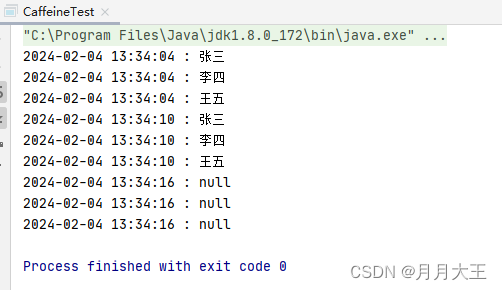
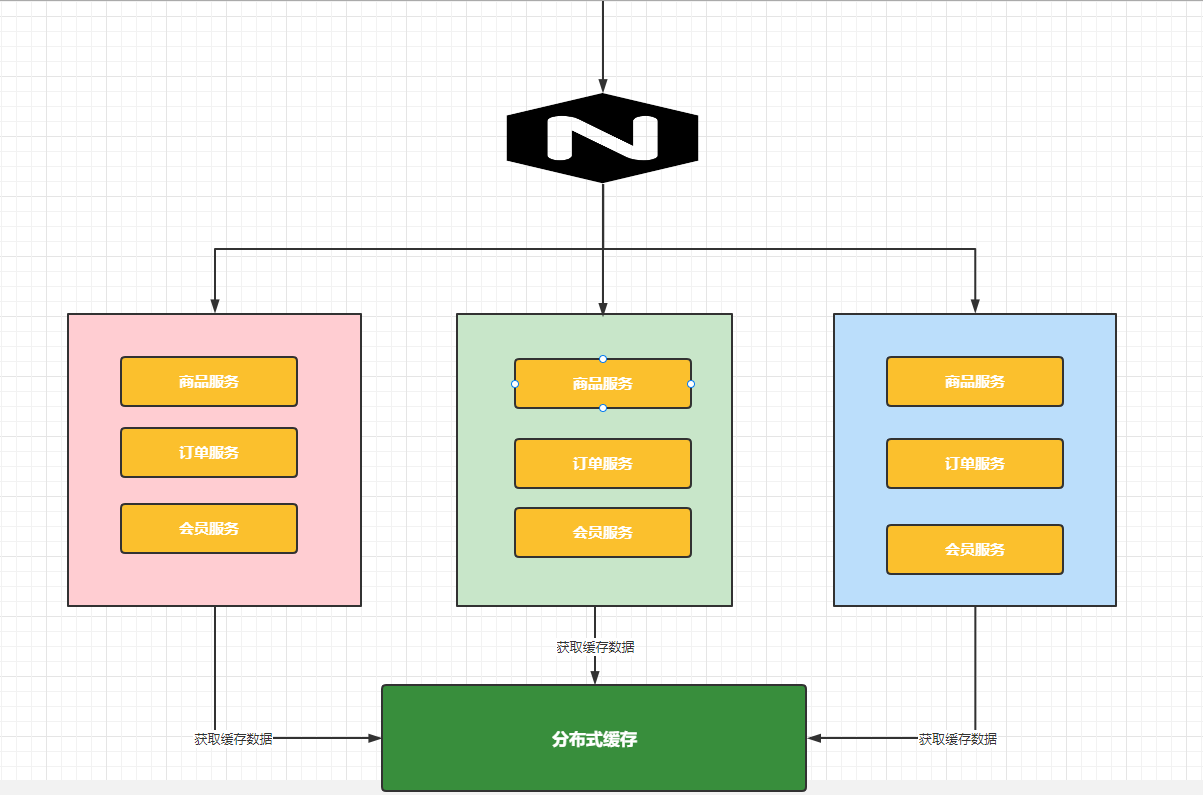
概念
缓存的作用是减低对数据源的访问频率。从而提高我们系统的性能。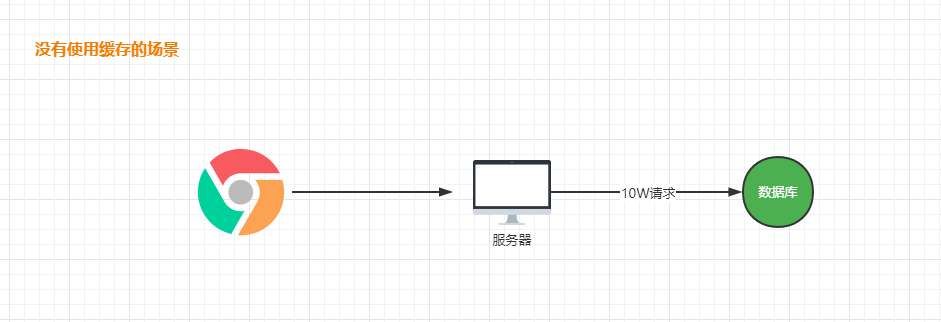

缓存的流程图
缓存分类
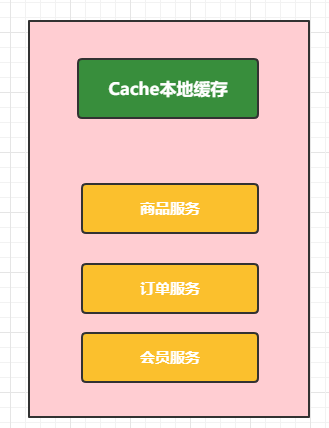
本地缓存
把缓存数据存储在内存中(Map <String,Object>),其实就是强引用,不会轻易被删除。
分布式缓存
数据冗余,效率不高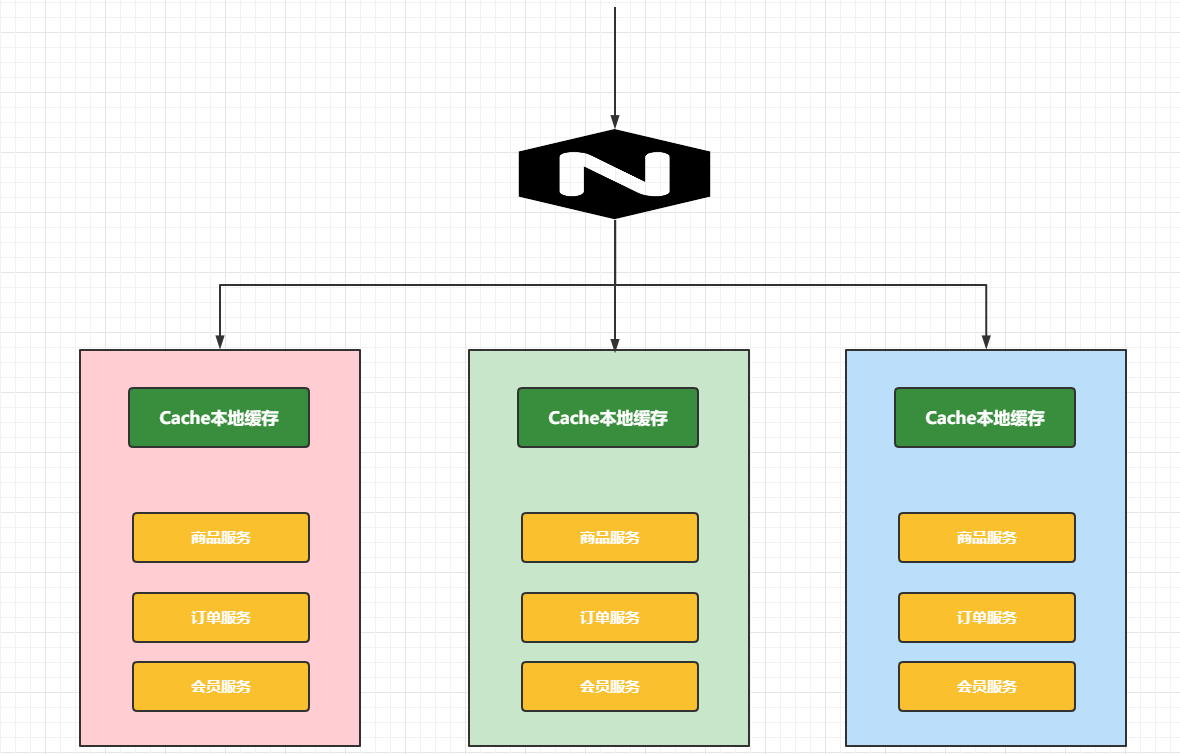
整合Redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.3.2.RELEASE</version>
</dependency>
spring:
redis:
host: 192.168.56.10
port: 6379
@ResponseBody
@RequestMapping("/index/test")
public Object test(){
BoundValueOperations<String, String> boundValueOperations= stringRedisTemplate.boundValueOps("test");
boundValueOperations.set("测试数据");
return boundValueOperations.get();
}
redis缓存改造三级分类
public Map<String, List<Catalog2VO>> getCatelog2JSON() throws IOException {
String catalogJSON = stringRedisTemplate.opsForValue().get("Catelog2JSON");
if (StringUtils.isEmpty(catalogJSON)) {
Map<String, List<Catalog2VO>> map = getCatelog2JSONDb();
String json = objectMapper.writeValueAsString(map);
stringRedisTemplate.opsForValue().set("Catelog2JSON", json);
return map;
}
Map<String, List<Catalog2VO>> map=objectMapper.readValue(catalogJSON, new TypeReference<Map<String, List<Catalog2VO>>>(){});
return map;
}
缓存常见问题
缓存穿透
问题:
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,造成数据库压力增大。
**解决:**直接把null结果缓存,并加入短暂的过期时间
缓存雪崩
**问题:**在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。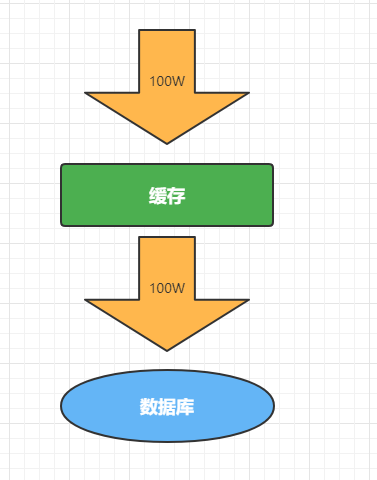
**解决:**原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
**问题:**对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db。
**解决:**加锁,大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db。
synchronized (this) {
。。。。。。
}
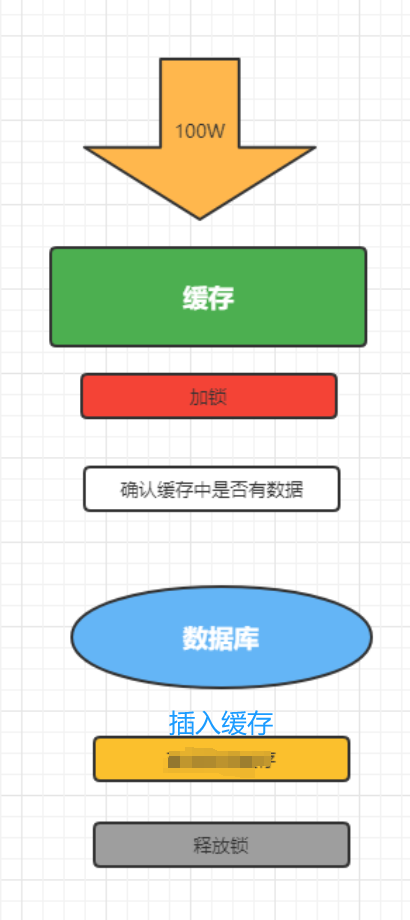
public Map<String, List<Catalog2VO>> getCatelog2JSON() throws IOException {
String catalogJSON = stringRedisTemplate.opsForValue().get("Catelog2JSON");
if (StringUtils.isEmpty(catalogJSON)) {
synchronized (this) {
System.out.println("查数据库啊-----");
Map<String, List<Catalog2VO>> map = getCatelog2JSONDb();
if (null == map) {
//加个null缓存,防止穿透
stringRedisTemplate.opsForValue().set("Catelog2JSON", "null", 5, TimeUnit.SECONDS);
} else {
String json = objectMapper.writeValueAsString(map);
//加个过期时间防止雪崩
stringRedisTemplate.opsForValue().set("Catelog2JSON", json, 5, TimeUnit.SECONDS);
return map;
}
}
}
Map<String, List<Catalog2VO>> map = objectMapper.readValue(catalogJSON, new TypeReference<Map<String, List<Catalog2VO>>>() {
});
return map;
}
本地锁的局限
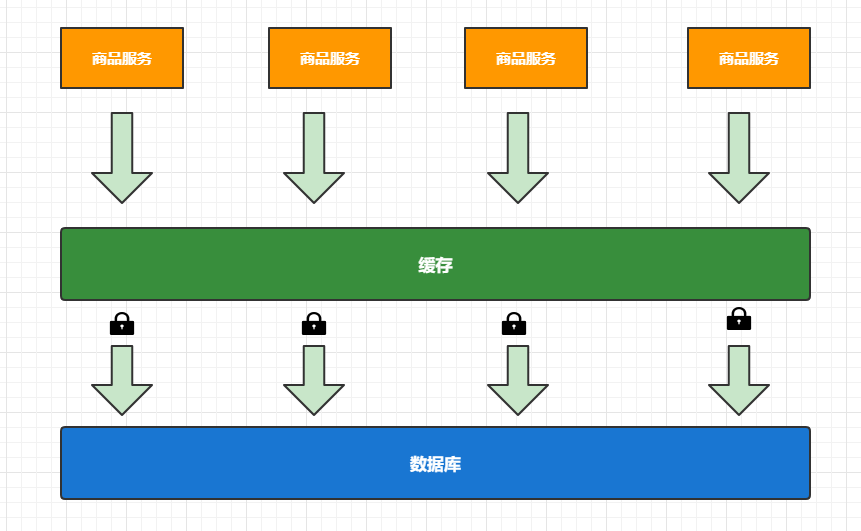

