从Kafka系统中读取消息数据——消费
转自《 Kafka并不难学!入门、进阶、商业实战》
消费者是读取kafka分区中信息的一个实例
注意:
一个消费者可以读取多个分区
一个分区不能被多个消费者读取
消费 Kafka 集群中的主题消息
检查消费者是不是单线程
Kafka 系统的消费者接口是向下兼容的,即,在新版 Kafka 系统中老版的消费者接口仍可以使用。在新版本的 Kafka 系统中,消费者程序代码被重构了–通过 Java 语言对消费者KafkaConsumer 类进行了重新编码。
KafkaConsumer 是非多线程并发安全的:如果多个线程公用一个 KafkaConsumer 实例,则抛出异常错误信息。KafkaConsumer 类中判断是否为单线程的内容见代码 5-2。
/**设置轻量级所来阻止多线程并发访问 */
private void acquire(){
// 检测当前消费者对象是否关闭
ensureNotClosed();
//获取当前消费者程序线程 ID
long threadId = Thread.currentThread().getId();// 判断是否主为单线程
if (threadld != currentThread.get()
&& !currentThread.compareAndSet(NO CURRENT THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe formulti-threaded access");
refcount.incrementAndGet();
}
KafkaConsumer 类通过 acquire()函数来监控访问的请求是否存在并发多线程操作。如果存在,则抛出一个 ConcurrentModificationException 异常
主题如何自动获取分区和手动分配分区
阅读 KafkaConsumer 类的实现代码可以发现,该类实现了org.apache.kafka.clients.consumer.Consumer 接口。该接口提供了用户访问 Kafka 集群主题的应用接口,主要包含以下两种。
- subscribe:订阅指定的主题列表,来获取自动分配的分区;
- assign:手动向主题分配分区列表,指定需要“消费”的分区。
- 自动获取分区
如果调用 subscribeO函数订阅主题,则消费者组中的消费者程序会被动态分配到分区,同时被指定一个 org.apache.kafka.clients.consumer.ConsumerRebalanceListener 接口。当用户分配给消费者程序的分区集合发生变化时,可以通过回调函数的接口来触发自定义操作。
使用 subscribe0函数订阅主题时,有三个重载函数可供选择。
(1)subscribe(Collectiontopics):指定订阅主题集合:
(2)subscribe(Collection topics, ConsumerRebalanceListener callback):分区发生变化时,通过回调函数来进行自动分区操作;
(3)subscribe(Pattern pattern, ConsumerRebalanceListener callback):使用正则表达式来订阅主题,当主题或者主题分区发生变化时,通过回调函数来进行自动分区操作。 - 手动分配分区
手动分配分区的方式可以通过调用 assignO函数来实现。assignO)函数与 subscribeO)函数的底层实现逻辑类似,也是先做一系列的检查工作,比如,是否含有并发操作、请求的参数是否合法(分区是否为空)等。
subscribe实现订阅(自动获取分区)
/**
* 实现一个消费者实例代码.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JConsumerSubscribe extends Thread {
public static void main(String[] args) {
JConsumerSubscribe jconsumer = new JConsumerSubscribe();
