本文介绍: 请求头User-Agent是比较常规的反爬手段,不同站点对其检测机制各异,有的是检测是否是合规的浏览器User-Agent,有的是在这基础上检测使用次数与频率,更有甚者是跟ip和cookie绑定在一起检测,这就要求我们能够动态去切换User-Agent(随机or判定切换)。
前言
请求头User-Agent是比较常规的反爬手段,不同站点对其检测机制各异,有的是检测是否是合规的浏览器User-Agent,有的是在这基础上检测使用次数与频率,更有甚者是跟ip和cookie绑定在一起检测,这就要求我们能够动态去切换User-Agent(随机or判定切换)。
关卡:实现动态切换User-Agent
scrapy设置User-Agent方式梳理
这里整理一下笔者已知的scrapy设置User-Agent的方式:



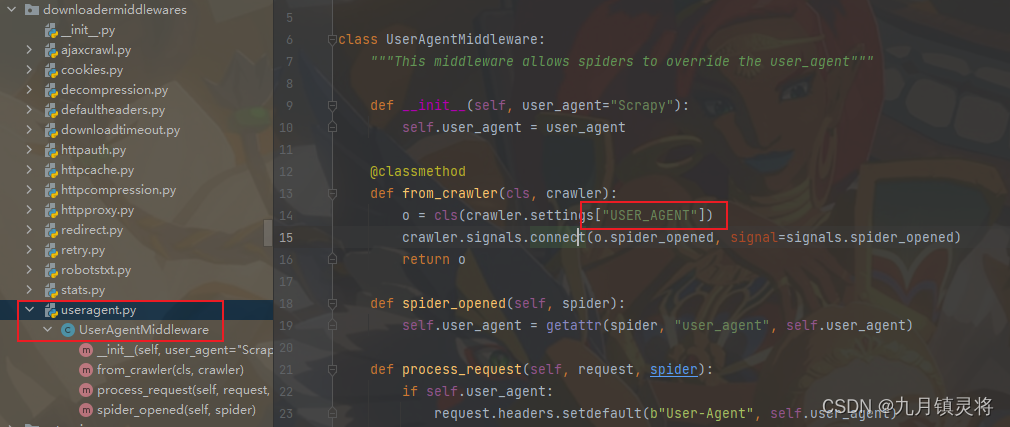
User-Agent生效梳理
我们来调试一下方式1、方式2和方式3,看看三种方式同时设置时最终是哪个方式生效
如下图,按顺序分别为三种方式设置好User-Agent
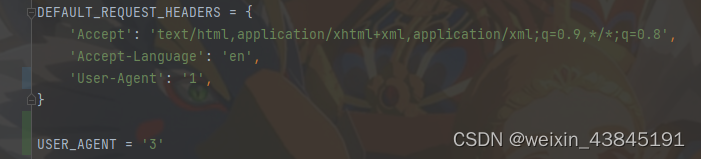