**问题:**针对本地锁的问题,我们需要通过分布式锁来解决,那么是不是意味着本身锁在分布式场景下就不需要了呢?
**答:**因为如果分布式环境下的每个节点不控制请求的数量,那么分布式锁的压力会非常大,这时我们需要本地锁来控制每个节点的同步,来降低分布式锁的压力,所以实际开发中我们都是本地锁和分布式锁结合使用的。
分布式锁
分布式锁原理
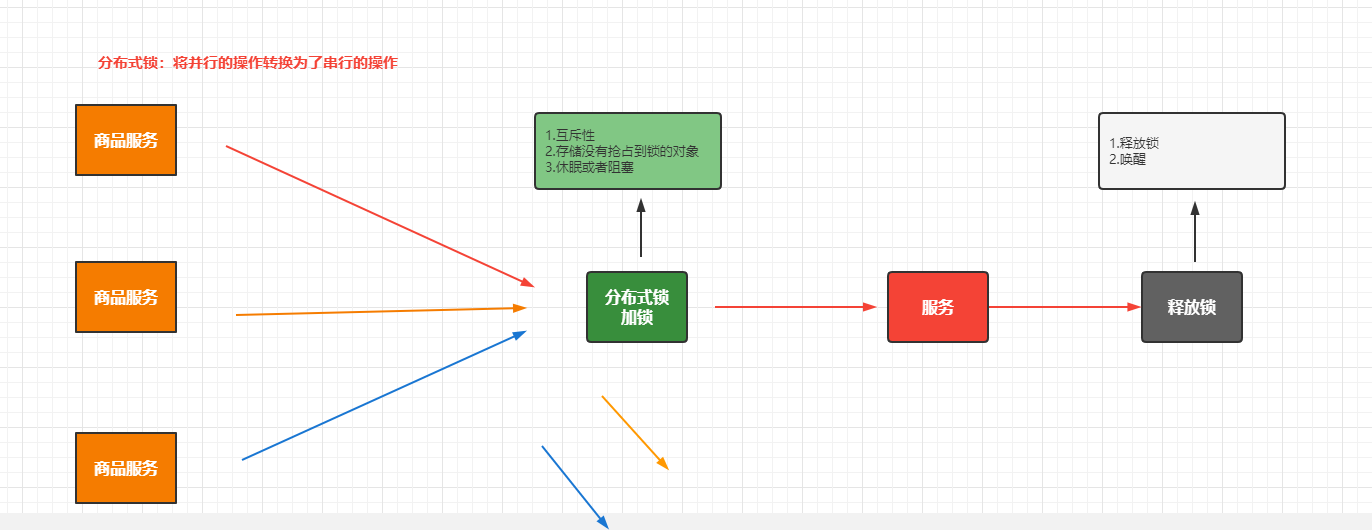
分布式锁常用解决方案
https://blog.csdn.net/qq_33594592/article/details/133932876
数据库
通过在数据库中创建一个唯一索引的表,然后通过插入一条数据来获取锁,如果插入成功则获取锁成功,否则获取锁失败。释放锁的操作就是删除这条数据。这种方式的优点是实现简单,缺点是性能较低,因为涉及到数据库的操作。
可以利用MySQL隔离性:唯一索引
use test;
CREATE TABLE `DistributedLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁名',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
//数据库中的每一条记录就是一把锁,利用的mysql唯一索引的排他性
//lock和unlock只是函数名
lock(name,desc){
insert into DistributedLock(`name`,`desc`) values (#{name},#{desc});
}
unlock(name){
delete from DistributedLock where name = #{name}
}
乐观锁:乐观的任务数据不会出现数据安全问题,如果出现了就重试一次
select ...,version;
update table set version+1 where version = xxx
Redis
setNX: setNX(key,value) :如果key不存在那么就添加key的值,否则添加失败,Redisson。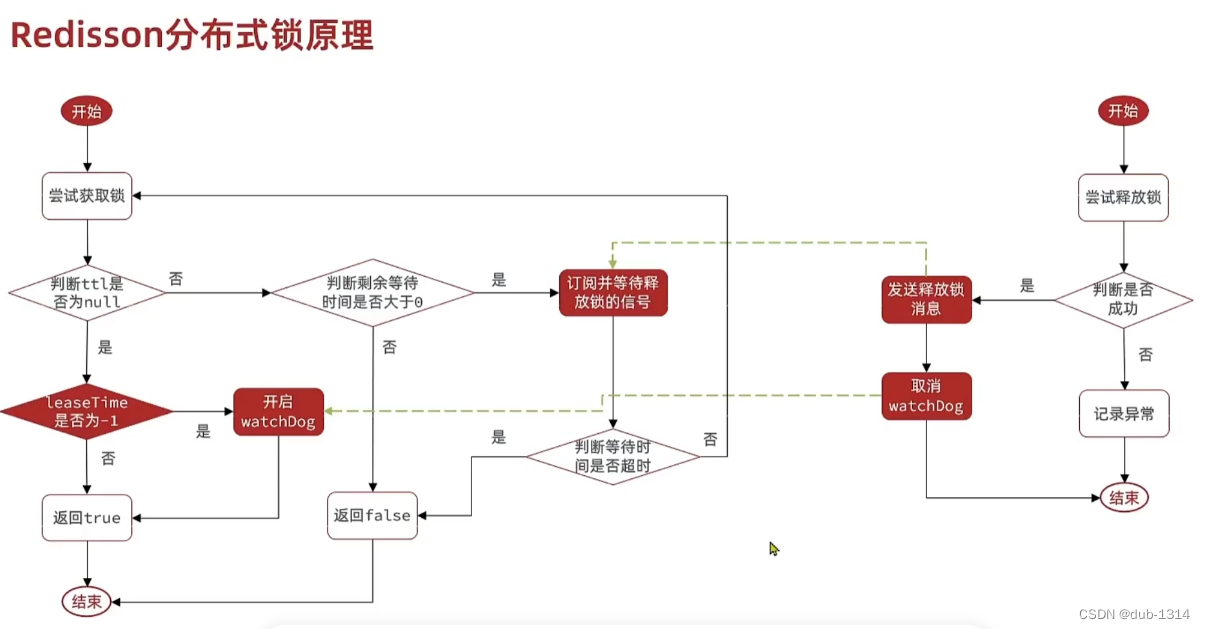
Zookeeper

其基本思想是创建一个临时有序节点,临时节点保证在客户端断开连接或者超时zookeeper会自动删除该节点,从而避免死锁的发生,有序节点可以实现一种公平锁,加锁顺序按照客户端进程请求顺序进行,加锁的为产生节点序号最小的那个客户端。
加锁:客户端在zookeeper创建临时节点,并判断自己是不是节点序号最小的,如果是则加锁成功,如果不是则watch监听它前一个节点删除事件,当收到前一个节点删除通知时重复前面逻辑,直到加锁完成
解锁:客户端完成业务逻辑,在zookeeper删除自己的临时节点,同时通知它后一个节点获取锁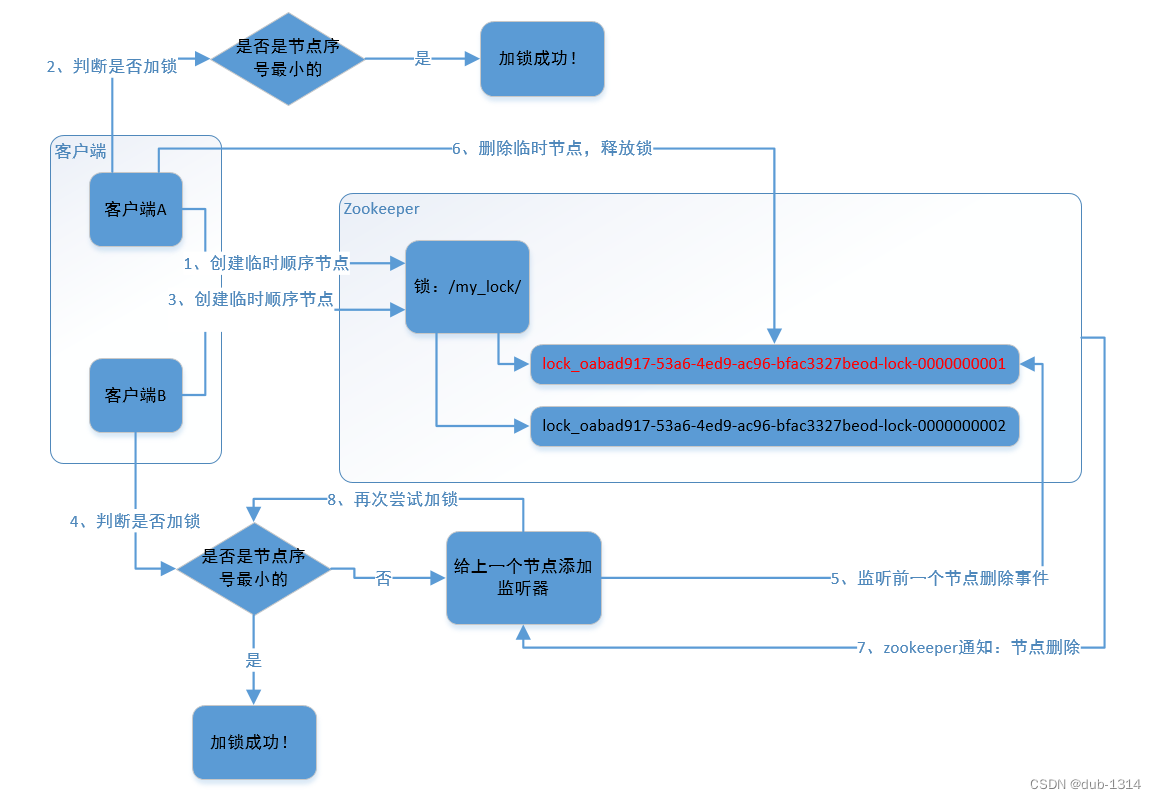