jconsumer.start();
}
/** 初始化Kafka集群信息. */
private Properties configure() {
Properties props = new Properties();
props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址
props.put("group.id", "ke");// 指定消费者组
props.put("enable.auto.commit", "true");// 开启自动提交
props.put("auto.commit.interval.ms", "1000");// 自动提交的时间间隔
// 反序列化消息主键
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化消费记录
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
/** 实现一个单线程消费者. */
@Override
public void run() {
// 创建一个消费者实例对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configure());
// 订阅消费主题集合
consumer.subscribe(Arrays.asList("ip_login_rt"));
// 实时消费标识
boolean flag = true;
while (flag) {
// 获取主题消息数据
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// 循环打印消息记录
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
// 出现异常关闭消费者对象
// consumer.commitAsync();
// consumer.commitSync();
consumer.close();
}
}
assign(手动分配分区)
/**
* 实现一个手动分配分区的消费者实例.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JConsumerAssign extends Thread {
public static void main(String[] args) {
JConsumerAssign jconsumer = new JConsumerAssign();
jconsumer.start();
}
/** 初始化Kafka集群信息. */
private Properties configure() {
Properties props = new Properties();
props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址
props.put("group.id", "ke");// 指定消费者组
props.put("enable.auto.commit", "true");// 开启自动提交
props.put("auto.commit.interval.ms", "1000");// 自动提交的时间间隔
// 反序列化消息主键
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化消费记录
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
/** 实现一个单线程消费者程序. */
@Override
public void run() {
// 创建一个消费者实例对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configure());
// 设置自定义分区
TopicPartition tp = new TopicPartition("test_kafka_game_x", 0);
