本文介绍: ToG 方法的本质在于,通过LLM执行的知识图谱上的beam search,分阶段探索和评估推理路径,以便深度推理出复杂问题的精确答案,而 ToG-R 进一步减少了LLM调用,强调文字信息,提高了效率和鲁棒性。LLM使用的是链式思考,首先确认堪培拉是澳大利亚的首都,然后基于2021年9月的信息,认为澳大利亚总理是斯科特·莫里森,属于自由党,所以答案应该是自由党。此外,ToG的性能也受到搜索深度和宽度的影响,通过调整这两个参数,ToG的表现有所提升,尽管提升的幅度在深度超过一定阈值后会减弱。
论文:https://arxiv.org/abs/2307.07697
代码:https://github.com/IDEA-FinAI/ToG
Think-on-Graph 原理
幻觉是什么:大模型的「幻觉」问题。
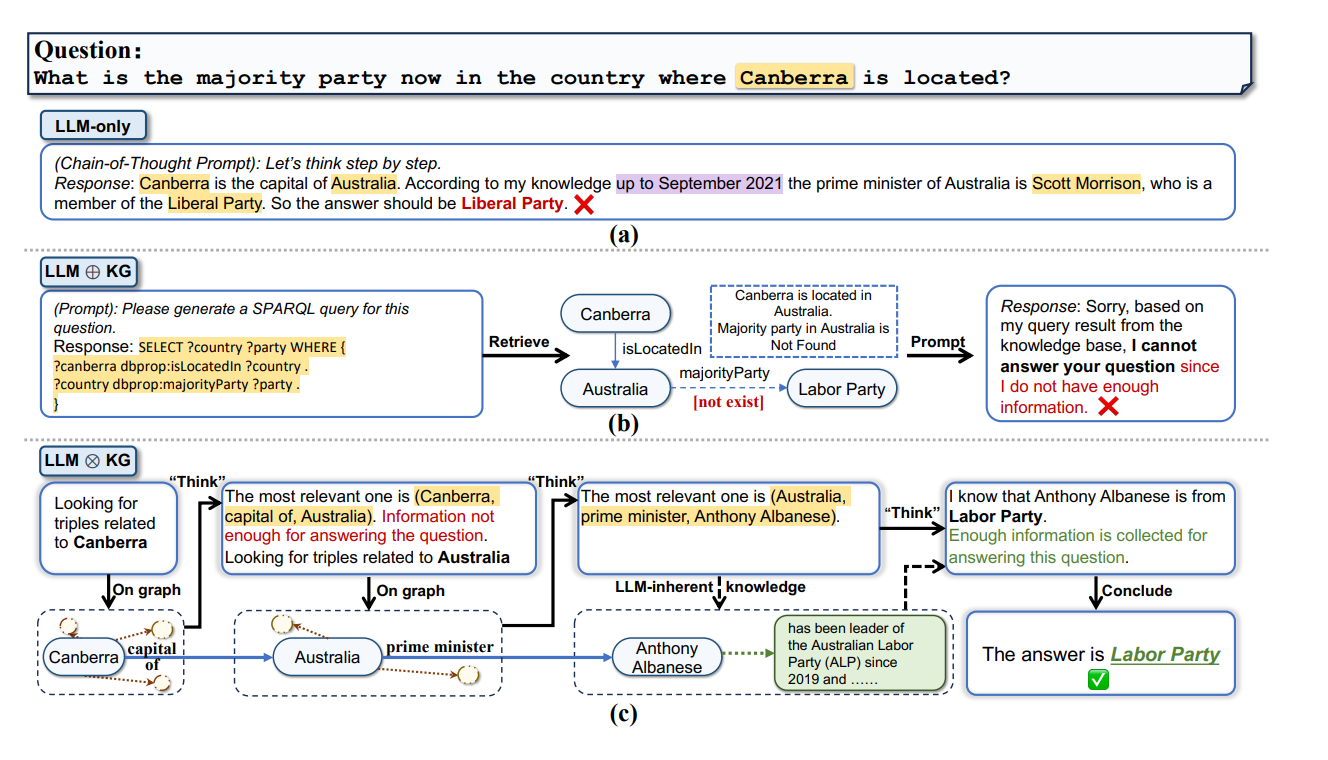

ToG 算法步骤:想想再查,查查再想

实验结果
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。