HPA自动伸缩
HorizontalPodAutoscaler(简称 HPA )自动更新工作负载资源(例如Deployment或者Statefulset),目的是让pod可以自动扩缩工作负载以满足业务需求。
水平扩缩意味着对增加的负载的响应是部署更多的Pod。这与“垂直(Vertical)”扩缩不同,对于Kubernetes,垂直扩缩意味着将更多资源(例如:内存或CPU)分配给已经为工作负载运行的Pod。
如果负载减少,并且Pod的数量高于配置的最小值,HorizontalPodAutoscaler会指示工作负载资源(Deployment、StatefulSet或其他类似资源)缩减。
1.1命令行调整pod数量
root@k8s-master1:/app/yaml/HPA# kubectl scale --replicas=2 deployment tomcat-app -n webwork
1.2通过配置HPA调整副本数
K8s从1.1版本开始支持了HPA控制器,用于基于Pod中CPU/Memory资源利用率进行Pod的自动扩缩容。使用Metrices Server进行数据采集,通过API将数据提供给HPA控制器,实现基于某个资源利用率对Pod进行扩缩容
1.2.1 部署metrics-server
注意:使用HPA需要提前部署好metrics-server
1、到github下载metrics-server的yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.0/components.yaml
2、把yaml文件的谷歌镜像改成阿里云仓库镜像
sed -i s#k8s.gcr.io/metrics-server/metrics-server:v0.6.0#registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.0/g components.yaml
3、部署metrics-server
root@k8s-master1:/app/yaml/HPA# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-59df8b6856-tx7h2 1/1 Running 12 (22h ago) 11d
calico-node-5z4mh 1/1 Running 11 (22h ago) 11d
calico-node-8bjf5 1/1 Running 12 (22h ago) 11d
calico-node-gr2fc 1/1 Running 13 (22h ago) 11d
calico-node-t7nn5 1/1 Running 11 (22h ago) 11d
calico-node-w2dlz 1/1 Running 11 (22h ago) 11d
calico-node-z585t 1/1 Running 15 (52m ago) 11d
coredns-67cb59d684-9jrbw 1/1 Running 4 (22h ago) 7d20h
metrics-server-f4b9d85bd-grx2c 1/1 Running 1 (124m ago) 23h #pod是正常运行的
node-local-dns-48mwp 1/1 Running 11 (22h ago) 11d
node-local-dns-7kw8n 1/1 Running 11 (22h ago) 11d
node-local-dns-8fmbs 1/1 Running 11 (22h ago) 11d
node-local-dns-b464f 1/1 Running 11 (22h ago) 11d
node-local-dns-mdnkx 1/1 Running 11 (124m ago) 11d
node-local-dns-x5xrf 1/1 Running 11 (22h ago) 11d
1.2.2controller-manager启动参数
| 参数 | 含义 |
|---|---|
| –horizontal-pod-autoscaler-sync-period duration | 定义Pod水平伸缩时间间隔,默认为15s |
| –horizontal-pod-autoscaler-cpu-initialization-period | Pod初始化时间,在此期间内Pod的Cpu指标将不会被采纳,默认为5分钟 |
| –horizontal-pod-autoscaler-initial-readiness-delay | 用于设置Pod准备时间,在此期间内Pod统统被认为未就绪不采集数据,默认为30s |
kube-controller的默认配置位于:/etc/systemd/system/kube-controller-manager.service ,可以按需求进行修改
root@k8s-master1:/app/yaml/HPA# cat /etc/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/opt/kube/bin/kube-controller-manager
--bind-address=172.17.1.101
--allocate-node-cidrs=true
--cluster-cidr=10.200.0.0/16
--cluster-name=kubernetes
--cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem
--cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig
--leader-elect=true
--node-cidr-mask-size=24
--root-ca-file=/etc/kubernetes/ssl/ca.pem
--service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem
--service-cluster-ip-range=10.100.0.0/16
--use-service-account-credentials=true
--v=2
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
1.2.3 创建HPA
- 通过命令行创建
kubectl autoscale deployment tomcat-app --min=2 --max=5 --cpu-percent=30
- 通过yaml文件创建
root@k8s-master1:/app/yaml/HPA# cat hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: tomcat-app
spec:
maxReplicas: 5 #pod最大数量
minReplicas: 2 #pod最小数量