// 手动分配
consumer.assign(Collections.singleton(tp));
// 实时消费标识
boolean flag = true;
while (flag) {
// 获取主题消息数据
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// 循环打印消息记录
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
// 出现异常关闭消费者对象
consumer.close();
}
}
反序列化主题消息
在分布式环境下,有序列化和反序列化两个概念
- 序列化:将对象转换为字节序列,然后在网络上传输或者存储在文件中;
- 反序列化:将网络或者文件中读取的字节序列数据恢复成对象。
- 为什么需要实现反序列
在传统企业应用中,不同的组件分布在不同的系统和网络中,通过序列化协议实现对象的传输,保证了两个组件之间的通信安全。经过序列化后的消息数据会转换成二进制。
如果需要将这些二进制进行业务逻辑处理,则需要将这些二进制数据进行反序列化,将其还原成对象。 - 反序列一个对象
为了反序列化一个对象,用户必须保证序列化对象和反序列化对象一致下面以 Java 语言为例,实现一个反序列化类。
反序列化一个类.
/**
* 反序列化一个类.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JObjectDeserialize {
/** 创建一个日志对象实例. */
private static Logger LOG = LoggerFactory.getLogger(JObjectSerial.class);
/** 实例化入口函数. */
@SuppressWarnings("resource")
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("/tmp/salary.out"); // 实例化一个输入流对象
JObjectSerial jos = (JObjectSerial) new ObjectInputStream(fis).readObject();// 反序列化还原对象
LOG.info("ID : " + jos.id + " , Money : " + jos.money);// 打印反序列化还原后的对象属性
} catch (Exception e) {
LOG.error("Deserial has error, msg is " + e.getMessage());// 打印异常信息
}
}
}
演示 Kafka 自定义反序列化代码
Kafka 系统中提供了反序列化的接口,以方便用户调用。用户可以通过自定义反序列化的
方式来还原对象。
下面通过实例演示 Kafka 白定义反序列化具体操作。
(1)编写一个反序列化工具类;

/**
* 封装一个序列化的工具类.
*
* @author smartloli.
*
* Created by Apr 30, 2018
*/
public class SerializeUtils {
/** 实现序列化. */
public static byte[] serialize(Object object) {
try {
return object.toString().getBytes("UTF8");// 返回字节数组
} catch (Exception e) {
e.printStackTrace(); // 抛出异常信息
}
return null;
}
/** 实现反序列化. */
public static <T> Object deserialize(byte[] bytes) {
try {
return new String(bytes, "UTF8");// 反序列化
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
(2)编写自定义反序列化逻辑代码;
/**
