字母。
max_length = 20
# Sample from a category and starting letter
def sample(category, start_letter='A'):
with torch.no_grad(): # no need to track history in sampling
category_tensor = categoryTensor(category)
input = inputTensor(start_letter)
hidden = rnn.initHidden()
output_name = start_letter
for i in range(max_length):
output, hidden = rnn(category_tensor, input[0], hidden)
topv, topi = output.topk(1)
topi = topi[0][0]
if topi == n_letters - 1:
break
else:
letter = all_letters[topi]
output_name += letter
input = inputTensor(letter)
return output_name
# Get multiple samples from one category and multiple starting letters
def samples(category, start_letters='ABC'):
for start_letter in start_letters:
print(sample(category, start_letter))
samples('Russian', 'RUS')
samples('German', 'GER')
samples('Spanish', 'SPA')
samples('Chinese', 'CHI')
Rovaki
Uarinovev
Shinan
Gerter
Eeren
Roune
Santera
Paneraz
Allan
Chin
Han
Ion
练习
-
尝试使用不同的类别 -> 行数据集,例如:
-
虚构系列 -> 角色名称
-
词性 -> 单词
-
国家 -> 城市
-
-
使用“句子开始”标记,以便可以进行采样而无需选择起始字母
-
通过更大和/或更好形状的网络获得更好的结果
-
尝试使用
nn.LSTM和nn.GRU层 -
将多个这些 RNN 组合为更高级别的网络
-
脚本的总运行时间:(3 分钟 7.253 秒)
下载 Python 源代码:char_rnn_generation_tutorial.py
下载 Jupyter 笔记本:char_rnn_generation_tutorial.ipynb
NLP 从头开始:使用序列到序列网络和注意力进行翻译
原文:
pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html译者:飞龙
注意
点击这里下载完整的示例代码
这是关于“从头开始进行 NLP”的第三个也是最后一个教程,在这里我们编写自己的类和函数来预处理数据以执行 NLP 建模任务。我们希望在您完成本教程后,您将继续学习 torchtext 如何在接下来的三个教程中为您处理大部分预处理工作。
在这个项目中,我们将教授神经网络从法语翻译成英语。
[KEY: > input, = target, < output]
> il est en train de peindre un tableau .
= he is painting a picture .
< he is painting a picture .
> pourquoi ne pas essayer ce vin delicieux ?
= why not try that delicious wine ?
< why not try that delicious wine ?
> elle n est pas poete mais romanciere .
= she is not a poet but a novelist .
< she not not a poet but a novelist .
> vous etes trop maigre .
= you re too skinny .
< you re all alone .
… 成功程度各不相同。
这得益于序列到序列网络的简单而强大的思想,其中两个递归神经网络共同工作,将一个序列转换为另一个序列。编码器网络将输入序列压缩为向量,解码器网络将该向量展开为新序列。
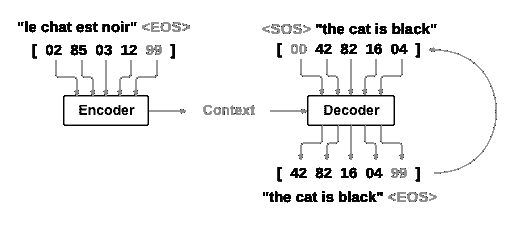
为了改进这个模型,我们将使用注意机制,让解码器学会专注于输入序列的特定范围。
推荐阅读:
我假设您至少已经安装了 PyTorch,了解 Python,并理解张量:
-
pytorch.org/安装说明 -
使用 PyTorch 进行深度学习:60 分钟快速入门 以开始使用 PyTorch
-
使用示例学习 PyTorch 以获取广泛而深入的概述
-
PyTorch for Former Torch Users 如果您以前是 Lua Torch 用户
了解序列到序列网络以及它们的工作原理也会很有用:
您还会发现之前的教程 NLP 从头开始:使用字符级 RNN 对名字进行分类和 NLP 从头开始:使用字符级 RNN 生成名字对理解编码器和解码器模型非常有帮助。
要求
from __future__ import unicode_literals, print_function, division
from io import open
import unicodedata
import re
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
import numpy as np
from torch.utils.data import TensorDataset, DataLoader, RandomSampler
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
加载数据文件
这个项目的数据是成千上万个英语到法语翻译对的集合。
Open Data Stack Exchange 上的这个问题指向了开放翻译网站tatoeba.org/,可以在tatoeba.org/eng/downloads下载数据 – 更好的是,有人额外工作将语言对拆分为单独的文本文件,位于这里:www.manythings.org/anki/
英语到法语的翻译对太大,无法包含在存储库中,请在继续之前下载到data/eng-fra.txt。该文件是一个制表符分隔的翻译对列表:
I am cold. J'ai froid.