Redis实现分布式锁
public Map<String, List<Catalog2VO>> getCatelog2JSONDbWithRedisLock() {
String keys = "catalogJSON";
// 加锁
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "1111");
if(lock){
// 加锁成功
Map<String, List<Catalog2VO>> data = getDataForDB(keys);
// 从数据库中获取数据成功后,我们应该要释放锁
stringRedisTemplate.delete("lock");
return data;
}else{
// 加锁失败
// 休眠+重试
// Thread.sleep(1000);
return getCatelog2JSONDbWithRedisLock();
}
}
///如果getDataForDB出现异常,则会出现死锁,
///加上过期时间可以解决
// 给对应的key设置过期时间
stringRedisTemplate.expire("lock",20,TimeUnit.SECONDS);
///如果在expire方法执行之前就中断也会出现死锁
///创建锁时同时加上过期时间
// 加锁 在执行插入操作的同时设置了过期时间
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "1111",30,TimeUnit.SECONDS);
///如果获取锁的业务执行时间比较长,超过了我们设置的过期时间,那么就有可能业务还没执行完,锁就释放了,然后另一个请求进来了,并创建了key,这时原来的业务处理完成后,再去删除key的时候,那么就有可能删除别人的key,如何解决
///查询的锁的信息通过UUID来区分
public Map<String, List<Catalog2VO>> getCatelog2JSONDbWithRedisLock() {
String keys = "catalogJSON";
// 加锁 在执行插入操作的同时设置了过期时间
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid,30,TimeUnit.SECONDS);
if(lock){
// 给对应的key设置过期时间
stringRedisTemplate.expire("lock",20,TimeUnit.SECONDS);
// 加锁成功
Map<String, List<Catalog2VO>> data = getDataForDB(keys);
// 获取当前key对应的值
