并非所有人都熟知如何与 LLM 进行高效交流。
一种方案是,人向模型对齐。 于是有了 「Prompt工程师」这一岗位,专门撰写适配 LLM 的 Prompt,从而让模型能够更好地生成内容。
而另一种更为有效的方案则是,让模型向人对齐。 这也是大模型研究中非常重要的问题,无论是 GPT 还是 Claude,在对齐技术上花费大量的时间与精力。但,随着模型规模变大,基于训练的对齐技术也需要耗费更大量的资源。
因此,我们提出另外的一种方案,即黑盒提示对齐优化技术(Black–box Prompt Optimization),通过优化用户指令,从输入角度对模型进行对齐。
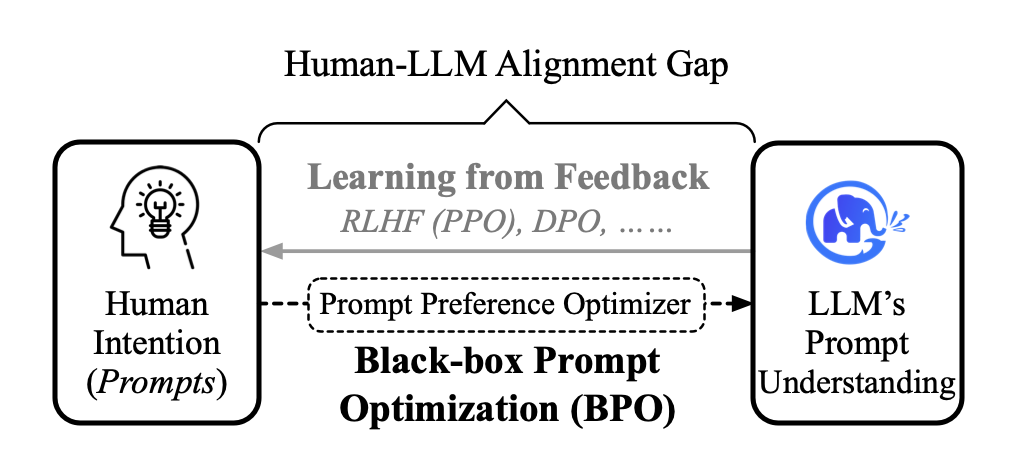
这种方法可以在不对 LLM 进行训练的情况下,大幅提升与人类偏好的对齐程度。
而且 BPO 可以被替换到各种模型上,包括开源模型和基于API的模型。