注意
从这里下载数据并将其解压到当前目录。
类似于字符级 RNN 教程中使用的字符编码,我们将每个语言中的每个单词表示为一个独热向量,或者除了一个单一的一之外全为零的巨大向量(在单词的索引处)。与语言中可能存在的几十个字符相比,单词要多得多,因此编码向量要大得多。但我们会稍微作弊,只使用每种语言中的几千个单词来修剪数据。
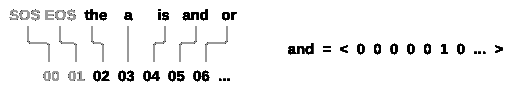
我们将需要每个单词的唯一索引,以便稍后用作网络的输入和目标。为了跟踪所有这些,我们将使用一个名为Lang的辅助类,其中包含单词→索引(word2index)和索引→单词(index2word)字典,以及每个单词的计数word2count,稍后将用于替换稀有单词。
SOS_token = 0
EOS_token = 1
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
所有文件都是 Unicode 格式,为了简化,我们将 Unicode 字符转换为 ASCII,将所有内容转换为小写,并修剪大部分标点符号。
# Turn a Unicode string to plain ASCII, thanks to
# https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" 1", s)
s = re.sub(r"[^a-zA-Z!?]+", r" ", s)
return s.strip()
为了读取数据文件,我们将文件拆分成行,然后将行拆分成对。所有文件都是英语→其他语言,因此如果我们想要从其他语言→英语翻译,我添加了reverse标志以反转对。
def readLangs(lang1, lang2, reverse=False):
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').
read().strip().split('n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('t')] for l in lines]
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
由于有很多例句并且我们想要快速训练一些东西,我们将数据集修剪为相对较短和简单的句子。这里最大长度为 10 个单词(包括结束标点符号),我们正在过滤翻译为“I am”或“He is”等形式的句子(考虑之前替换的省略号)。
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and
len(p[1].split(' ')) < MAX_LENGTH and
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
准备数据的完整过程是:
-
读取文本文件并拆分成行,将行拆分成对
-
规范化文本,按长度和内容过滤
-
从成对句子中制作单词列表
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print("Read %s sentence pairs" % len(pairs))
pairs = filterPairs(pairs)
print("Trimmed to %s sentence pairs" % len(pairs))
print("Counting words...")
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("Counted words:")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
print(random.choice(pairs))
Reading lines...
Read 135842 sentence pairs
Trimmed to 11445 sentence pairs
Counting words...
