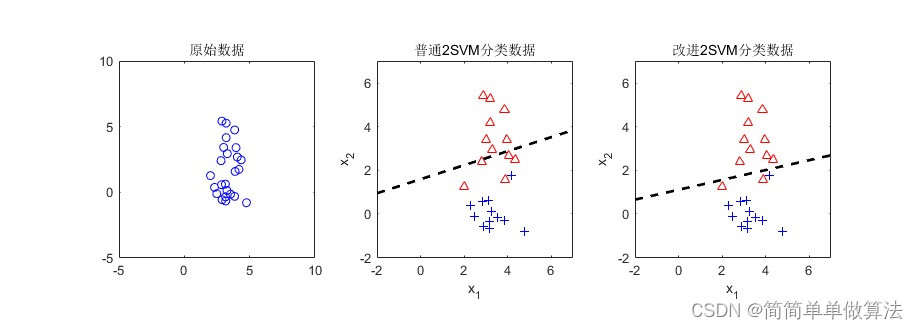
本文介绍: 自然语言处理-词向量
本文关注NLP自然语言处理中的基础,词向量
什么是NLP自然语言处理
人工智能的重要突破点之一,就是自然语言处理,应用范围很广,下游任务包括词性分析、情感分析、生成对话等等。

发展历程
自然语言的处理经历了多个阶段,基于概率、统计等等,但是很难满足复杂的语言体系,直到最近基于深度学习模型的出现,才更好的解决了这个问题。
自然语言处理模型
目前流行的模型都是基于transformer架构的大模型,不去了解细节的话,transfomer是编码器加解码器。
简单理解:编码器用来处理输入,解码器用来输出。
现在比较出名的三大模型分支里全部都是由transformer演化出来,基于transformer的编码器BERT家族,基于解码器的GPT一支,还有一支是编码器和解码器都用了,比如google的T5模型,所以很多模型的简写里面都带了T,是因为都是transformer的变体。
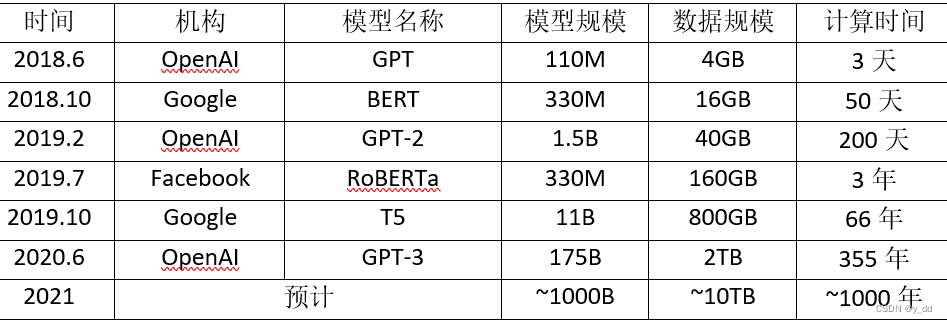
所谓的大模型****,大是指参数大,GPT-3就已经是1750亿的水平了,这些参数的训练已经不是普通中小玩家可以训练起来的水平了;
对于自然语言来说肯定是要处理句子和单词的,那么问题就来了,电脑或者说模型知道每个单词的意思么?
