merge()函数介绍
说明
pandas.merge(left, right, how: str = 'inner', on=None, left_on=None, right_on=None, left_index: bool = False, right_index: bool = False, sort: bool = False, suffixes='_x', '_y', copy: bool = True, indicator: bool = False, validate=None)
功能:用于合并两个 DataFrame 对象或 Series对象。只能用于两个表的拼接(左右拼接,不能用于上下拼接) 。
应用场景:数据合并 ( 数据合并的另一个常用函数是pd.concat())
参数说明:
left,right
用于拼接的两个表中,即使没有确定谁是主键,函数也会自动将两个表中的重复列作为主键,直接把一个表的名字传递给参数left,另一个表的名字传递给参数right
how
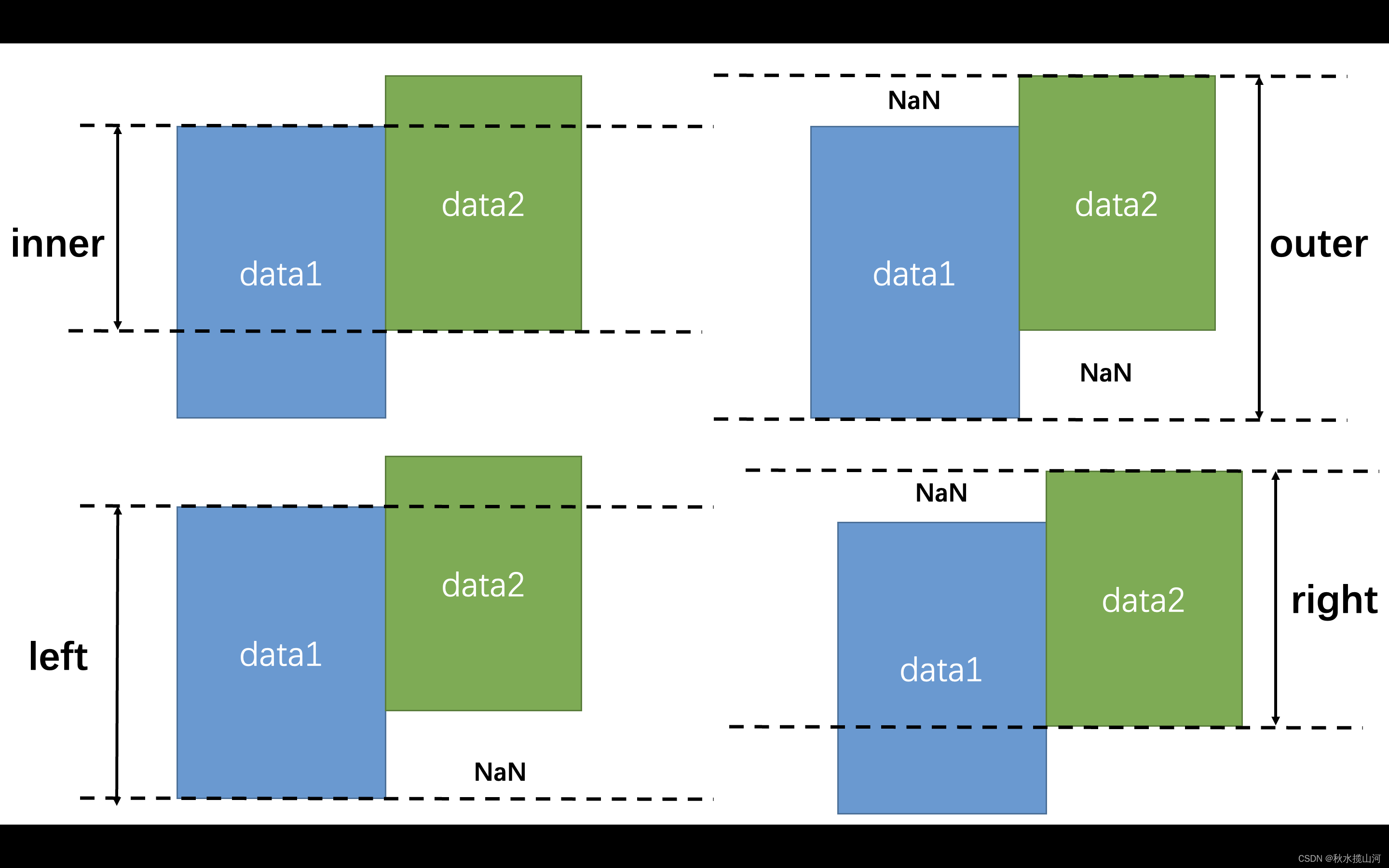
参数拼接方式,默认内连接(‘inner’)
内连接inner:将两个表主键一致的信息拼接到一起
外连接outer:保留两个表的所有信息,如果遇到对不齐的部分,用NAN填充
左连接left:保留左表的全部信息,把右表满足主键的行信息并进来,对不齐的部分用NAN填充
右连接right:保留右表的全部信息(同上)
示例:
import pandas as pd
data1 =pd.DataFrame({'a':['a1','a2','a3'],
'b':['b1','b2','b3'],
'key':['a','b','c'],
'key1':['d','e','f']})
data2 = pd.DataFrame({'c':['c1','c2','c3'],
'd':['d1','d2','d3'],
'key':['a','b','a'],
'key1':['d','e','e']})
result=pd.merge(data1,data2,on = ['key','key1'])
result1=pd.merge(data1,data2,how ="left",on = ['key','key1'])
result2=pd.merge(data1,data2,how ="right",on = ['key','key1'])
result3=pd.merge(data1,data2,how ="inner",on = ['key','key1'])
result4=pd.merge(data1,data2,how ="outer",on = ['key','key1'])
print(data1)
print(data2)
print(result)
print(result1)
print(result2)
print(result3)
print(result4)
a b key key1
0 a1 b1 a d
1 a2 b2 b e
2 a3 b3 c f
c d key key1
0 c1 d1 a d
1 c2 d2 b e
2 c3 d3 a e
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 a3 b3 c f NaN NaN
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 NaN NaN a e c3 d3
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 a3 b3 c f NaN NaN
3 NaN NaN a e c3 d3
Process finished with exit code 0
on
1、确定哪个字段作为主键
2、如果两个表中有两列以上信息相同,可以指定哪一列作为主键,如果不指定,相同信息的列都会作为拼接依据
3、merge()函数默认的是内连接,因此只拼接两表中拥有相同主键信息的行数据。
示例:
import pandas as pd
data1 =pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
data3= pd.DataFrame({'key':['K0','K1','K2','K3'],})
data2 = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
result1 = pd.merge(data1,data3,on = 'key')
result2 = pd.merge(data1,data2,on = 'key')
result3 = pd.merge(data3,data2,on = 'key')
print(data1)
print(data2)
print(data3)
print(result1)
print(result2)
print(result3)
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 B3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
3 K3 C3 D3
key
0 K0
1 K1
2 K2
3 K3
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 B3
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
3 K3 C3 D3
Process finished with exit code 0
left–index, right-index
1、除指定字段可以作为主键外,索引也可以考虑作为拼接的主键
2、默认为False,即不以索引为主键
3、如果两个表的索引完全一样,直接拼接效果很好,如果索引有不能对齐的地方,在默认的内连接情况下,只会把索引对齐的记录进行拼接
示例:
import pandas as pd
df1 = pd.DataFrame({'lkey': ['foo', 'ba', 'baz', 'fo'],