Counted words:
fra 4601
eng 2991
['tu preches une convaincue', 'you re preaching to the choir']
Seq2Seq 模型
循环神经网络(RNN)是一个在序列上操作并将其自身输出用作后续步骤输入的网络。
Sequence to Sequence network,或 seq2seq 网络,或编码器解码器网络,是由两个称为编码器和解码器的 RNN 组成的模型。编码器读取输入序列并输出一个单一向量,解码器读取该向量以产生一个输出序列。
与单个 RNN 进行序列预测不同,其中每个输入对应一个输出,seq2seq 模型使我们摆脱了序列长度和顺序的限制,这使其非常适合两种语言之间的翻译。
考虑句子Je ne suis pas le chat noir → I am not the black cat。输入句子中的大多数单词在输出句子中有直接的翻译,但顺序略有不同,例如chat noir和black cat。由于ne/pas结构,在输入句子中还有一个单词。直接从输入单词序列中产生正确的翻译将会很困难。
使用 seq2seq 模型,编码器创建一个单一向量,理想情况下,将输入序列的“含义”编码为一个单一向量——一个句子空间中的单一点。
编码器
seq2seq 网络的编码器是一个 RNN,它为输入句子中的每个单词输出某个值。对于每个输入单词,编码器输出一个向量和一个隐藏状态,并将隐藏状态用于下一个输入单词。
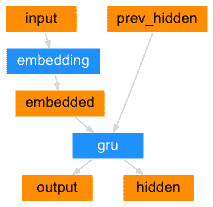
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout_p=0.1):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.dropout = nn.Dropout(dropout_p)
def forward(self, input):
embedded = self.dropout(self.embedding(input))
output, hidden = self.gru(embedded)
return output, hidden
解码器
解码器是另一个 RNN,它接收编码器输出的向量,并输出一系列单词以创建翻译。
简单解码器
在最简单的 seq2seq 解码器中,我们仅使用编码器的最后输出。这个最后输出有时被称为上下文向量,因为它从整个序列中编码上下文。这个上下文向量被用作解码器的初始隐藏状态。
在解码的每一步,解码器都会得到一个输入标记和隐藏状态。初始输入标记是起始字符串<SOS>标记,第一个隐藏状态是上下文向量(编码器的最后一个隐藏状态)。
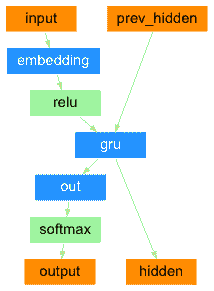
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
return decoder_outputs, decoder_hidden, None # We return `None` for consistency in the training loop
def forward_step(self, input, hidden):
output = self.embedding(input)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output)
return output, hidden
我鼓励您训练并观察这个模型的结果,但为了节省空间,我们将直接引入注意力机制。
注意力解码器
如果只传递上下文向量在编码器和解码器之间,那么这个单一向量将承担编码整个句子的负担。
注意力允许解码器网络在每一步解码器自身输出的不同部分上“聚焦”编码器的输出。首先我们计算一组注意力权重。这些将与编码器输出向量相乘,以创建加权组合。结果(代码中称为attn_applied)应该包含关于输入序列的特定部分的信息,从而帮助解码器选择正确的输出单词。

计算注意力权重是通过另一个前馈层attn完成的,使用解码器的输入和隐藏状态作为输入。由于训练数据中存在各种大小的句子,为了实际创建和训练这一层,我们必须选择一个最大句子长度(输入长度,用于编码器输出)来应用。最大长度的句子将使用所有的注意力权重,而较短的句子将只使用前几个。
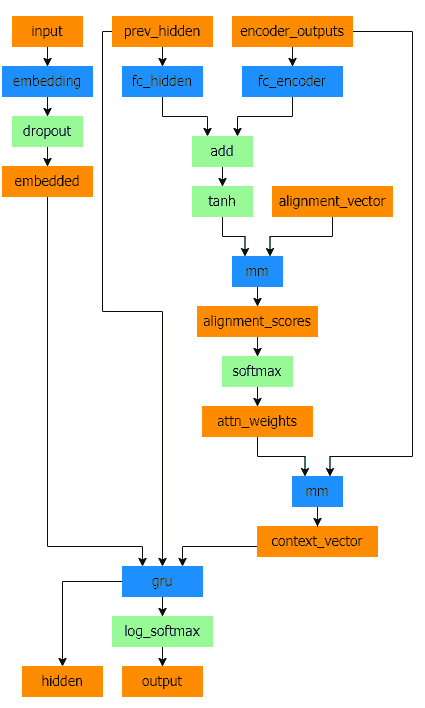
Bahdanau 注意力,也被称为加性注意力,是序列到序列模型中常用的注意力机制,特别是在神经机器翻译任务中。它是由 Bahdanau 等人在他们的论文中引入的,标题为Neural Machine Translation by Jointly Learning to Align and Translate。这种注意力机制利用了一个学习对齐模型来计算编码器和解码器隐藏状态之间的注意力分数。它利用一个前馈神经网络来计算对齐分数。
然而,还有其他可用的注意力机制,比如 Luong 注意力,它通过解码器隐藏状态和编码器隐藏状态之间的点积计算注意力分数。它不涉及 Bahdanau 注意力中使用的非线性变换。
在本教程中,我们将使用 Bahdanau 注意力。然而,探索修改注意力机制以使用 Luong 注意力将是一项有价值的练习。
class BahdanauAttention(nn.Module):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.Wa = nn.Linear(hidden_size, hidden_size)
self.Ua = nn.Linear(hidden_size, hidden_size)
self.Va = nn.Linear(hidden_size, 1)
def forward(self, query, keys):
scores = self.Va(torch.tanh(self.Wa(query) + self.Ua(keys)))
scores = scores.squeeze(2).unsqueeze(1)
weights = F.softmax(scores, dim=-1)
context = torch.bmm(weights, keys)
return context, weights
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1):