模型能识别单词的方法
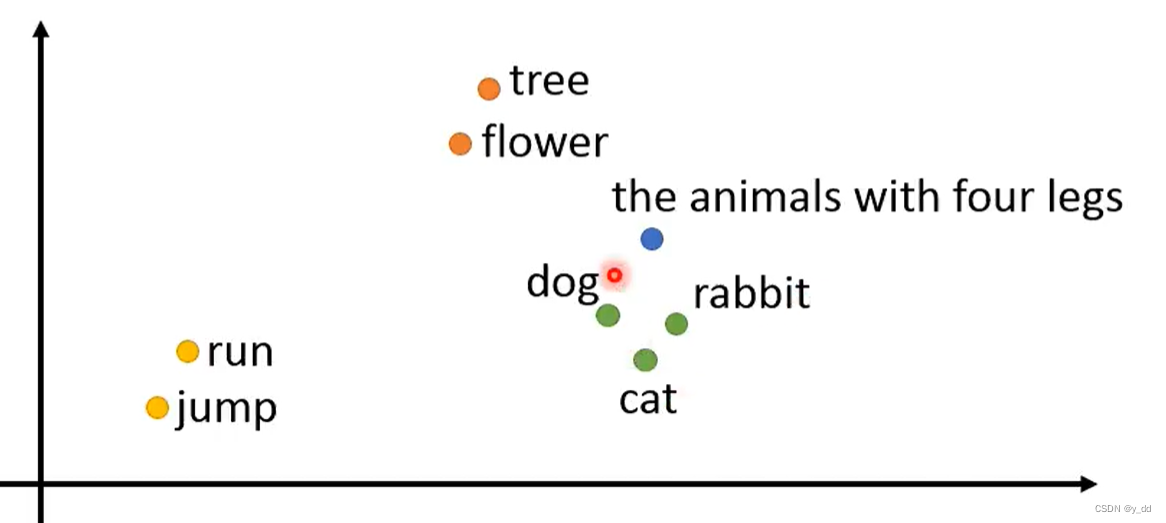
词向量
分词
一个向量vector表示一个词
词向量的表示-one-hot
多维词嵌入word embeding
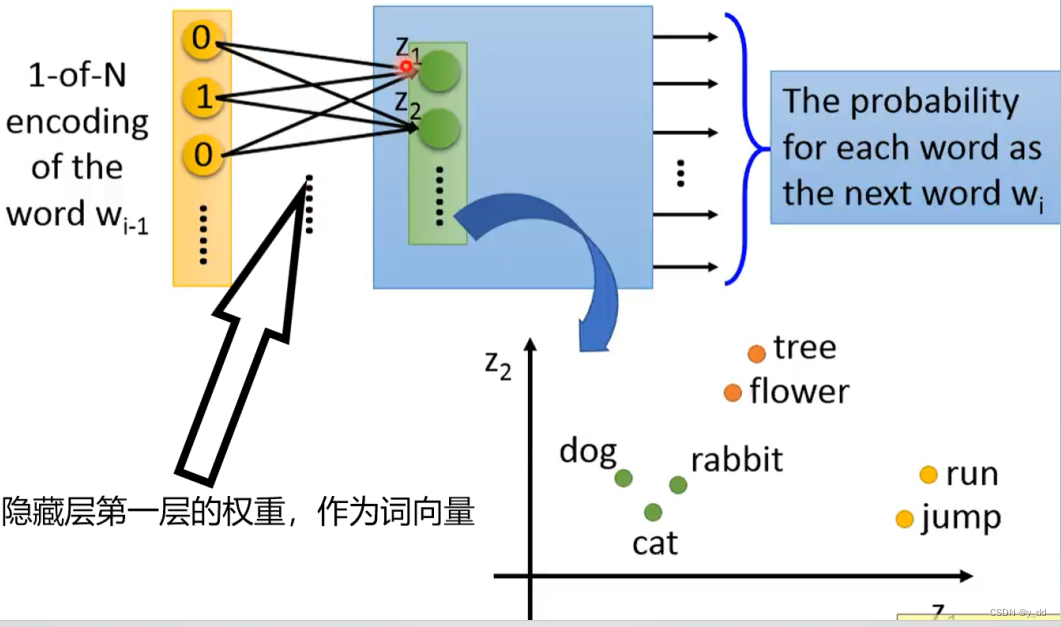

