本文介绍: 文章迁移,待整理。
文章迁移,待整理
2. 状态和Checkpoint调优
2.1 大状态调优
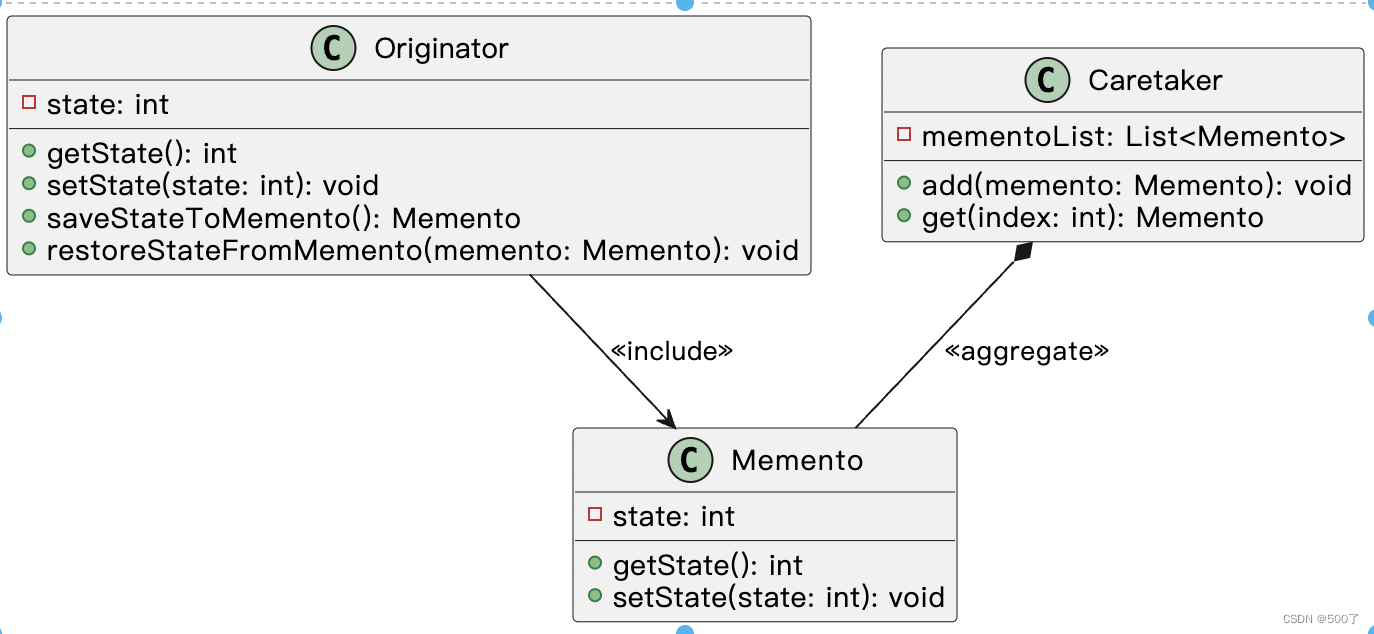
我们生产大多数会使用 fsState ,memState程序挂了状态就丢了,应该没人会在生产使用,但是涉及到一些大状态,fsState效率很低,这时候会选择 rocksDbState
1. RocksDb 为什么效率高
基于 LSM Tree 实现,类似 Hbase 的读写方式,
写数据内存即返回,查数据先查 blockCache,
2. 开启 state 性能访问监控
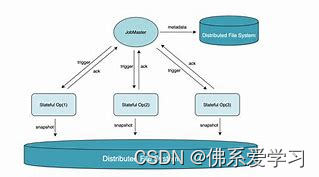
2.2 checkpoint 间隔时长设置
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。