super(AttnDecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.attention = BahdanauAttention(hidden_size)
self.gru = nn.GRU(2 * hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout_p)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
attentions = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden, attn_weights = self.forward_step(
decoder_input, decoder_hidden, encoder_outputs
)
decoder_outputs.append(decoder_output)
attentions.append(attn_weights)
if target_tensor is not None:
# Teacher forcing: Feed the target as the next input
decoder_input = target_tensor[:, i].unsqueeze(1) # Teacher forcing
else:
# Without teacher forcing: use its own predictions as the next input
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach() # detach from history as input
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
attentions = torch.cat(attentions, dim=1)
return decoder_outputs, decoder_hidden, attentions
def forward_step(self, input, hidden, encoder_outputs):
embedded = self.dropout(self.embedding(input))
query = hidden.permute(1, 0, 2)
context, attn_weights = self.attention(query, encoder_outputs)
input_gru = torch.cat((embedded, context), dim=2)
output, hidden = self.gru(input_gru, hidden)
output = self.out(output)
return output, hidden, attn_weights
注意
还有其他形式的注意力机制,通过使用相对位置方法来解决长度限制的问题。阅读关于“局部注意力”的内容,详见Effective Approaches to Attention-based Neural Machine Translation。
训练
准备训练数据
为了训练,对于每一对,我们将需要一个输入张量(输入句子中单词的索引)和目标张量(目标句子中单词的索引)。在创建这些向量时,我们将在两个序列中都附加 EOS 标记。
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(1, -1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
def get_dataloader(batch_size):
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
n = len(pairs)
input_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
target_ids = np.zeros((n, MAX_LENGTH), dtype=np.int32)
for idx, (inp, tgt) in enumerate(pairs):
inp_ids = indexesFromSentence(input_lang, inp)
tgt_ids = indexesFromSentence(output_lang, tgt)
inp_ids.append(EOS_token)
tgt_ids.append(EOS_token)
input_ids[idx, :len(inp_ids)] = inp_ids
target_ids[idx, :len(tgt_ids)] = tgt_ids
train_data = TensorDataset(torch.LongTensor(input_ids).to(device),
torch.LongTensor(target_ids).to(device))
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
return input_lang, output_lang, train_dataloader
训练模型
为了训练,我们将输入句子通过编码器,并跟踪每个输出和最新的隐藏状态。然后解码器将得到<SOS>标记作为其第一个输入,编码器的最后隐藏状态作为其第一个隐藏状态。
“教师强制”是使用真实目标输出作为每个下一个输入的概念,而不是使用解码器的猜测作为下一个输入。使用教师强制会导致更快地收敛,但当训练好的网络被利用时,可能会表现出不稳定性。
您可以观察到使用强制教师网络的输出,这些网络具有连贯的语法,但与正确的翻译相去甚远 – 直觉上它已经学会了表示输出语法,并且一旦老师告诉它前几个单词,它就可以“捡起”含义,但它并没有正确地学会如何从一开始的翻译中创建句子。
由于 PyTorch 的自动求导给了我们自由,我们可以随机选择是否使用强制教师,只需使用简单的 if 语句。将teacher_forcing_ratio调高以更多地使用它。
def train_epoch(dataloader, encoder, decoder, encoder_optimizer,
decoder_optimizer, criterion):