String val = stringRedisTemplate.opsForValue().get("lock");
if(uuid.equals(val)){
// 说明这把锁是自己的
// 从数据库中获取数据成功后,我们应该要释放锁
stringRedisTemplate.delete("lock");
}
return data;
}else{
// 加锁失败
// 休眠+重试
// Thread.sleep(1000);
return getCatelog2JSONDbWithRedisLock();
}
}
///key的值和删除key其实不是一个原子性操作,这就会出现我查询出来key之后,时间过期了,然后key被删除了,然后其他的请求创建了一个新的key,然后原来的执行删除了这个key,又出现了删除别人key的情况
///脚本执行(lua)
String srcipts = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end ";
// 通过Redis的lua脚本实现 查询和删除操作的原子性
stringRedisTemplate.execute(new DefaultRedisScript<Integer>(srcipts,Integer.class)
,Arrays.asList("lock"),uuid);
Redisson分布式锁
原理
加锁原理
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
一个客户端要加锁,它首先会根据hash节点选择一台机器,这里注意仅仅只是选择一台机器,紧接着就会发送一段封装好的 lua 脚本到 redis 上,比如加锁的那个锁key就是”mylock”,并且设置的时间是30秒,30秒后mylock锁就会被自动释放。
锁互斥机制
第一个线程加锁完成后,此时,如果客户端 2 来尝试加锁会如何呢?首先,第一个 if 判断会执行 exists myLock,发现 myLock 这个锁 key 已经存在了。接着第二个 if 判断,判断一下,myLock 锁 key 的 hash 数据结构中,是否包含客户端 2 的 ID,这里明显不包含客户端 2 的ID,因为那里包含的是客户端 1 的 ID。所以,客户端 2 会执行:
return redis.call('pttl', KEYS[1]);
//返回的是一个数字,这个数字就是 myLock 这个锁 key 的剩余生存时间
锁阻塞机制
当锁正在被其他线程占用的时候,等待获取锁的线程并不是通过一个 while(true) 死循环去获取锁,而是利用了 Redis 的发布订阅机制,通过 await 方法阻塞等待锁的进程,有效的解决 不断的申请锁浪费资源的问题。
锁续期机制
【1】客户端 1 加锁的默认生存(等待)时间为30秒,如果超过了30秒,客户端 1 还想一直持有这把锁,怎么办?