下面是我们做的一个简单评估:
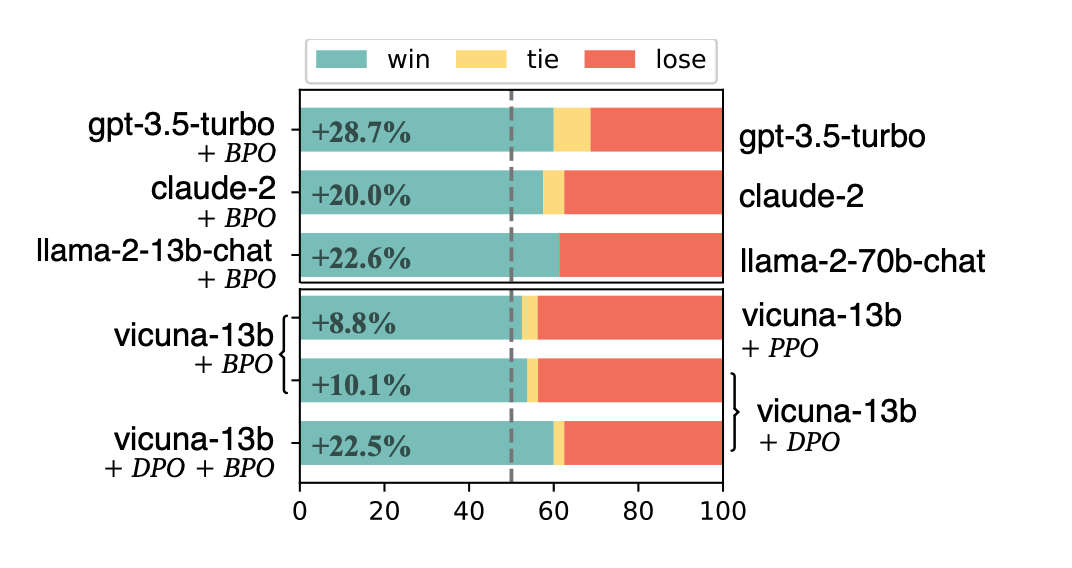
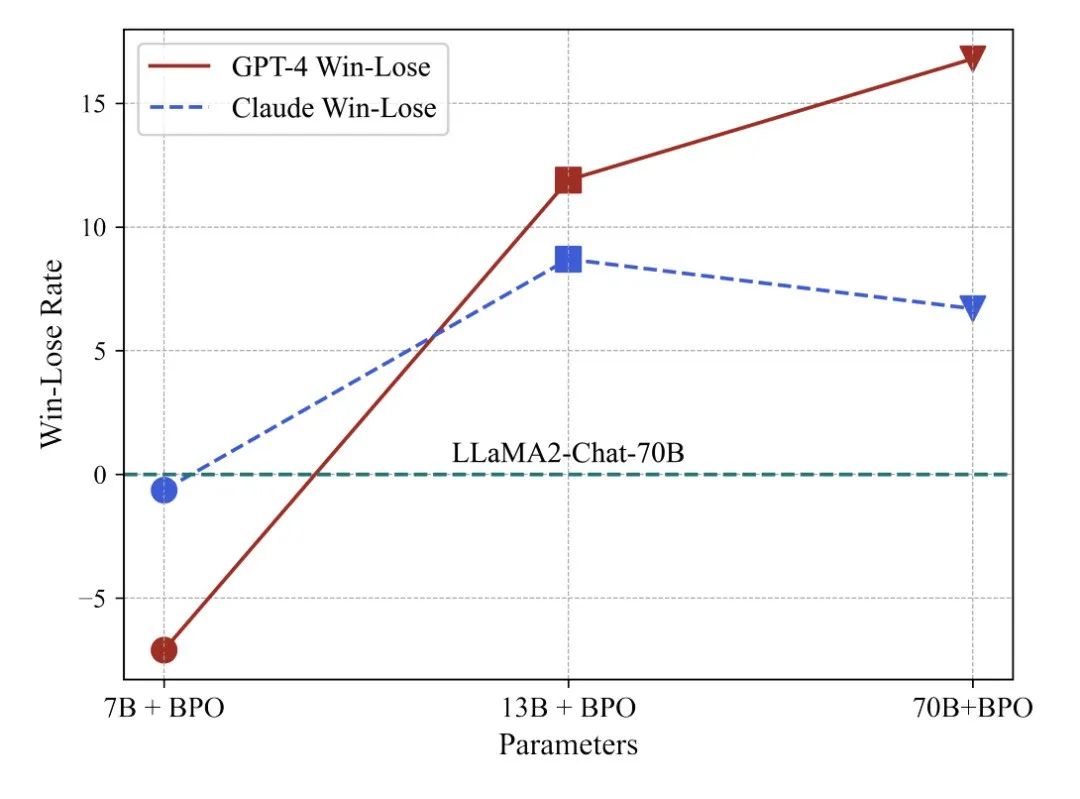
在 VicunaEval 上使用 GPT-4 进行自动评估,BPO 能够大幅提升 ChatGPT、Claude 等模型的人类偏好,并助力 llama2-13b 模型大幅超过 llama2-70b 的版本。
_论文:https://arxiv.org/abs/2311.04155
_
代码:https://github.com/thu-coai/BPO
技术交流群
建了技术答疑、交流群!想要进交流群、资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~

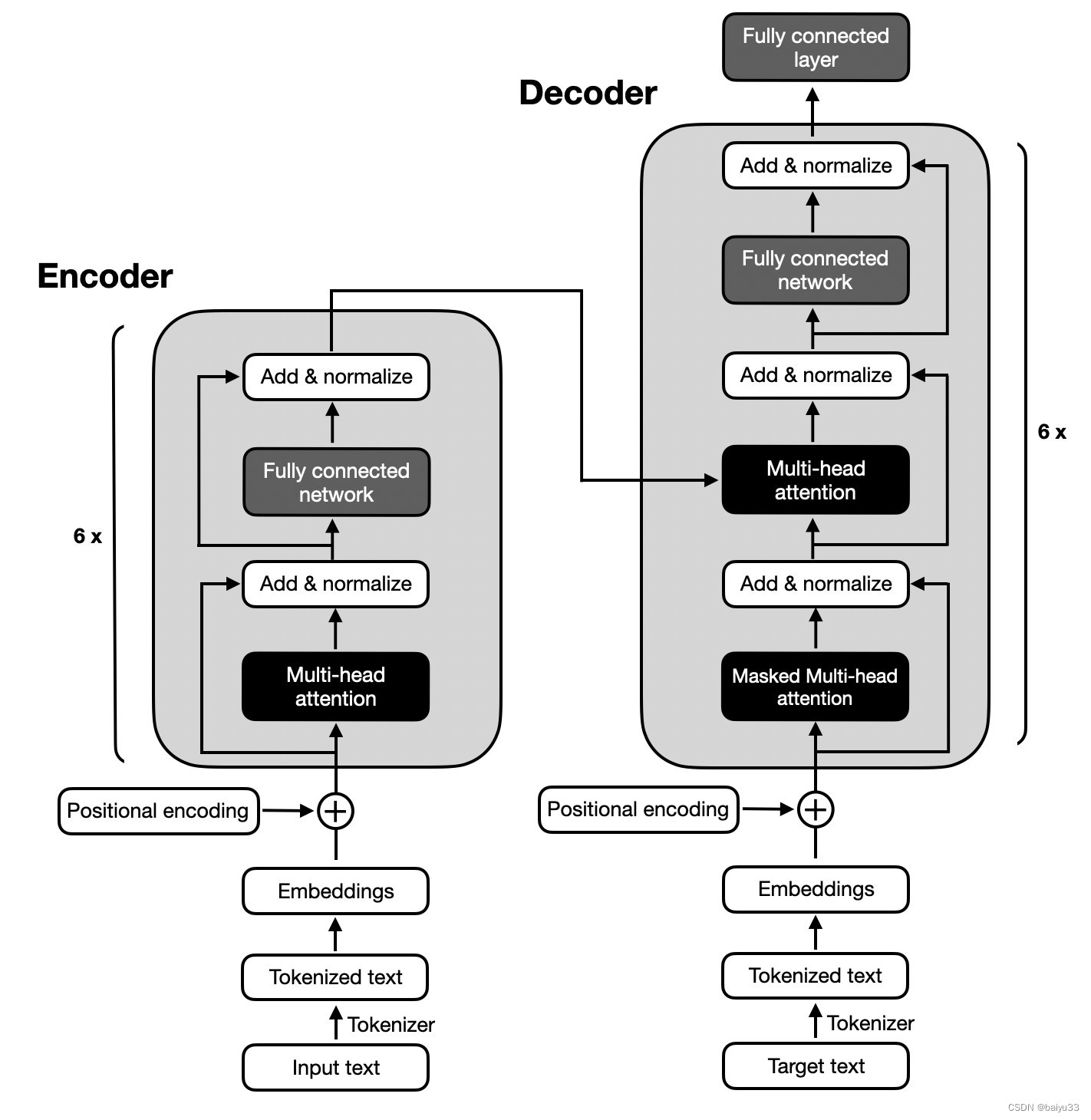