total_loss = 0
for data in dataloader:
input_tensor, target_tensor = data
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_outputs, _, _ = decoder(encoder_outputs, encoder_hidden, target_tensor)
loss = criterion(
decoder_outputs.view(-1, decoder_outputs.size(-1)),
target_tensor.view(-1)
)
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
这是一个辅助函数,用于打印经过的时间和给定当前时间和进度百分比的估计剩余时间。
import time
import math
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
整个训练过程如下:
-
启动计时器
-
初始化优化器和标准
-
创建训练对集合
-
为绘图开始空损失数组
然后我们多次调用train,偶尔打印进度(示例的百分比,到目前为止的时间,估计时间)和平均损失。
def train(train_dataloader, encoder, decoder, n_epochs, learning_rate=0.001,
print_every=100, plot_every=100):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
criterion = nn.NLLLoss()
for epoch in range(1, n_epochs + 1):
loss = train_epoch(train_dataloader, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if epoch % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, epoch / n_epochs),
epoch, epoch / n_epochs * 100, print_loss_avg))
if epoch % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
绘制结果
绘图是用 matplotlib 完成的,使用在训练时保存的损失值数组plot_losses。
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as np
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
评估
评估主要与训练相同,但没有目标,因此我们只需将解码器的预测反馈给自身进行每一步。每次预测一个单词时,我们将其添加到输出字符串中,如果预测到 EOS 令牌,则停在那里。我们还存储解码器的注意力输出以供稍后显示。
def evaluate(encoder, decoder, sentence, input_lang, output_lang):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
encoder_outputs, encoder_hidden = encoder(input_tensor)
decoder_outputs, decoder_hidden, decoder_attn = decoder(encoder_outputs, encoder_hidden)
_, topi = decoder_outputs.topk(1)
decoded_ids = topi.squeeze()
decoded_words = []
for idx in decoded_ids:
if idx.item() == EOS_token:
decoded_words.append('<EOS>')
break
decoded_words.append(output_lang.index2word[idx.item()])
return decoded_words, decoder_attn
我们可以从训练集中评估随机句子,并打印出输入、目标和输出,以进行一些主观质量判断:
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words, _ = evaluate(encoder, decoder, pair[0], input_lang, output_lang)
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')
训练和评估
有了所有这些辅助函数(看起来像是额外的工作,但这样做可以更容易地运行多个实验),我们实际上可以初始化一个网络并开始训练。
请记住,输入句子经过了严格过滤。对于这个小数据集,我们可以使用相对较小的 256 个隐藏节点和一个单独的 GRU 层的网络。在 MacBook CPU 上大约 40 分钟后,我们将得到一些合理的结果。
注意
如果您运行此笔记本,您可以训练,中断内核,评估,并稍后继续训练。注释掉初始化编码器和解码器的行,并再次运行trainIters。
hidden_size = 128
batch_size = 32
input_lang, output_lang, train_dataloader = get_dataloader(batch_size)
encoder = EncoderRNN(input_lang.n_words, hidden_size).to(device)
decoder = AttnDecoderRNN(hidden_size, output_lang.n_words).to(device)
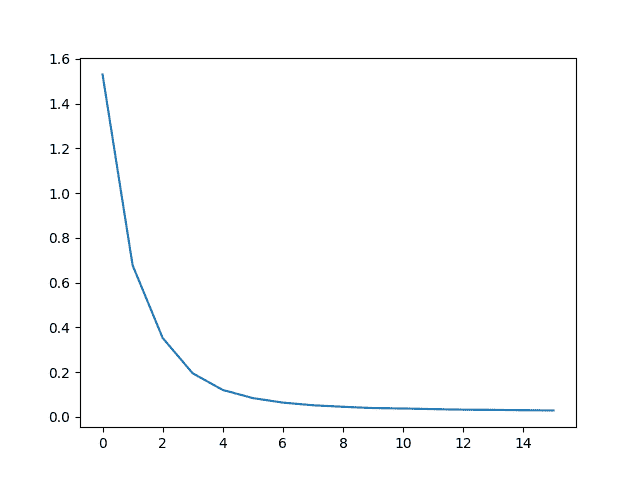
train(train_dataloader, encoder, decoder, 80, print_every=5, plot_every=5)

Reading lines...
Read 135842 sentence pairs
Trimmed to 11445 sentence pairs
Counting words...