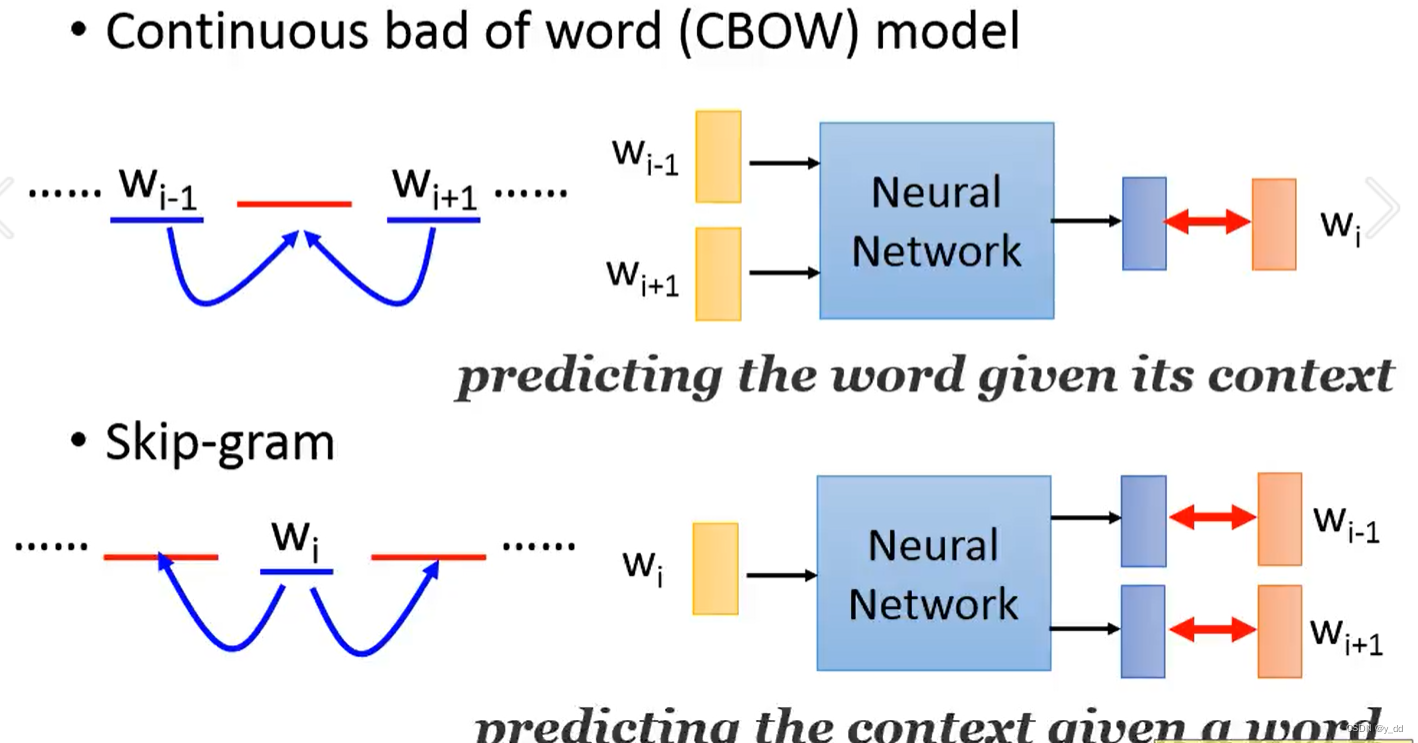
词向量的训练方法 CBOW Skip-gram
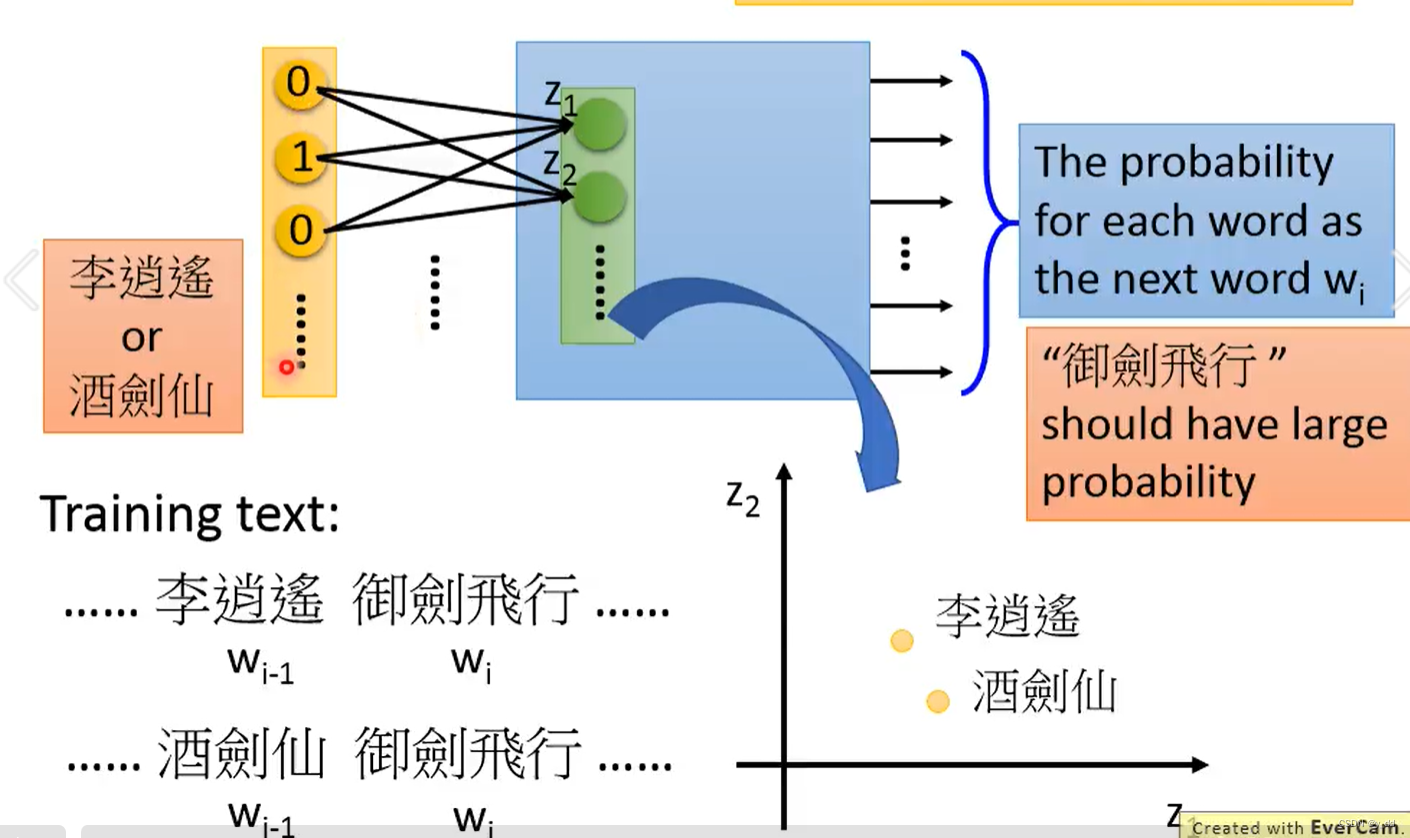
词嵌入的理论依据