* 实现自定义反序列化.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JSalaryDeserializer implements Deserializer<Object> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
/** 自定义反序列逻辑. */
@Override
public Object deserialize(String topic, byte[] data) {
return SerializeUtils.deserialize(data);
}
@Override
public void close() {
}
}
(3)编写一个消费者应用程序;
/**
* 实现一个消费者实例代码.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JConsumerDeserialize extends Thread {
/** 自定义序列化消费者实例入口. */
public static void main(String[] args) {
JConsumerDeserialize jconsumer = new JConsumerDeserialize();
jconsumer.start();
}
/** 初始化Kafka集群信息. */
private Properties configure() {
Properties props = new Properties();
props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址
props.put("group.id", "ke");// 指定消费者组
props.put("enable.auto.commit", "true");// 开启自动提交
props.put("auto.commit.interval.ms", "1000");// 自动提交的时间间隔
// 反序列化消息主键
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 反序列化消费记录
props.put("value.deserializer", "org.smartloli.kafka.game.x.book_5.deserialize.JSalaryDeserializer");
return props;
}
/** 实现一个单线程消费者. */
@Override
public void run() {
// 创建一个消费者实例对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configure());
// 订阅消费主题集合
consumer.subscribe(Arrays.asList("test_topic_ser_des"));
// 实时消费标识
boolean flag = true;
while (flag) {
// 获取主题消息数据
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// 循环打印消息记录
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
// 出现异常关闭消费者对象
consumer.close();
}
}
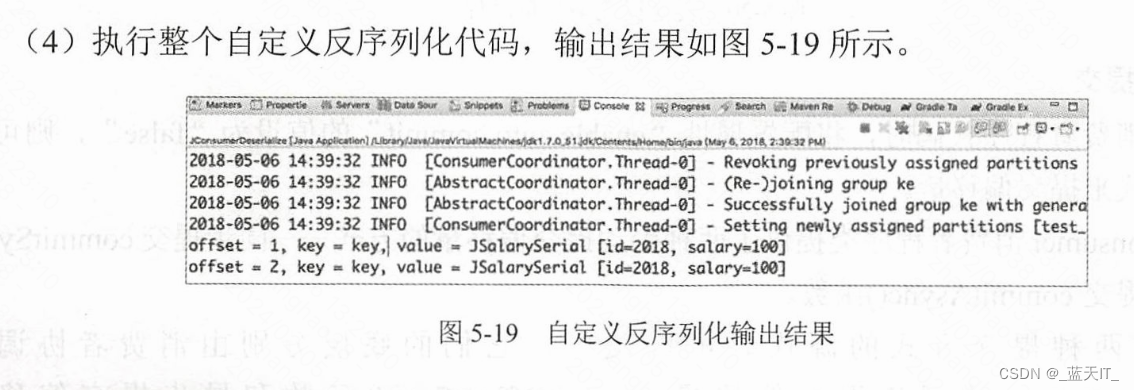
(4)执行整个自定义反序列化代码,输出结果如图5-19 所示。
如何提交消息的偏移量
Kafka 0.10.0x 版本之前的消费者程序会将“消费”的偏移量(Ofsets)提交到 Zookeeper系统的/consumers 目录。
