本文介绍: Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)大数据起源于 Google 2003年发布的三篇论文 GoogleFS、MapReduce、BigTable 史称三驾马车,可惜 Google 在发布论文后并没有公布其源码,但是 Apache 开源社区蓬勃发展,先后出现了 Hadoop,Spark,Apache Flink 等产品,而 Google 内部则使用着闭源的 BigTable、Spanner、Millwheel。
参考资料:
Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)
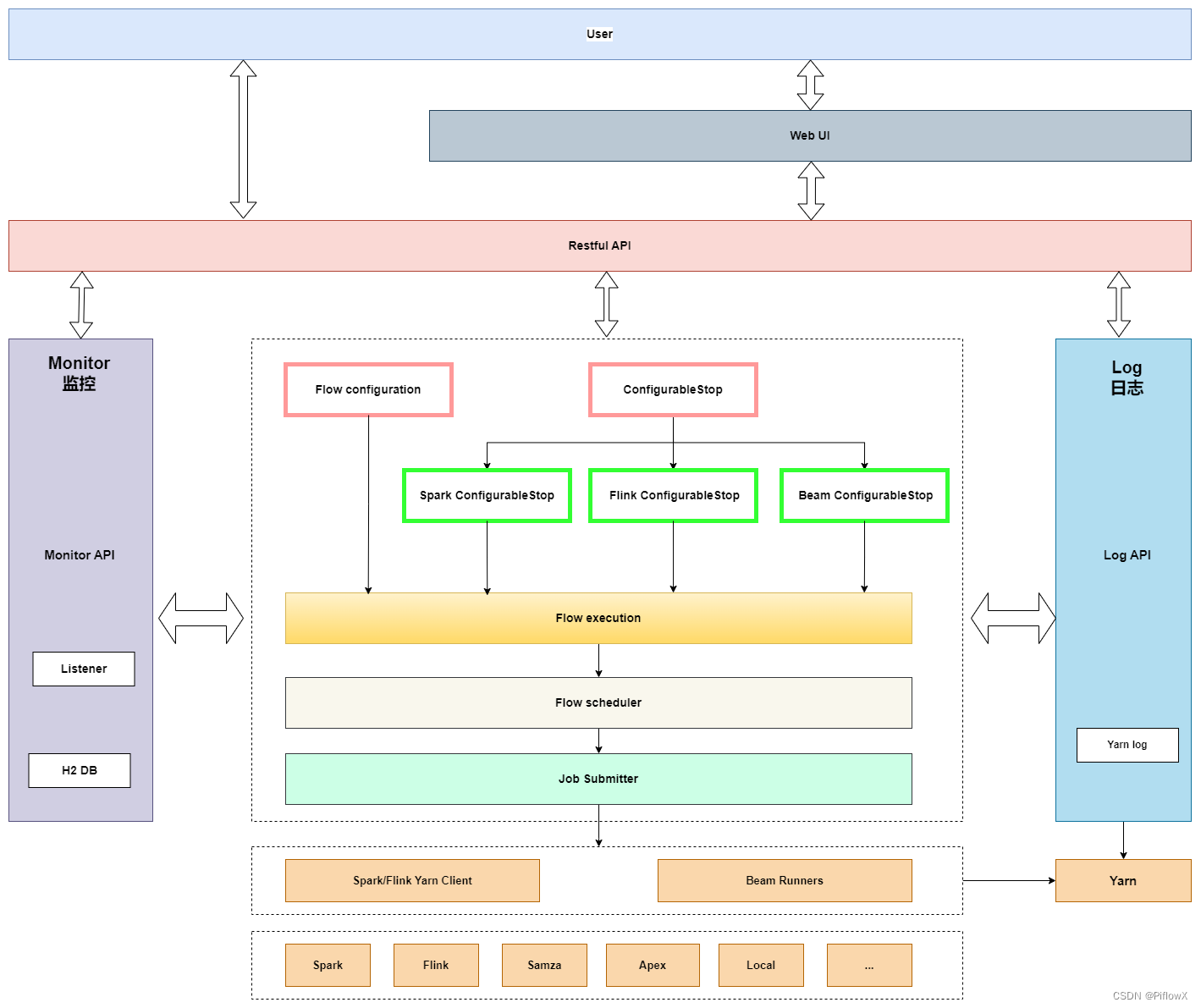
在之前的文章中有介绍过,PiflowX是支持spark和flink计算引擎,其架构图如下所示:
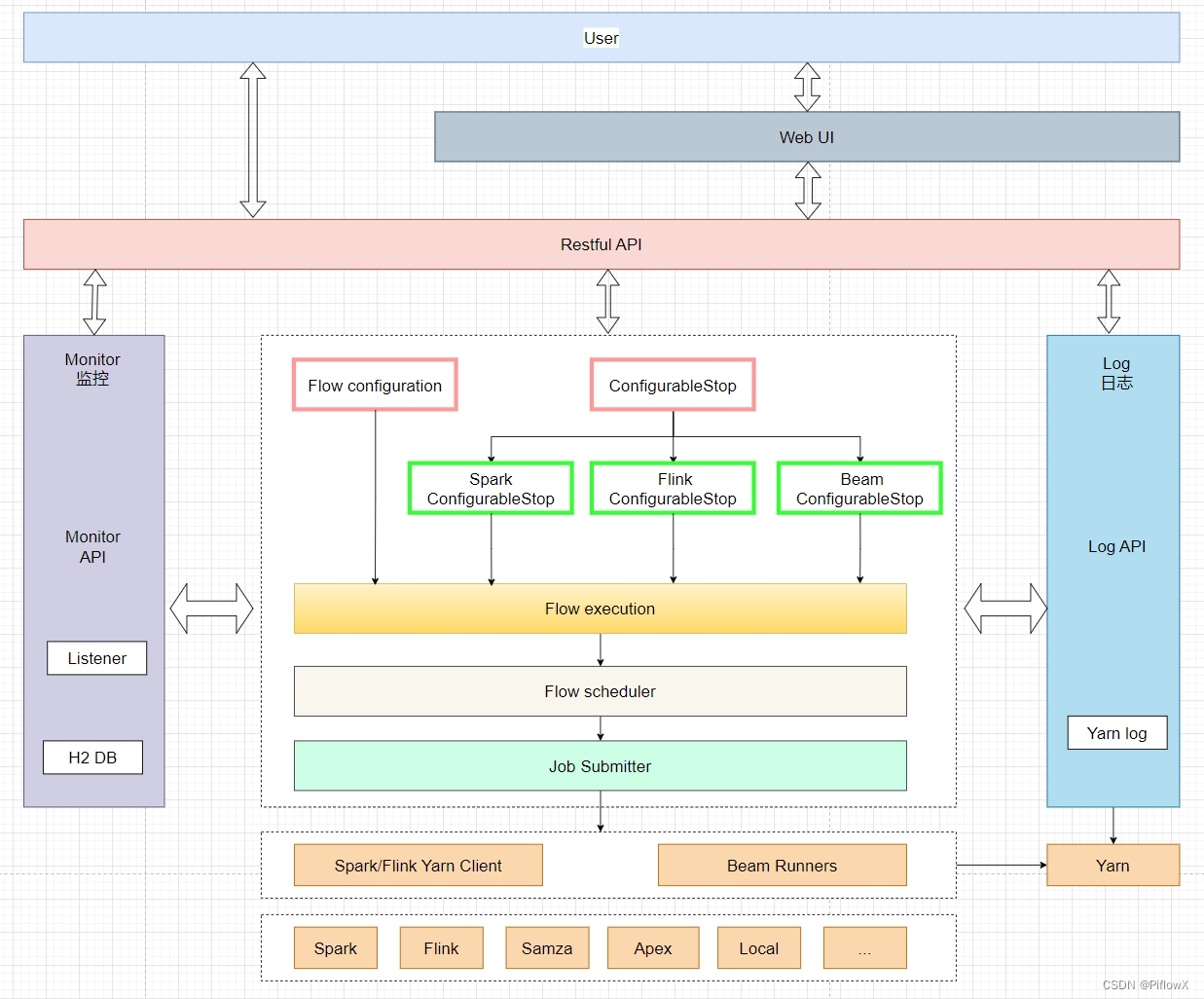
在piflow高度抽象的流水线组件的支持下,我们可以很轻松的扩展计算引擎的支持,比如spark和flink,当然还可以是apache beam。
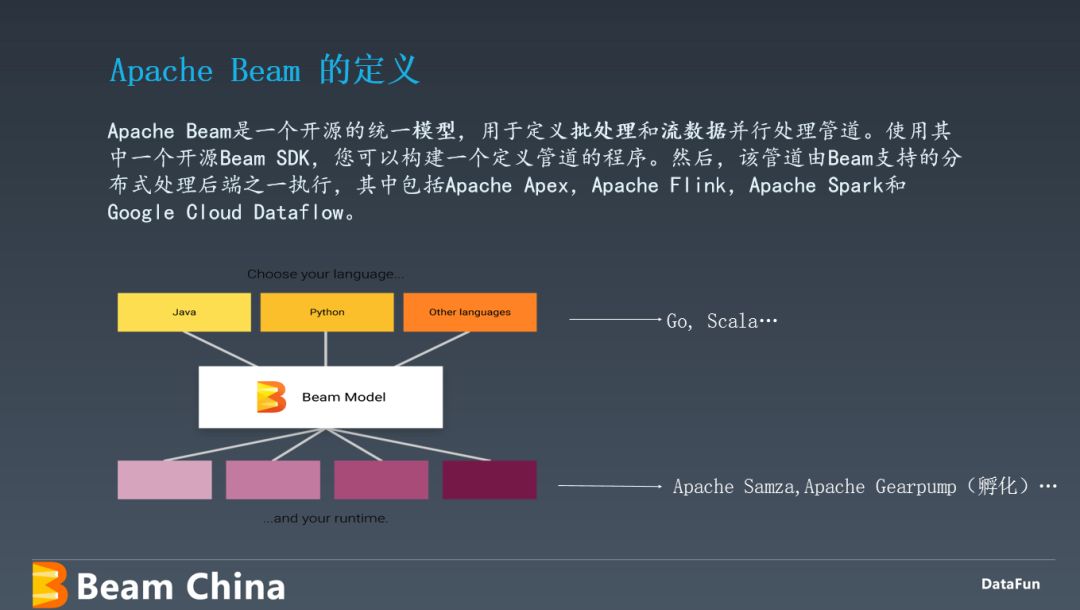
什么是Apache Beam
Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)




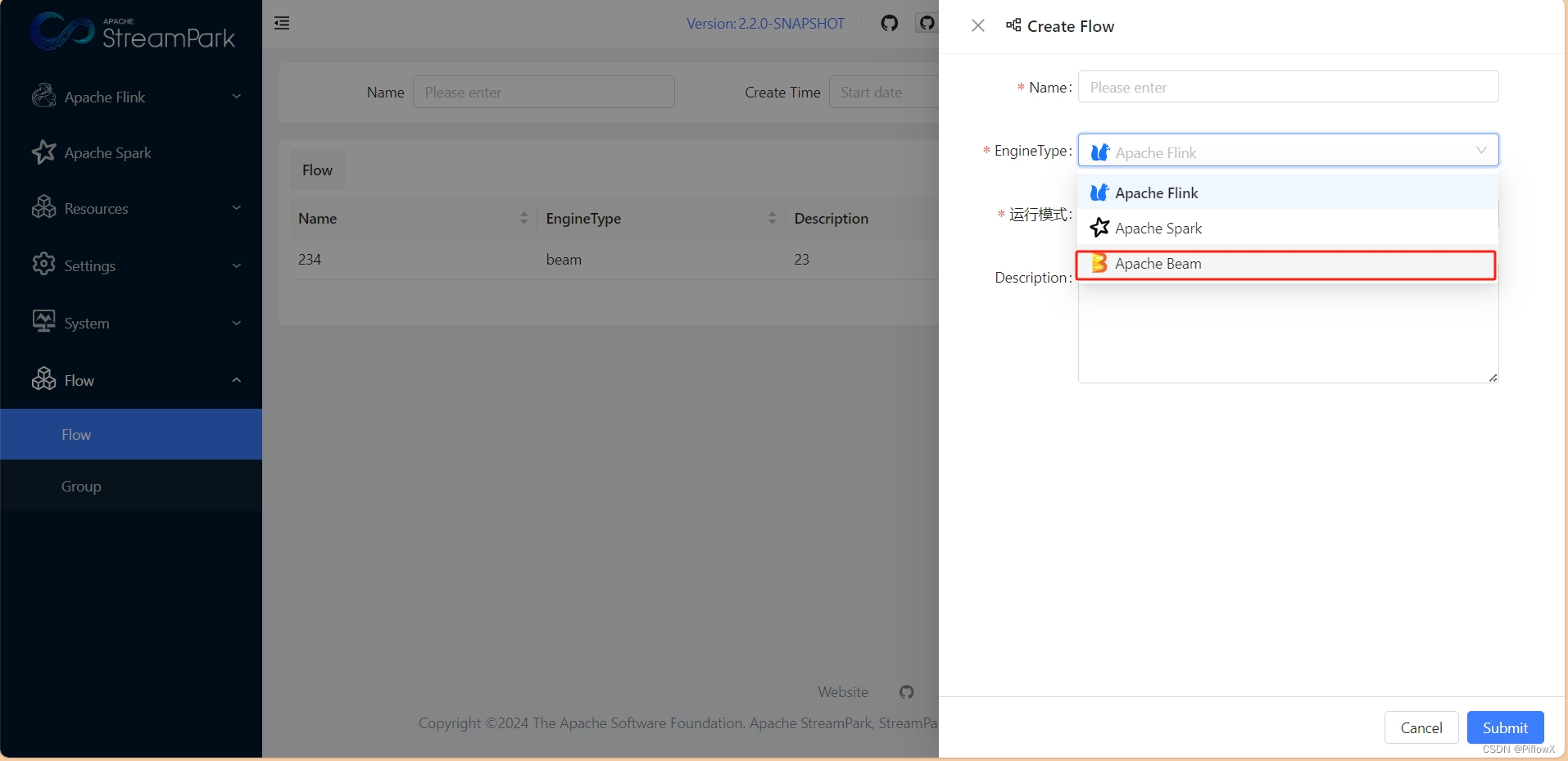
PiflowX新架构
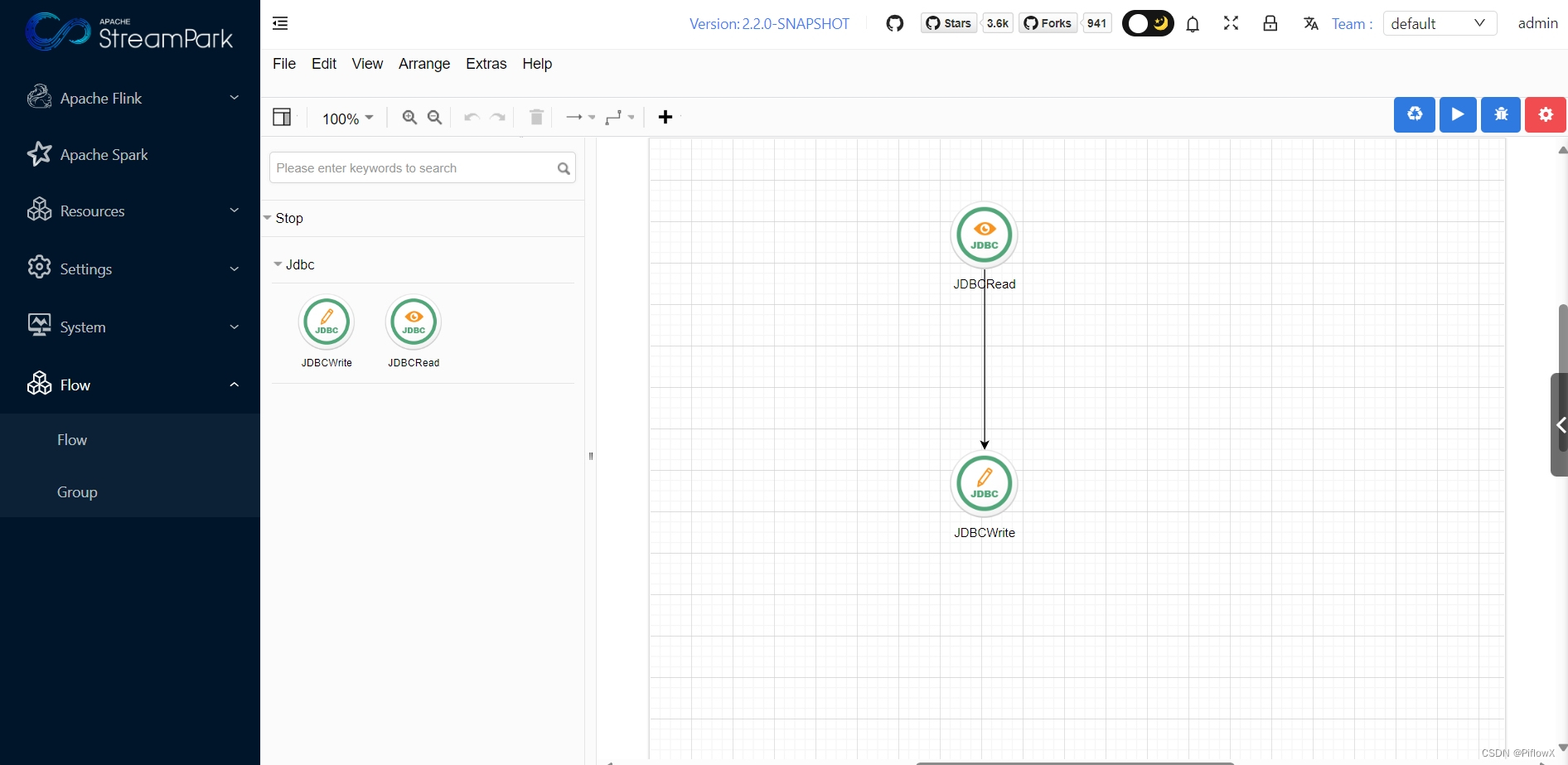
Beam引擎执行演示
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。