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tomcat-app #通过控制deployment控制器来伸缩
targetCPUUtilizationPercentage: 30 #触发pod伸缩的值,如果低于30%就缩容(最小2个),如果高于30%就扩容(最多5个)
故障:获取不到pod的cpu数据,根据错误信息是因为没有对pod做资源限制

排查思路:kubectl describe hpa tomcat-app查看错误信息
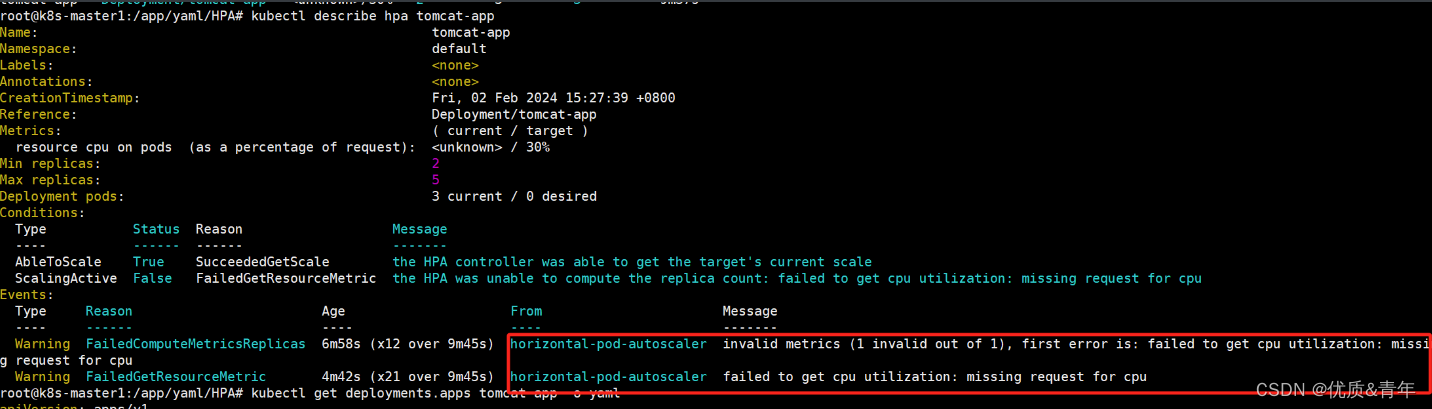
故障原因:没有对pod做cpu和内存方面的资源限制
解决办法:对pod做资源限制
root@k8s-master1:/app/yaml/HPA# cat deploy-tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat-app
name: tomcat-app
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-app
template:
metadata:
labels:
app: tomcat-app
spec:
containers:
- image: harbor.qiange.com/tomcat/tomcat-app1:v1
imagePullPolicy: IfNotPresent
name: tomcat-app1
resources:
requests:
cpu: "500m" # 请求 0.5 核心
memory: "512Mi"
limits:
cpu: 1 # 限制最多使用 1 核心
memory: "512Mi"
此时HPA控制器就能获取到cpu的资源使用率了
root@k8s-master1:/app/yaml/HPA# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
tomcat-app Deployment/tomcat-app 0%/30% 2 5 2 43m
1.2.4 测试自动缩容
#开始pod的数量
root@k8s-master1:/app/yaml/HPA# kubectl get pod
NAME READY STATUS RESTARTS AGE
mypod-5 1/1 Running 1 (22h ago) 23h
tomcat-app-6d59d44468-9gf25 1/1 Running 0 2m44s
tomcat-app-6d59d44468-dmhgx 1/1 Running 0 2m44s
tomcat-app-6d59d44468-qkt4l 1/1 Running 0 2m44
#默认是五分钟才出发
root@k8s-master1:/app/yaml/HPA# kubectl describe hpa tomcat-app
Name: tomcat-app
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 02 Feb 2024 16:33:11 +0800
Reference: Deployment/tomcat-app
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (2m) / 30%
Min replicas: 2
Max replicas: 5
Deployment pods: 3 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 2
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 4s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
root@k8s-master1:~# kubectl get pod|grep tomcat
tomcat-app-6d59d44468-9gf25 1/1 Running 0 9m55s
tomcat-app-6d59d44468-dmhgx 1/1 Running 0 9m55s
1.2.5 测试自动扩容
#进入某个pod中,使用openssl命令跑高CPU
root@k8s-master1:~# kubectl exec -it tomcat-app-6d59d44468-9gf25 sh
sh-4.2# openssl speed
root@k8s-master1:/app/yaml/HPA# kubectl describe hpa tomcat-app
Name: tomcat-app
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 02 Feb 2024 16:33:11 +0800
Reference: Deployment/tomcat-app
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 39% (197m) / 30%
Min replicas: 2
Max replicas: 5
Deployment pods: 5 current / 5 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 7m40s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Normal SuccessfulRescale 4m53s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 4m38s horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above target
root@k8s-master1:~# kubectl get pod|grep tomcat
tomcat-app-6d59d44468-9gf25 1/1 Running 0 16m
tomcat-app-6d59d44468-dmhgx 1/1 Running 0 16m
tomcat-app-6d59d44468-jsgc7 1/1 Running 0 5m7s
tomcat-app-6d59d44468-kz4ln 1/1 Running 0 4m52s
tomcat-app-6d59d44468-tchj4 1/1 Running 0 5m7s
原文地址:https://blog.csdn.net/weixin_58519482/article/details/135997186
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_68389.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!