一、方 法
BPO黑盒优化的目标是让模型更好地理解和满足人类的喜好。我们通过调整输入内容,使模型生成的输出更符合用户的期望。这个过程可以分为三个主要步骤:
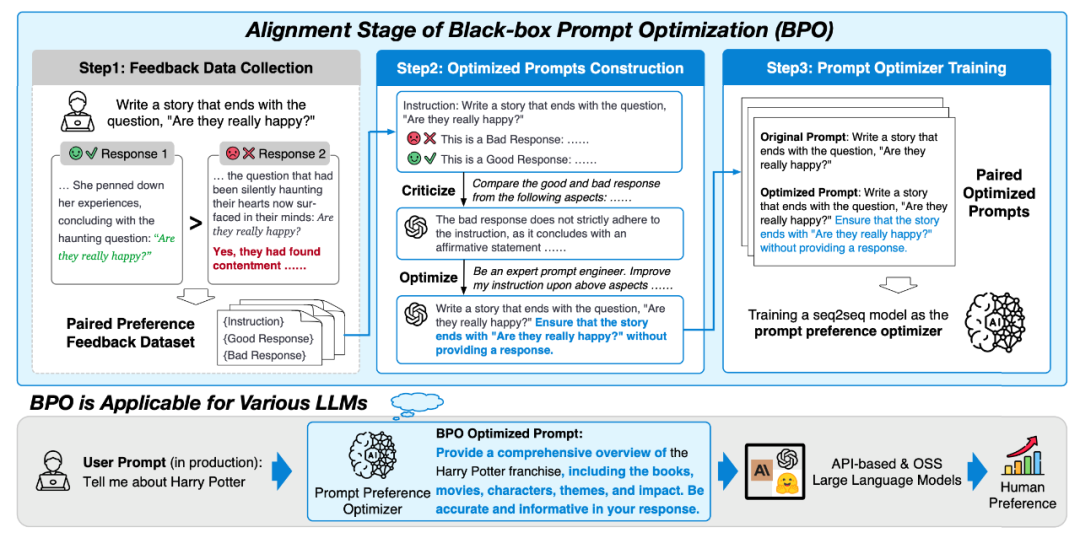
**1、反馈数据收集:**为了建模人类偏好,我们首先搜集了一系列带有反馈信号的开源指令微调数据集,并对这些数据经过精心筛选和过滤。
**2、构造提示优化对:**我们使用这些反馈数据来引导大型模型识别出用户偏好的特征。我们首先让模型分析用户喜欢的回复和不喜欢的回复,找出其中蕴含的人类偏好特征。接着,基于这些特征,我们再利用模型优化原始的用户输入,以期得到更符合用户喜好的模型输出。
**3、训练提示优化器:**经过步骤一和步骤二,我们得到了大量隐含人类偏好的提示对。利用这些提示对,我们训练一个相对较小的模型,从而构建提示偏好优化器。
最终,我们可以利用该提示优化器对用户指令进行优化,并应用在广泛的LLM上。