Counted words:
fra 4601
eng 2991
0m 27s (- 6m 53s) (5 6%) 1.5304
0m 54s (- 6m 21s) (10 12%) 0.6776
1m 21s (- 5m 52s) (15 18%) 0.3528
1m 48s (- 5m 25s) (20 25%) 0.1946
2m 15s (- 4m 57s) (25 31%) 0.1205
2m 42s (- 4m 30s) (30 37%) 0.0841
3m 9s (- 4m 3s) (35 43%) 0.0639
3m 36s (- 3m 36s) (40 50%) 0.0521
4m 2s (- 3m 8s) (45 56%) 0.0452
4m 29s (- 2m 41s) (50 62%) 0.0395
4m 56s (- 2m 14s) (55 68%) 0.0377
5m 23s (- 1m 47s) (60 75%) 0.0349
5m 50s (- 1m 20s) (65 81%) 0.0324
6m 17s (- 0m 53s) (70 87%) 0.0316
6m 44s (- 0m 26s) (75 93%) 0.0298
7m 11s (- 0m 0s) (80 100%) 0.0291
将 dropout 层设置为eval模式
encoder.eval()
decoder.eval()
evaluateRandomly(encoder, decoder)
> il est si mignon !
= he s so cute
< he s so cute <EOS>
> je vais me baigner
= i m going to take a bath
< i m going to take a bath <EOS>
> c est un travailleur du batiment
= he s a construction worker
< he s a construction worker <EOS>
> je suis representant de commerce pour notre societe
= i m a salesman for our company
< i m a salesman for our company <EOS>
> vous etes grande
= you re big
< you are big <EOS>
> tu n es pas normale
= you re not normal
< you re not normal <EOS>
> je n en ai pas encore fini avec vous
= i m not done with you yet
< i m not done with you yet <EOS>
> je suis desole pour ce malentendu
= i m sorry about my mistake
< i m sorry about my mistake <EOS>
> nous ne sommes pas impressionnes
= we re not impressed
< we re not impressed <EOS>
> tu as la confiance de tous
= you are trusted by every one of us
< you are trusted by every one of us <EOS>
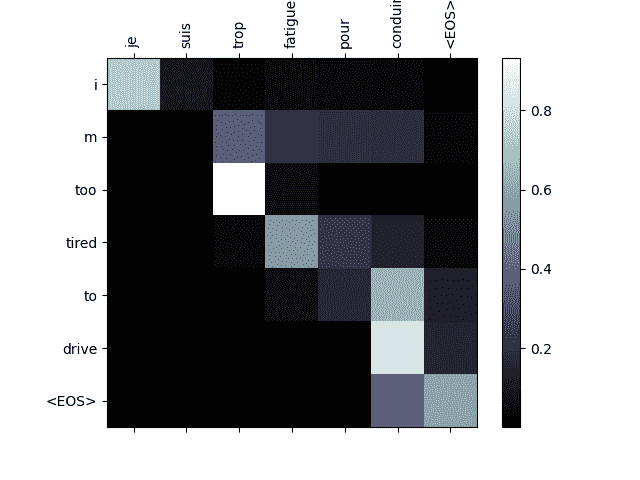
可视化注意力
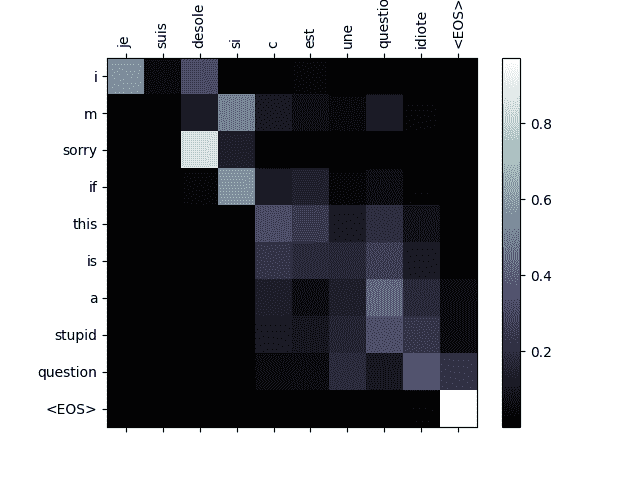
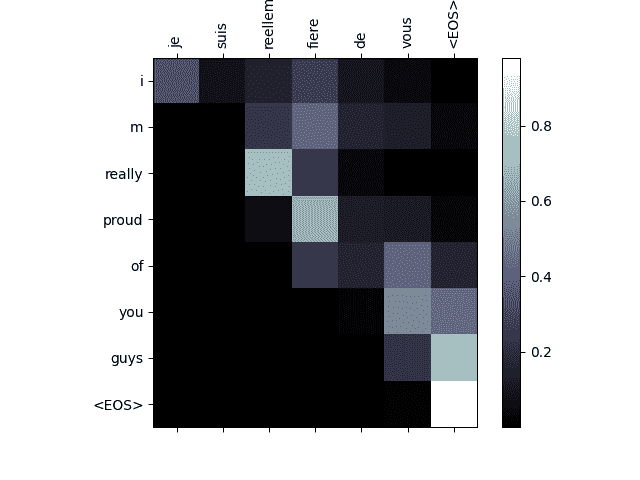
注意机制的一个有用特性是其高度可解释的输出。因为它用于加权输入序列的特定编码器输出,我们可以想象在每个时间步骤网络关注的地方。
你可以简单地运行plt.matshow(attentions)来查看注意力输出显示为矩阵。为了获得更好的查看体验,我们将额外添加坐标轴和标签:
def showAttention(input_sentence, output_words, attentions):
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.cpu().numpy(), cmap='bone')
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + input_sentence.split(' ') +
['<EOS>'], rotation=90)
ax.set_yticklabels([''] + output_words)
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def evaluateAndShowAttention(input_sentence):
output_words, attentions = evaluate(encoder, decoder, input_sentence, input_lang, output_lang)