【2】Redisson 提供了一个续期机制,只要客户端 1 一旦加锁成功,就会启动一个 Watch Dog (看门狗)。
【3】Watch Dog 它是一个后台定时任务线程,会每隔10秒(internalLockLeaseTime / 3)检查一下(遍历 EXPIRATION_RENEWAL_MAP 里面线程 id 然后根据线程 id 去 Redis 中查,如果存在就会延长 key 的时 间),如果客户端 1 还持有锁key,那么就会不断的延长锁key的生存时间,直至业务执行结束或者该线程主 动释放锁。
源码
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {
long threadId = Thread.currentThread().getId();
//尝试获取锁
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
//获得锁直接返回
if (ttl == null) {
return;
}
//订阅与锁关联的Redis频道
RFuture<RedissonLockEntry> future = subscribe(threadId);
if (interruptibly) {
commandExecutor.syncSubscriptionInterrupted(future);
} else {
commandExecutor.syncSubscription(future);
}
try {
while (true) {
ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
//如果ttl >= 0,表示等待获取锁的时间(在给定的TTL时间内)。在这个时间段内,线程将尝试获取锁。如果在此期间发生中断,并且interruptibly为真,则抛出中断异常;否则,再次尝试获取锁。
if (ttl >= 0) {
try {
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
if (interruptibly) {
throw e;
}
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
}
} else {
if (interruptibly) {
future.getNow().getLatch().acquire();
} else {
future.getNow().getLatch().acquireUninterruptibly();
}
}
}
} finally {
//清理订阅的资源
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));
}
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
if (leaseTime != -1) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
//过期时间为看门狗的默认时间,30秒
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
//开启一个定时任务进行不断刷新过期时间
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
this.internalLockLeaseTime = commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout();
private long lockWatchdogTimeout = 30 * 1000;
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
// 首先判断锁是否存在
"if (redis.call('exists', KEYS[1]) == 0) then " +
// 存在则获取锁
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
// 然后设置过期时间
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// hexists查看哈希表的指定字段是否存在,存在锁并且是当前线程持有锁
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
// hincrby自增一
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
// 锁的值大于1,说明是可重入锁,重置过期时间
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 锁已存在,且不是本线程,则返回过期时间ttl
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
protected void scheduleExpirationRenewal(long threadId) {
//该对象将用于存储需要刷新锁过期时间的线程ID
ExpirationEntry entry = new ExpirationEntry();
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
//将当前线程ID添加到oldEntry中,表示该线程也需要参与锁的过期刷新
oldEntry.addThreadId(threadId);
} else {
entry.addThreadId(threadId);
//调用renewExpiration()方法来刷新锁的过期时间。这通常涉及到与Redis服务器交互,以更新锁的过期时间
renewExpiration();
}
}
//主要目的是确保锁的过期时间能够定期自动刷新,以防止锁在使用过程中意外过期。它使用定时任务来定期检查并更新锁的过期时间,并在成功更新后重新调度任务,以便在未来继续刷新。如果更新失败或不再需要刷新,它会取消刷新任务并从映射中移除相关条目。这种方式可以有效地管理锁的生命周期,并减少因锁过期导致的问题。
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
//不需要刷新过期时间
if (ee == null) {
return;
}
//命令执行器的连接管理器创建一个新的定时任务,该任务将在内部锁续约时间的三分之一时长后运行(10秒)
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
//异步更新锁的过期时间,续约
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getRawName() + " expiration", e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// reschedule itself
renewExpiration();
} else {
cancelExpirationRenewal(null);
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
Redisson整合
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.1</version>
</dependency>
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author guanglin.ma
* @date 2023-12-24 22:45
*/
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient RedissonClientConfig(){