二、效 果
我们基于英文部分开源反馈数据集和 llama2-chat-7b 构建了 BPO 优化模型。
BPO对齐技术对 GPT-3.5-turbo 有22%的提升,对 GPT-4 有 10% 的提升。

BPO 能够助力 llama2-13b 大幅超过 llama2-70b 版本的模型效果,并让 llama2-7b 版本的模型逼近比它大 10 倍的模型。
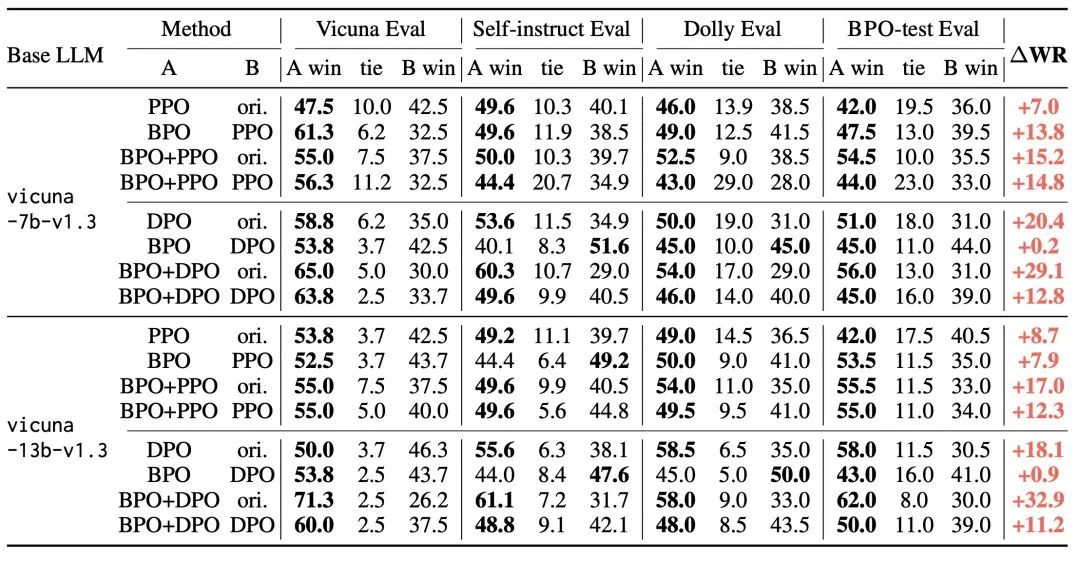
在 vicuna-7b 和 vicuna-13b 上,使用 BPO 对齐的模型超过了常用的反馈学习方法—— PPO(Proximal Policy Optimization) 和 DPO(Direct Preference Optimization)的效果,并且能够和这些方法相结合进一步提升模型效果。