print('input =', input_sentence)
print('output =', ' '.join(output_words))
showAttention(input_sentence, output_words, attentions[0, :len(output_words), :])
evaluateAndShowAttention('il n est pas aussi grand que son pere')
evaluateAndShowAttention('je suis trop fatigue pour conduire')
evaluateAndShowAttention('je suis desole si c est une question idiote')
evaluateAndShowAttention('je suis reellement fiere de vous')
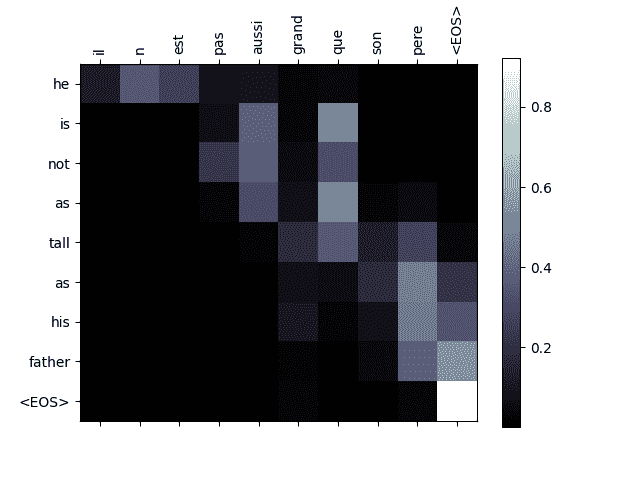
input = il n est pas aussi grand que son pere
output = he is not as tall as his father <EOS>
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:823: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:825: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
input = je suis trop fatigue pour conduire
output = i m too tired to drive <EOS>
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:823: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:825: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
input = je suis desole si c est une question idiote
output = i m sorry if this is a stupid question <EOS>
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:823: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:825: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
input = je suis reellement fiere de vous
output = i m really proud of you guys <EOS>
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:823: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
/var/lib/jenkins/workspace/intermediate_source/seq2seq_translation_tutorial.py:825: UserWarning:
set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
练习
-
尝试不同的数据集
-
另一种语言对
-
人类 → 机器(例如 IOT 命令)
-
聊天 → 回复
-
问题 → 答案
-
-
用预训练的词嵌入(如
word2vec或GloVe)替换嵌入 -
尝试使用更多层,更多隐藏单元和更多句子。比较训练时间和结果。
-
如果您使用的翻译文件中有两个相同短语的配对(
I am test t I am test),您可以将其用作自动编码器。尝试这样做:-
作为自动编码器进行训练
-
仅保存编码器网络
-
为翻译训练一个新的解码器
-
脚本的总运行时间:(7 分钟 20.607 秒)
下载 Python 源代码:seq2seq_translation_tutorial.py
下载 Jupyter 笔记本:seq2seq_translation_tutorial.ipynb
原文地址:https://blog.csdn.net/wizardforcel/article/details/136030909
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_67365.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!

![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)