一个vector(向量)表示短语或者文章
vector space Model
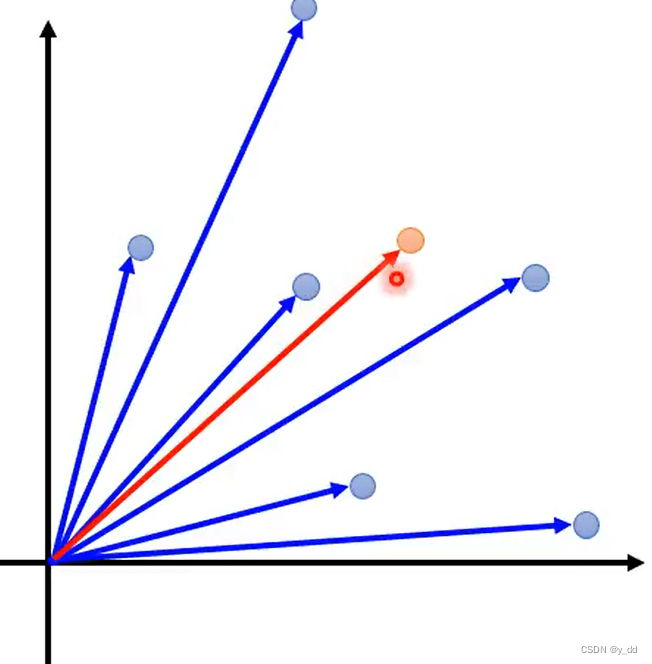
bag-of-word

vector space Model + bag-of-word 实现信息搜索