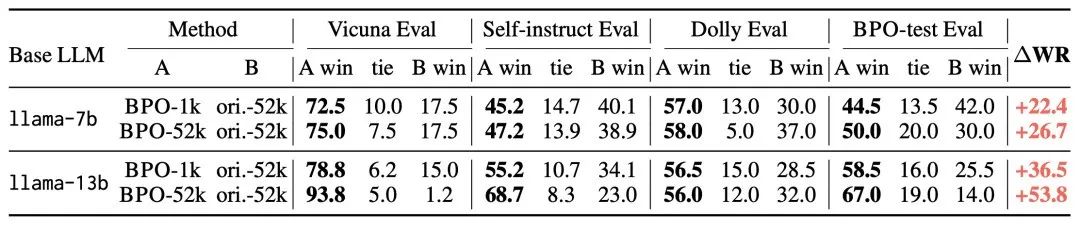
此外,BPO还可以用于提升SFT数据的质量,帮助构建更高质量的SFT模型。
三、研究者说
问:BPO 和反馈学习方法(PPO、DPO)以及 Prompt Engineering方法(如OPRO)的区别是什么?
答:与PPO和DPO相比,BPO最大的优势在于不需要训练原本的LLM,只需要额外训练一个较小的模型即可,并且我们的实验证明这两种技术是可以相结合的。
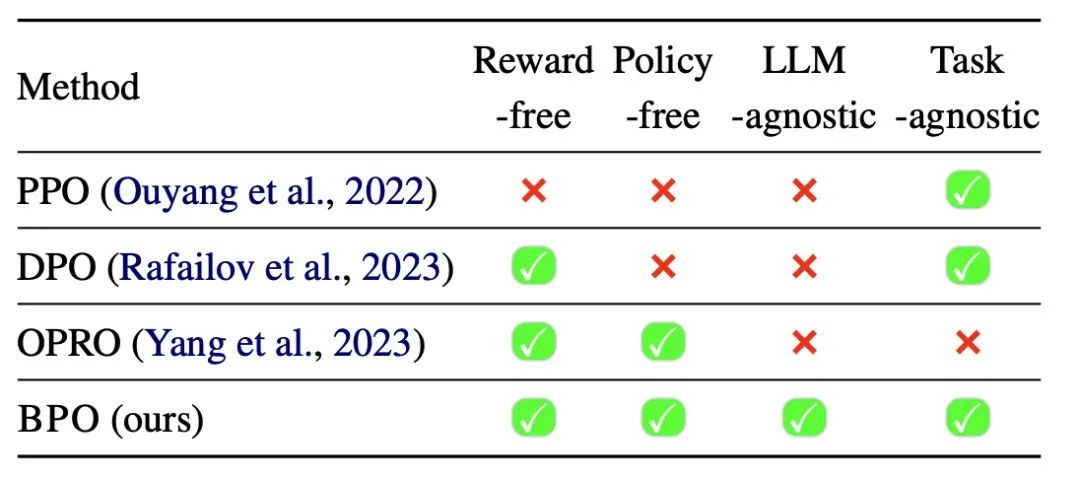
与 OPRO 对比,BPO 最大的特点在于更加通用,OPRO 等现有的 Prompt Engineering 技术大多需要针对特定的数据进行搜索,并且会搜索得到一个针对特定任务的提示。因此,如果用户希望使用此类方法,需要针对每种任务准备相应的数据集。而 BPO 在训练得到提示优化器后,可以优化各种用户指令。