Config config = new Config();
//可以用"rediss://"来启用SSL连接
config.useSingleServer().setAddress("redis://192.168.56.10:6379");
return Redisson.create(config);
}
}
可重入锁
https://blog.csdn.net/hkl_Forever/article/details/128164070
读写锁
在读写锁中,只有读读的行为是共享锁,相互之间不影响,只要有写的行为存在,那么就是一个互斥锁(排他锁)
@GetMapping("/writer")
@ResponseBody
public String writerValue(){
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("rw-lock");
// 加写锁
RLock rLock = readWriteLock.writeLock();
String s = null;
rLock.lock(); // 加写锁
try {
s = UUID.randomUUID().toString();
stringRedisTemplate.opsForValue().set("msg",s);
Thread.sleep(30000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rLock.unlock();
}
return s;
}
@GetMapping("/reader")
@ResponseBody
public String readValue(){
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("rw-lock");
// 加读锁
RLock rLock = readWriteLock.readLock();
rLock.lock();
String s = null;
try {
s = stringRedisTemplate.opsForValue().get("msg");
}finally {
rLock.unlock();
}
return s;
}
闭合锁
基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象 RCountDownLatch采用了与 java.util.concurrent.CountDownLatch相似的接口和用法。
//先关门熄灯,await等待数量消费到0即可继续往下执行
@GetMapping("/lockDoor")
@ResponseBody
public String lockDoor(){
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.trySetCount(5);
try {
door.await(); // 等待数量降低到0
} catch (InterruptedException e) {
e.printStackTrace();
}
return "关门熄灯...";
}
@GetMapping("/goHome/{id}")
@ResponseBody
public String goHome(@PathVariable Long id){
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.countDown(); // 递减的操作
return id + "下班走人";
}
信号量(Semaphore)
基于Redis的Redisson的分布式信号量(Semaphore)Java对象RSemaphore采用了与 java.util.concurrent.Semaphore相似的接口和用法。同时还提供了异步(Async)、反射式(Reactive)和RxJava2标准的接口。
@GetMapping("/park")
@ResponseBody
public String park(){
RSemaphore park = redissonClient.getSemaphore("park");
boolean b = true;
try {
// park.acquire(); // 获取信号 阻塞到获取成功
b = park.tryAcquire();// 返回获取成功还是失败
} catch (Exception e) {
e.printStackTrace();
}
return "停车是否成功:" + b;
}
//释放10次,就有10个车位
@GetMapping("/release")
@ResponseBody
public String release(){
RSemaphore park = redissonClient.getSemaphore("park");
park.release();
return "释放了一个车位";
}
缓存数据一致性问题
双写模式
https://baijiahao.baidu.com/s?id=1763573615688107095&wfr=spider&for=pc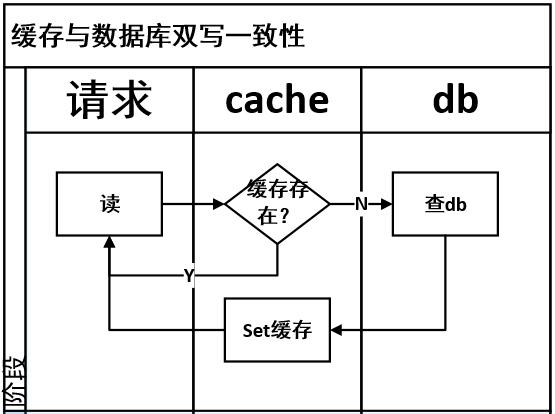
更新过程
**策略一:**先更新db,再删除缓存(常用的Cache-Aside Pattern旁路缓存)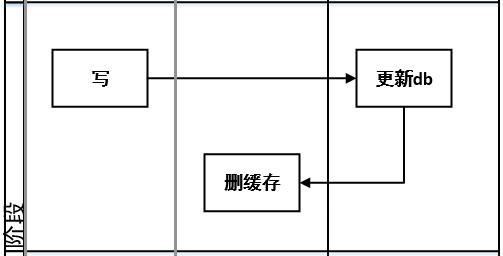
问题:如果更新db成功,删缓存失败,将导致数据不一致。
**策略二:**先更新db,再更新缓存
问题:
1、并发更新场景下,更新缓存会导致数据不一致。
2、根据读写比,考虑是否有必要频繁同步更新缓存,而且,如果构造缓存中数据过于复杂,或者数据更新频繁,但是读取并不频繁的情况,还会造成不必要的性能损耗。(此种方式不推荐)
**策略三:**先更新缓存,再更新db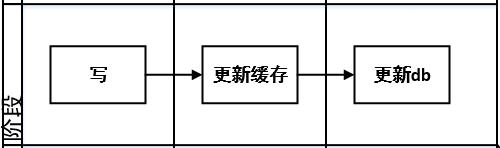
问题:不推荐
**策略四:**先删缓存,再更新db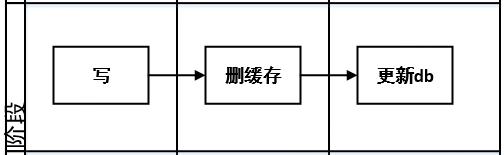
问题:先删缓存,虽然解决了策略1中,后删缓存如果失败的场景,但也会发生不一致的问题。
例如:请求 A 删除缓存,这时请求B来查,就会击穿到数据库,B读取到旧的值后写入缓存,A正常更新db,由于时间差导致数据不一致的情况。
**策略五:**缓存延时双删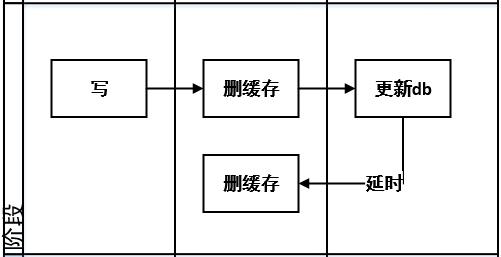
问题:该策略兼容了策略1和策略4,解决了先删缓存还是后删缓存的问题,如策略1中,更新db后删缓存失败和策略4中的不一致场景,该策略可以将延时时间内(比如延时10ms)所造成的缓存脏数据,再次删除。但是,如果延时删缓存失败,策略4中不一致问题还会发生,同时延时的实现,如创建线程,或者引入mq异步,可能会增加系统复杂度问题。
**策略六:**变种双删,前置缓存过期时间
问题:该策略针对策略1中后删缓存失败的场景,前置一层缓存数据过期时间(具体时间根据自身系统本身评估,如可覆盖db读写耗时或一致性容忍度等),更新db后就算删缓存失败,在expire时间后也能保证缓存中无数据。同时,前置expire失败,或者更新db失败,都不会影响数据一致。
能够解决策略4中的问题:请求 A 删除缓存,这时请求B来查,就会击穿到数据库,B读取到旧的值后写入缓存,A正常更新db,由于时间差导致数据不一致的情况,描述图如下: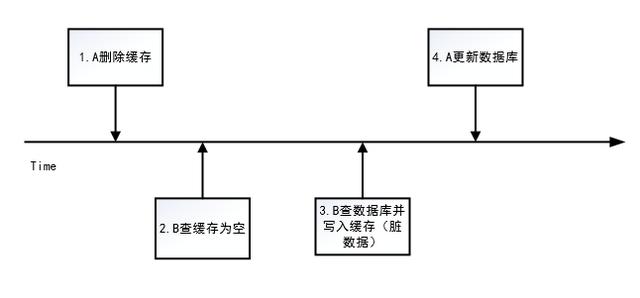
本策略中步骤1为expire缓存,不会发生击穿缓存到数据库的情况,数据将直接返回。除非更极端情况,如下图:
expire时间没有覆盖住更新db的耗时,类似策略1中极端场景
策略七:
问题:
失效模式
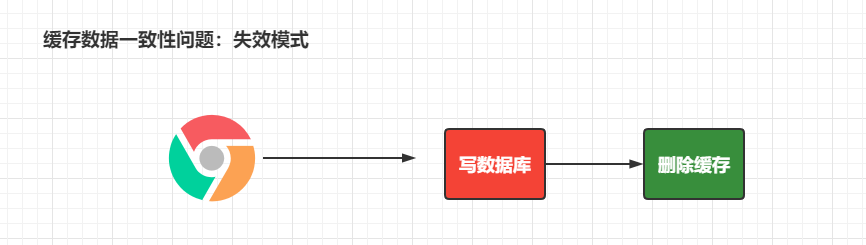

总结
针对于上的两种解决方案我们怎么选择?