'value': [1, 2, 3, 4]},index=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]},index=['A', 'c', 'B', 'h'])
# result1 = pd.merge(df1,df2,left_on ='lkey')
result2 = pd.merge(df1,df2,left_on ='lkey',right_on ='rkey')
result3 = pd.merge(df1,df2,left_on ='lkey',right_on ='rkey',suffixes=("_lf","_rf"))
result4=pd.merge(df1,df2,left_index=True, right_index=True)
#result6=pd.merge(df1,df2,left_index=True)
result5=pd.merge(df1,df2,left_index=True, right_index=True,suffixes=("_lf","_rf"))
print(df1)
print(df2)
# print(result1)
print(result2)
print(result3)
print(result4)
print(result5)
#print(result6)
lkey value
A foo 1
B ba 2
C baz 3
D fo 4
rkey value
A foo 5
c bar 6
B baz 7
h foo 8
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 1 foo 8
2 baz 3 baz 7
lkey value_lf rkey value_rf
0 foo 1 foo 5
1 foo 1 foo 8
2 baz 3 baz 7
lkey value_x rkey value_y
A foo 1 foo 5
B ba 2 baz 7
lkey value_lf rkey value_rf
A foo 1 foo 5
B ba 2 baz 7
Process finished with exit code 0
left_on,right_on
两个表里没有完全一致的列名,但是有信息一致的列
该参数用来指定用来作主键的列名是哪一个
需要保证键值长度相等,len(left_on) == len(right_on)
suffixes
两个表中出现相同的列名,除了作为主键的列之外,其他名字相同的列被拼接到表中的时候会有一个后缀表示这个列来自于哪个表格,用于区分名字相同的列,这个后缀默认是(x和y)。这个后缀是可以自定义修改的
示例:
import pandas as pd
df1 = pd.DataFrame({'lkey': ['foo', 'ba', 'baz', 'fo'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
# result1 = pd.merge(df1,df2,left_on ='lkey')
result2 = pd.merge(df1,df2,left_on ='lkey',right_on ='rkey')
result3 = pd.merge(df1,df2,left_on ='lkey',right_on ='rkey',suffixes=("_lf","_rf"))
print(df1)
print(df2)
# print(result1)
print(result2)
print(result3)
lkey value
0 foo 1
1 ba 2
2 baz 3
3 fo 4
rkey value
0 foo 5
1 bar 6
2 baz 7
3 foo 8
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 1 foo 8
2 baz 3 baz 7
lkey value_lf rkey value_rf
0 foo 1 foo 5
1 foo 1 foo 8
2 baz 3 baz 7
Process finished with exit code 0
indicator
用于显示拼接后的表中信息来自哪个表
在表的最后一列显示left_only /right_only/both
默认False,可以修改为True
示例:
import pandas as pd
data1 =pd.DataFrame({'key':['K','1','K2','K3'],
'A':['A0','1','A2','A3'],
'B':['B0','B1','B2','B3']})
data2 = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
result=pd.merge(data1,data2,how ='outer',on = ['key'],indicator = True)
print(data1)
print(data2)
print(result)
key A B
0 K A0 B0
1 1 1 B1
2 K2 A2 B2
3 K3 A3 B3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
3 K3 C3 D3
key A B C D _merge
0 K A0 B0 NaN NaN left_only
1 1 1 B1 NaN NaN left_only
2 K2 A2 B2 C2 D2 both
3 K3 A3 B3 C3 D3 both
4 K0 NaN NaN C0 D0 right_only
5 K1 NaN NaN C1 D1 right_only
Process finished with exit code 0
参考文件:
https://zhuanlan.zhihu.com/p/340770510
原文地址:https://blog.csdn.net/qq_44823205/article/details/129935018
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6919.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!