例如,消费者组名为 test topic gl,主题名为 test topic,分区数为1,那么运行老版本消费者程序后,在 Zookeeper 系统中,偏移量提交的路径是/consumers/test topic_gl/ofisets/test topic/0Zookeeper 系统并不适合频繁地进行读写操作,因为 Zookeeper 系统性能降低会严重影响Kafka 集群的吞吐量。所以,在 Kafka 新版本消费者程序中,对偏移量的提交进行了重构,将其保存到 Kafka 系统内部主题中,消费者程序产生的偏移量会持续追加到该内部主题的分区中。Kafka系统提供了两种方式来提交偏移量,它们分别是自动提交和手动提交。
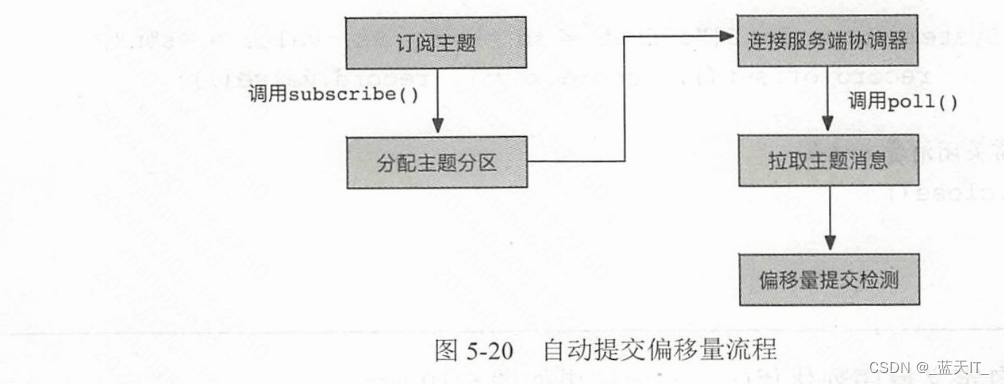
- 自动提交
使用 KafkaConsumer 自动提交偏移量时,需要在配置属性中将“enable.auto.commit”设置为 true,另外可以设置“auto.commit.interval.ms”属性来控制自动提交的时间间隔。Kafka 系统自动提交偏移量的底层实现调用了 ConsumerCoordinator 的 commitOffsetsSync()函数来进行同步提交,或者 commitOfsetsAsync()函数来进行异步提交。自动提交的流程如图5-20 所示。
- 手动提交
在编写消费者程序代码时,将配置属性“enable.auto.commit”的值设为“false”,则可以通过手动模式来提交偏移量。
KafkaConsumer消费者程序类提供了两种手动提交偏移量的方式–同步提交commitSync()函数和异步提交 commitAsync()函数。
阅读这两种提交方式的源代码可以发现,它们的底层分别由消费者协调器ConsumerCoordinator 的同步提交偏移量 commitOfsetsSync()函数和异步提交偏移量commitOffsetsAsync()函数来实现。
消费者应用程序通过 ConsumerCoordinator 来发送 OfsetCommitRequest 请求,Kafka 服务器端接收到请求后,由组协调器 GroupCoordinator 进行处理,然后将偏移量信息追加到 Kafka系统内部主题中。
使用多线程消费多个分区的主题
在分布式应用场景中,Kafka 系统为了保证集群的可扩展性,对主题添加了多分区的概念而在实际消费者程序中,随着主题数据量的增加,可能一个消费者程序难以满足要求。下面通过实例来演示多线程消费多分区主题。
/**
* 多线程消费者实例.
*
* @author smartloli.
*
* Created by May 6, 2018
*/
public class JConsumerMutil {
// 创建一个日志对象
private final static Logger LOG = LoggerFactory.getLogger(JConsumerMutil.class);
private final KafkaConsumer<String, String> consumer; // 声明一个消费者实例
private ExecutorService executorService; // 声明一个线程池接口
public JConsumerMutil() {
Properties props = new Properties();
props.put("bootstrap.servers", "dn1:9095,dn2:9094,dn3:9092");// 指定Kafka集群地址
props.put("group.id", "ke");// 指定消费者组
props.put("enable.auto.commit", "true");// 开启自动提交
props.put("auto.commit.interval.ms", "1000");// 自动提交的时间间隔
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 反序列化消息主键
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 反序列化消费记录
consumer = new KafkaConsumer<String, String>(props);// 实例化消费者对象
consumer.subscribe(Arrays.asList("kv3_topic"));// 订阅消费者主题