答:我们在 VicunaEval 数据上验证了迭代优化指令的效果,大约在第四轮时,优化后的指令对 ChatGPT 效果最好。
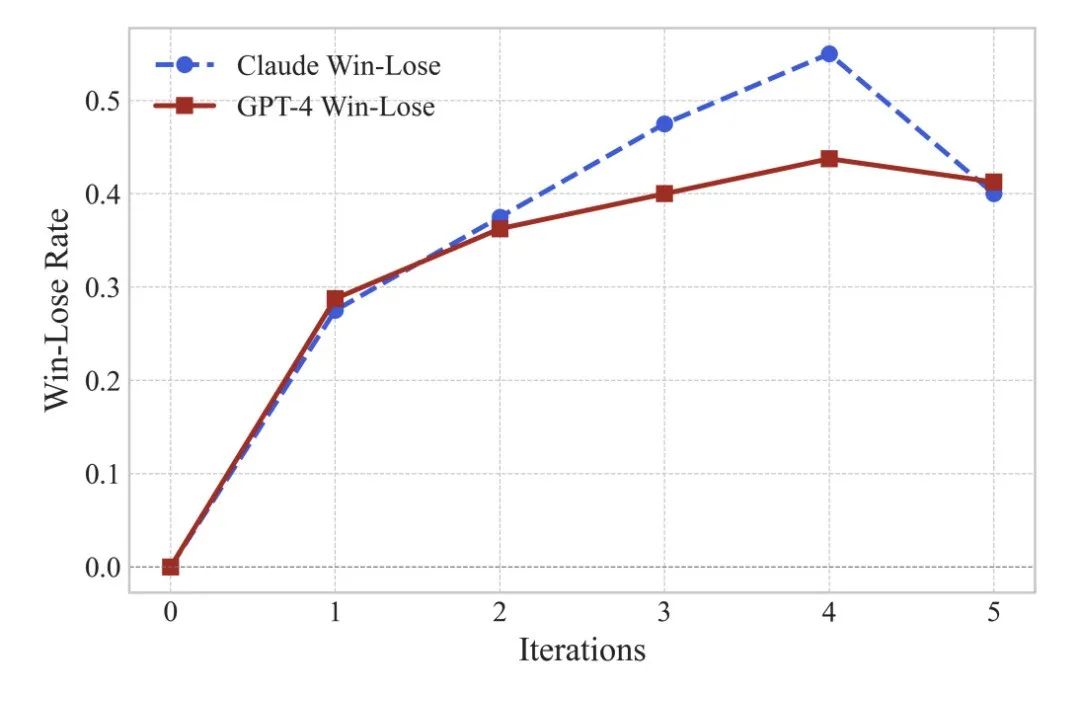
问:BPO 究竟对用户指令做了怎样的优化?
答:我们在论文的第五小节总结了BPO的一些常见优化策略,包括:推理解释、完善用户问题、要点提示以及安全增强。




原文地址:https://blog.csdn.net/m0_59596990/article/details/134543236
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6749.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!