本文介绍: 当一个用户在T日实时上传了自己的跑步记录,Flink节点1会计算出其 [当日0点起至此刻] 的跑步累计数据data1,Flink节点2会根据该用户id取hbase维表里查询其 [历史~T-1日] 的累计数据 data2 (hbase表里数据由odps每日更新,即T-1日的存量累计汇总数据),将data1和data2二者汇总,就可得到 用户历史至此时刻的汇总数据;在凌晨时分,ODPS计算T-1日数据期间,如果发生了对T-1日的数据查询,则无法获取到期望的T-1日数据,会继续使用T-2日的数据。
涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(一)
1.前置知识
ODPS(Open Data Platform and Service)是阿里云自研的一体化大数据计算平台和数据仓库产品,在集团内部离线作为离线数据处理和存储的产品。离线计算任务节点叫做Odps节点,存储的离线表叫做Odps表;
Flink: 实时计算引擎,本文代码开发和测试均基于集团内部实时计算平台,代码细节可能会和Flink 官方社区文档有些许不同,假如用于生产环境测试,参考Apache Flink 官方文档为准,但是技术方案是通用的哈;
2.项目背景
现有业务需求是 “根据用户注册以来的累计跑步里程,给用户发放勋章”,需要实时的计算出用户【历史~此时刻】的累计跑步数据。
比如说,某个用户20210101首次上传跑步记录,之后又多次上传跑步记录,我们需要实时的计算出,在20210101~当前时刻 期间,该用户累计跑了多少公里,累计跑了多少次等指标。上述指标的计算涉及用户历史至今的所有数据(2018~至今该用户所有数据),考虑使用批流结合的方式进行统计。参考批流结合的常用 lambda 方案:


3.解决方案
3.1 方案描述
离线链路设计
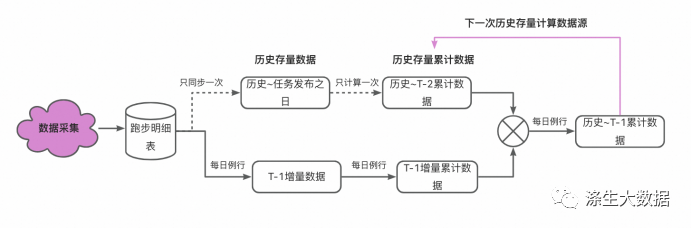
实时链路设计

实时离线链路融合
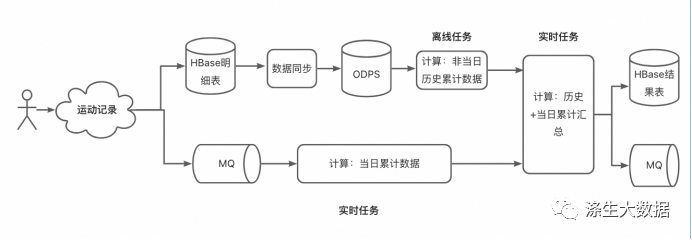

3.2 存在的问题
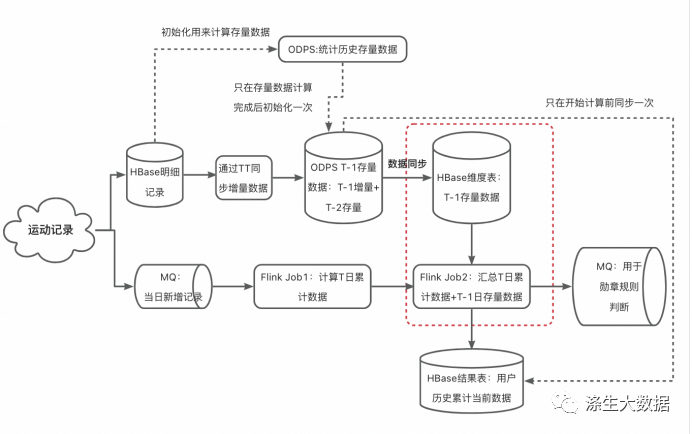
正常情况
异常情况
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。