本文介绍: 「吴恩达」深度学习笔记 – 长短时记忆网络LSTM
一、经典模型
widetilde{c}^{<t>} = tanh(w_{c}[a^{<t-1>},x^{<t>}]+b_{c})
c^{<t>} = Gamma_{u}*widetilde{c}^{<t>} + Gamma_{f}*widetilde{c}^{<t-1>}
a^{<t>} = Gamma_{o} * tanh(c^{<t>})

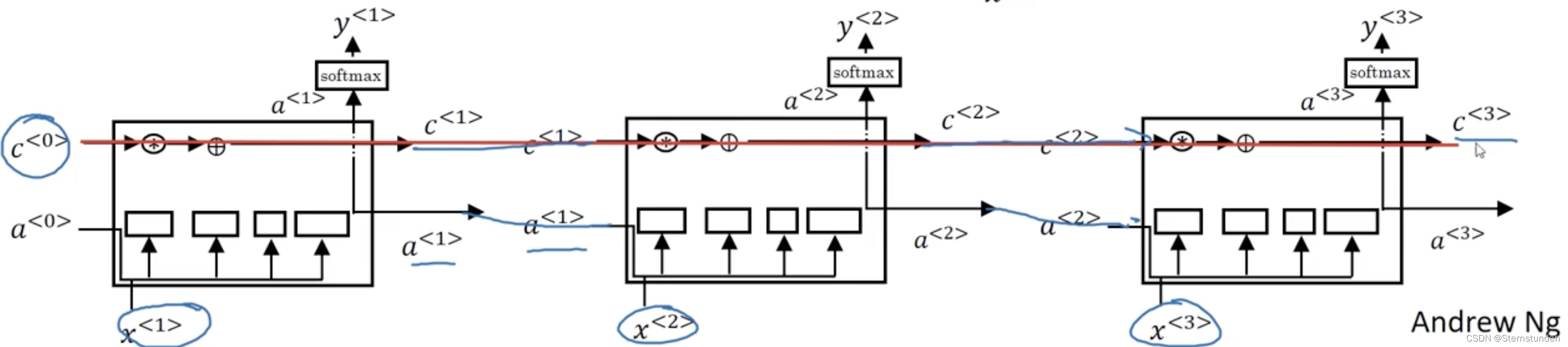
二、窥视孔连接
c^{<t-1>} 也能影响门的值:
三、vs GRU
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)