如下图,在发起请求生成request队列前,方式1设置成功
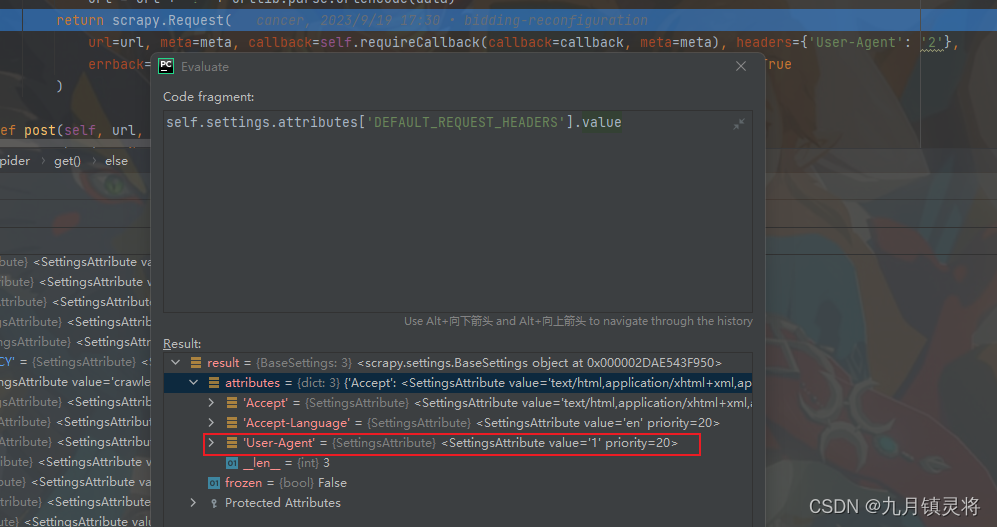
如下图,生成request队列后,经过下载中间件可以看到方式2覆盖了方式1
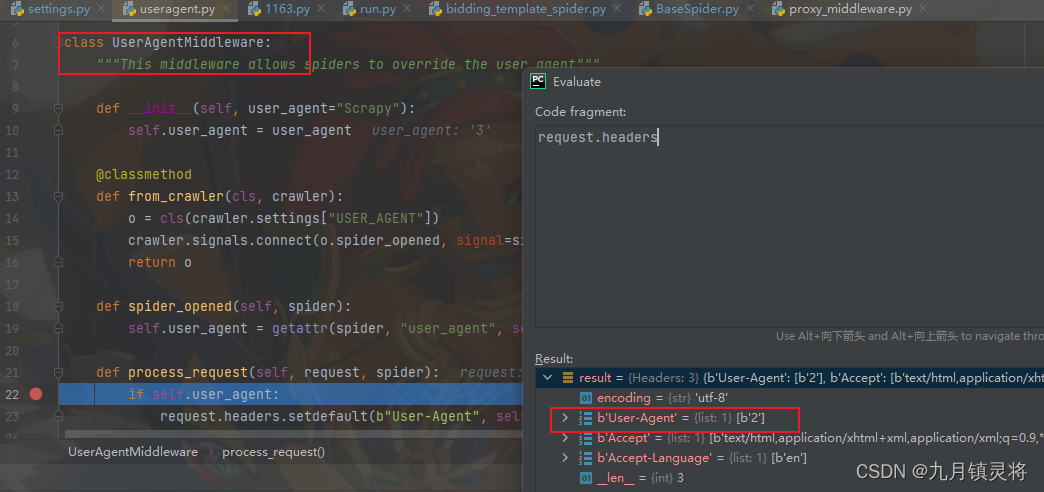
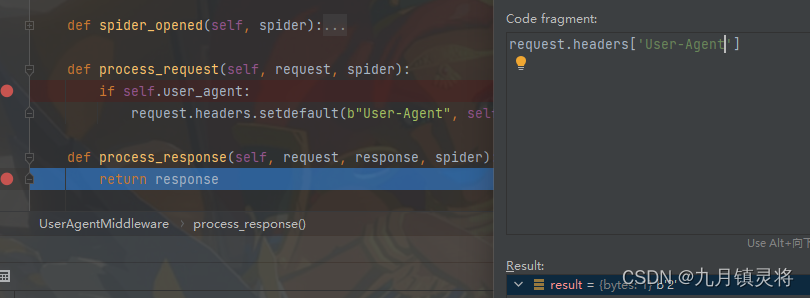
我们仔细看下中间件的代码,特别是process_request这个具体实现方法。
在此之前先了解一下setdefault这个方法:
setdefault是Python中字典的一个方法, 它用于在字典中查找指定键 如果键存在, 则返回对应的值; 如果键不存在,则在字典中添加该键,并将其值设置为指定的默认值
由于request.headers的User-Agent有值且是2,所以经过下载中间件后,它还是2
综上,我们可以得到结论:
为何选择在下载中间件中实现
首先要说明一下,并非一定要在中间件中才能实现User-Agent动态切换,也可以在脚本开发中对每次生成的request请求时动态设置User-Agent(请求头),但这种方式在笔者看来是不符合python之美的,功能未解耦而不够灵活,每个脚本都要单独实现,既繁琐又提高学习成本。
自定义User-Agent下载中间件
既然选择自定义中间件,那我们就可以随便玩了
首先思考一下,根据需求整理出设计方案:

结束
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