}
/** 执行多线程消费者实例. */
public void execute() {
// 初始化线程池
executorService = Executors.newFixedThreadPool(6);
while (true) {
// 拉取Kafka主题消息数据
ConsumerRecords<String, String> records = consumer.poll(100);
if (null != records) {
executorService.submit(new KafkaConsumerThread(records, consumer));
}
}
}
/** 关闭消费者实例对象和线程池 */
public void shutdown() {
try {
if (consumer != null) {
consumer.close();
}
if (executorService != null) {
executorService.shutdown();
}
if (!executorService.awaitTermination(10, TimeUnit.SECONDS)) {
LOG.error("Shutdown kafka consumer thread timeout.");
}
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
/** 消费者线程实例. */
class KafkaConsumerThread implements Runnable {
private ConsumerRecords<String, String> records;
public KafkaConsumerThread(ConsumerRecords<String, String> records, KafkaConsumer<String, String> consumer) {
this.records = records;
}
@Override
public void run() {
for (TopicPartition partition : records.partitions()) {
// 获取消费记录数据集
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
LOG.info("Thread id : "+Thread.currentThread().getId());
// 打印消费记录
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
/** 多线程消费者实例入口. */
public static void main(String[] args) {
JConsumerMutil consumer = new JConsumerMutil();
try {
consumer.execute();
} catch (Exception e) {
LOG.error("Mutil consumer from kafka has error,msg is " + e.getMessage());
consumer.shutdown();
}
}
}

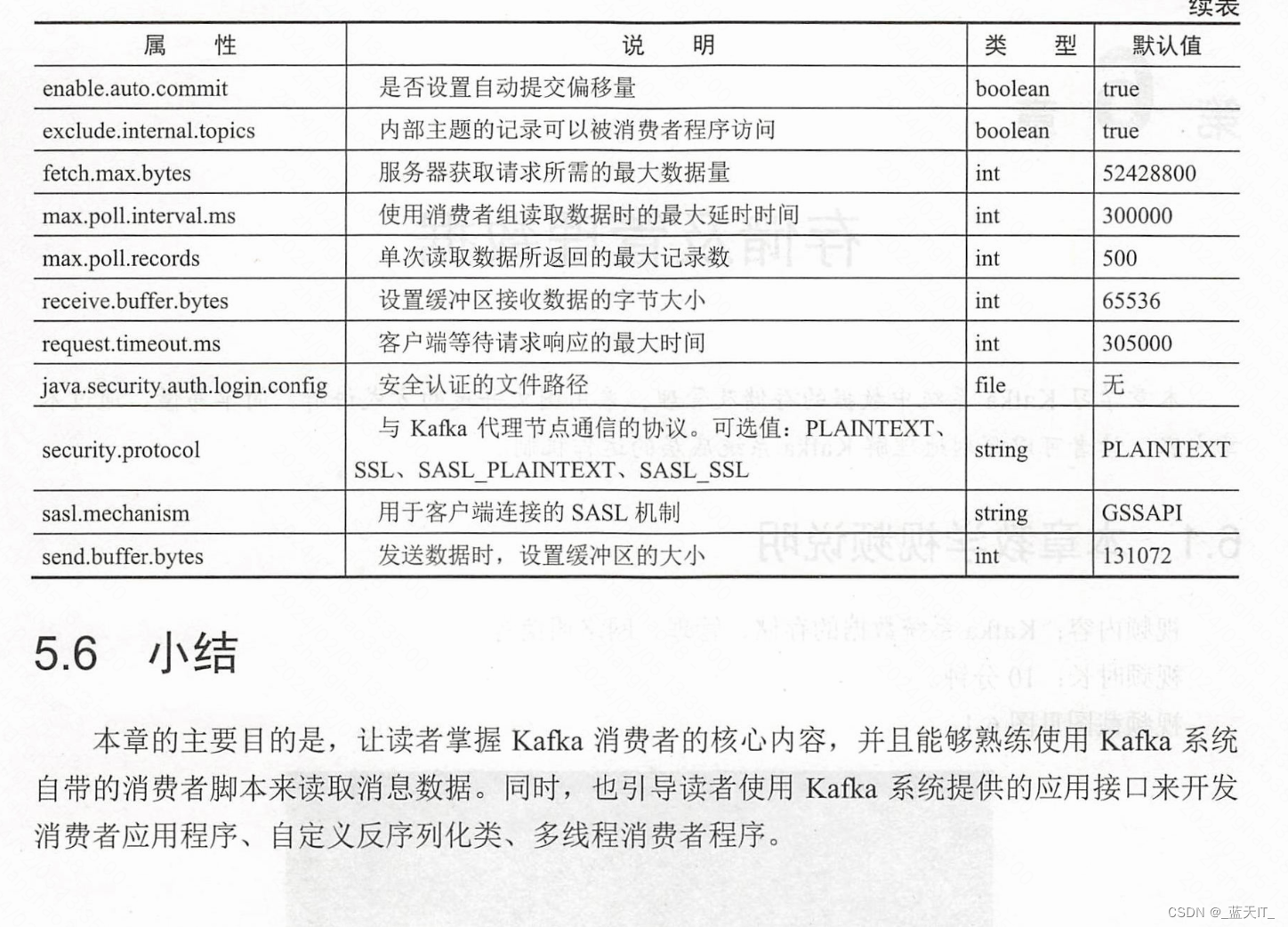
配置消费者的属性
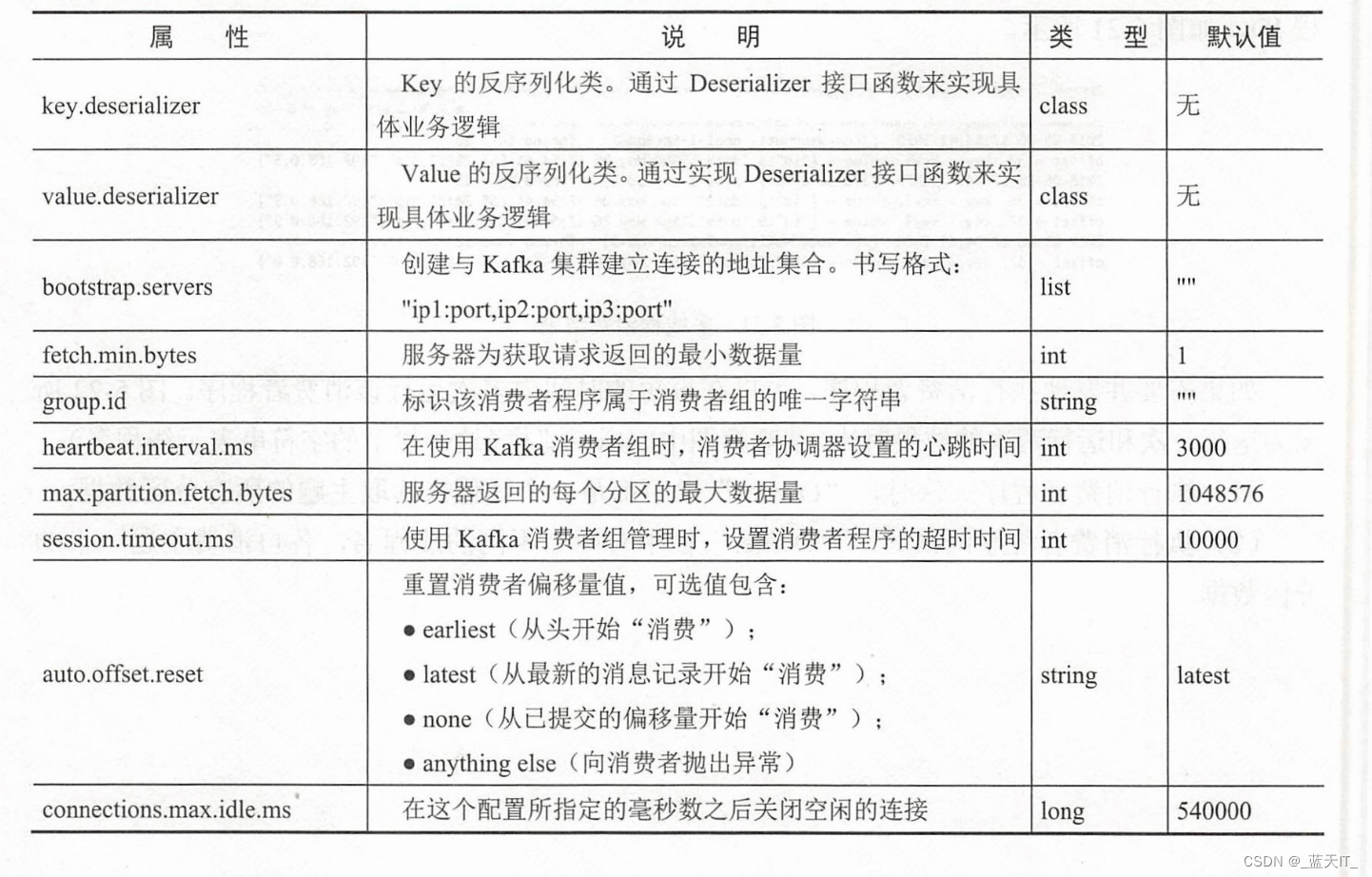
新版 Kanka 系统引入了新的消费者属性。在使用 Java 语言编写消费者应用程序时,可以按需添加一些属性来控制消息数据的读取。具体属性见表 5-2。
原文地址:https://blog.csdn.net/m0_63571404/article/details/136038321
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_68047.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!