- 缓存的所有数据我们都加上过期时间,数据过期之后主动触发更新操作
- 使用读写锁来处理,读读的操作是不相互影响的
无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加 上过期时间,每隔一段时间触发读的主动更新即可
- 如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心 脏数据,允许临时脏数据可忽略)
总结:
-
我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
-
我们不应该过度设计,增加系统的复杂性
-
遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
SpringCache
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency>spring: redis: host: localhost port: 6379 #password: database: 0 cache: redis: time-to-live: 1800000 #过期时间@EnableCaching ... @SpringBootApplication public class GulimallProductApplication { ... }SpringCache 如下注解为我们提供缓存的操作 @Cacheable 触发将数据保存到缓存的操作。 如果缓存中有数据,被标注的方法不调用。 key 默认自动生成:缓存名字::SimpleKey [] ,如 category::SimpleKey [] 。 缓存值默认使用 jdk 序列化机制将序列化后的数据存到缓存。 默认过期时间是 -1。 @CacheEvict 将数据从缓存删除。 @CachePut 沉浸式更新缓存。 @Caching 组合多个缓存操作。
使用
//SpEL
//"#setmeal.categoryId" 表示获取变量 "setmeal" 的属性 "categoryId" 的值。
//"''+" 是一个字符串连接操作,用于在两个值之间添加下划线字符 ""。
//"#setmeal.status" 表示获取变量 "setmeal" 的属性 "status" 的值。
//@CachePut注解在执行添加操作时,将新的数据添加到Redis缓存中,以便于数据库查询的值和展示的数据一致。Redis底层执行的是set操作。
@PostMapping
@CachePut(value = "setmealCache",key = "#setmealDto.categoryId+'_'+#setmealDto.status")
public R<String> save(@RequestBody SetmealDto setmealDto){
return R.success("新增套餐成功");
}
//@CacheEvict注解执行修改、删除数据操作时删除对应的所有该名称(value=值)下的缓存数据,以便于数据库查询的值和展示的数据一致。Redis底层执行的是del(删除)操作。下次在删除修改完后查询时就会重新执行sql语句去数据库中查询数据,这样就使得数据库与缓存数据一致。
@PutMapping
@CacheEvict(value = "setmealCache",allEntries = true)
public R<String> update(@RequestBody SetmealDto setmealDto){
return R.success("修改成功");
}
//@Cacheable注解,将查询的数据放到Redis中,所以Redis底层代码也是做的set操作。
@GetMapping("/list")
//将返回的结果存入redis缓存中
@Cacheable(value = "setmealCache",key = "#setmeal.categoryId+'_'+#setmeal.status")
public R<List<Setmeal>> list(Setmeal setmeal){
return R.success(list);
}
源码
配置类里面的选择器,加载把相关的配置类进行加载。对应yaml里面的type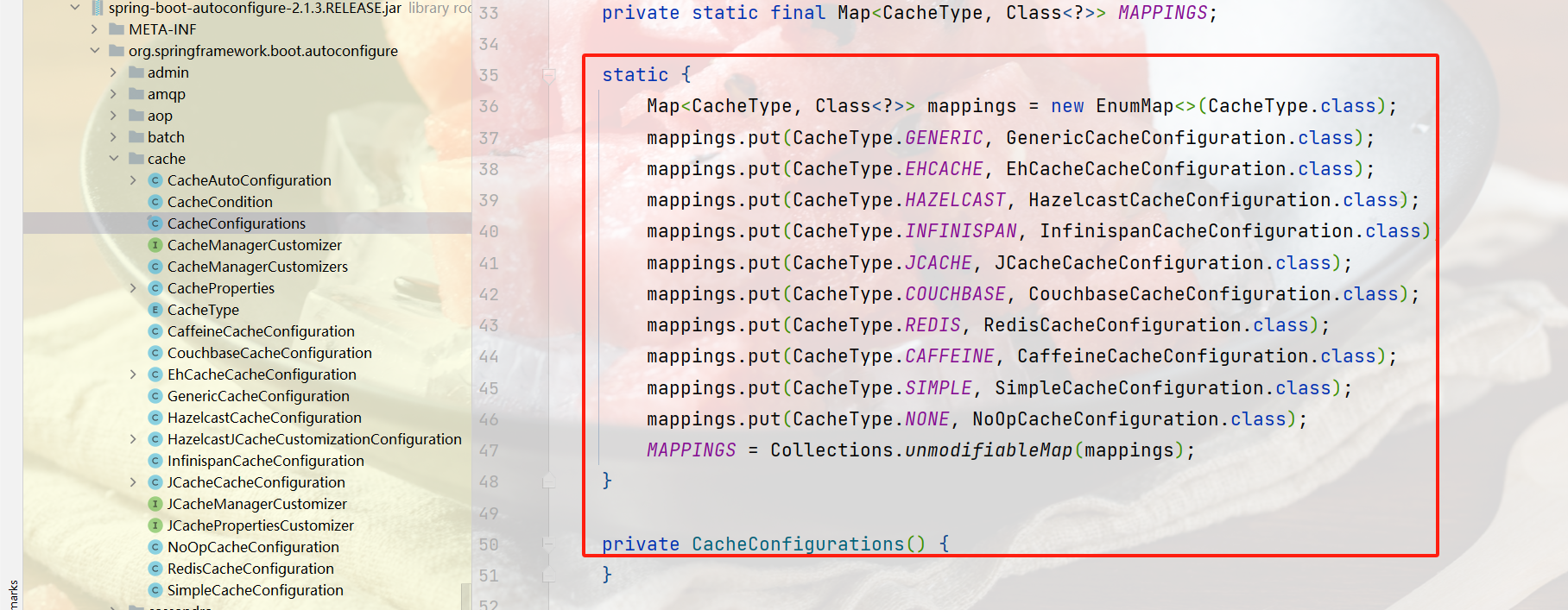
其他
SpringCache的不足:
1).读模式
- 缓存穿透:查询一个null的数据。可以解决 cache-null-values=true
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:分布式锁 sync=true 本地锁
- 缓存雪崩:大量的key同一个时间点失效。解决方案:添加过期时间 time-to-live=60000 指定过期时间
2).写模式
- 读写锁
- 引入canal,监控binlog日志文件来同步更新数据
- 读多写多,直接去数据库中读取数据即可
总结:
- 常规数据(读多写少):而且对及时性和数据的一致性要求不高的情况,我们完全可以使用SpringCache
- 特殊情况:特殊情况特殊处理。
原文地址:https://blog.csdn.net/qq_40691438/article/details/135951808
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_67791.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!