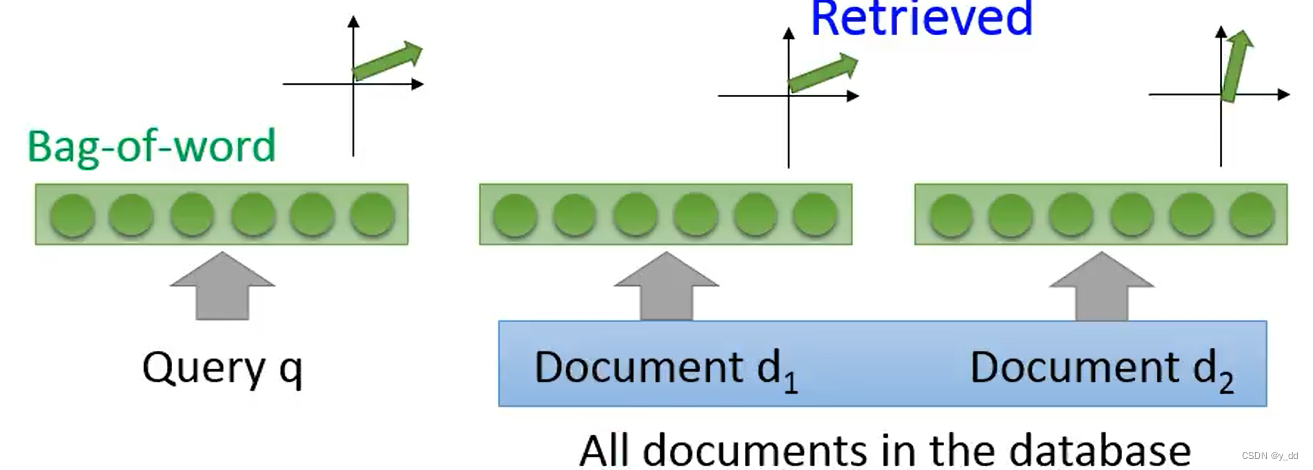
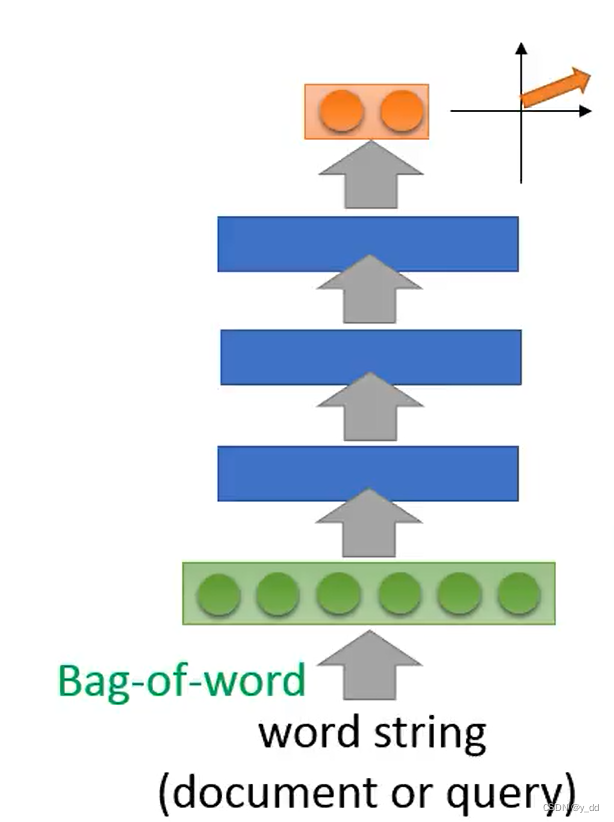
改进版 bag-of-word
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。