前言
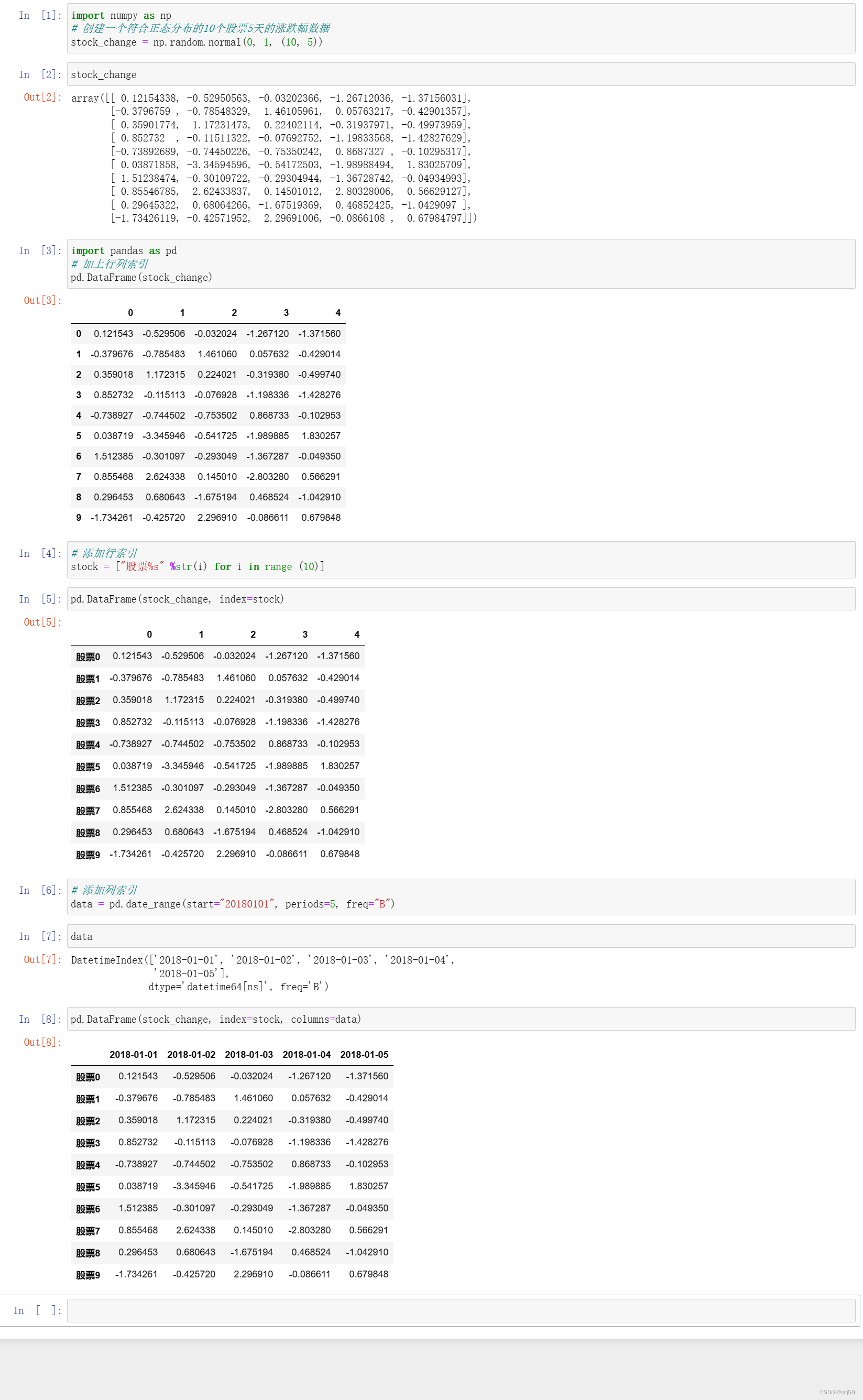
我们经常在寻找数据的某行或者某列的时常用到Pandas中的两种方法iloc和loc,两种方法都接收两个参数,第一个参数是行的范围,第二个参数是列的范围。
一、loc[]函数
二、iloc[]函数
三、详细用法
import pandas as pd
data={'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=pd.DataFrame(data)
frame.index=list('abcde')
frame

loc方法
- 1、单个行名/列名 或 行名/列名的列表
要求:读取第2行,行名为’b’。
frame.loc['b']

注意: 上面这种写法,运行“print(type(frame.loc[‘b’]))”可以知道返回的是<class ‘pandas.core.series.Series’>对象,如果要<class ‘pandas.core.frame.DataFrame’>对象可以改成frame.loc[[‘b’]]。
frame.loc[['b']]

要求:取第1、2列的第2与第5行,第1、2列的列名分别为’state’与’year’,第2、5行的行名分别为’b’和’e’。
frame.loc[['b','e'],['state','year']]

- 2、列名/行名的切片
要求:读取第2列,列名为’year’。
frame.loc[:,'year'] #返回的是<class 'pandas.core.series.Series'>对象。

frame.loc[:,['year']] #返回的是<class 'pandas.core.frame.DataFrame'>对象。

要求:取第2行第3列,第2行行名为’b’,第3列列名为’pop’。
frame.loc['b','pop']

要求:读取dataframe某个区域,比如第3列的第2到第5行,第3列为”pop”列,第2到第5行即b行到e行。
frame.loc['b':'e','pop'] #返回的是<class 'pandas.core.series.Series'>对象。

frame.loc['b':'e',['pop']] #返回的是<class 'pandas.core.frame.DataFrame'>对象。

要求:取第1、2列的第2到第5行,第1、2列的列名分别为’state’和’yea‘列,第2、5行的行名为’b’和‘e’行。
frame.loc['b':'e','state':'year'] #返回的是<class 'pandas.core.frame.DataFrame'>对象。

要求:根据判断条件读取,取第3列大于2的。
frame.loc[frame['pop']>2,'pop'] #返回的是<class 'pandas.core.series.Series'>对象。

frame.loc[frame['pop']>2,['pop']] #返回的是<class 'pandas.core.frame.DataFrame'>对象。

要求:根据函数读取,取第3列大于2的所有行与列。
frame.loc[lambda x: x['pop']>2]

iloc方法
- 1、单个下标 或 若干下标构成的列表,从0开始。
要求:取第2行的值。
frame.iloc[1]
注意: 上面这种写法,运行”print(type(frame.iloc[1]]))”可以知道返回的是<class ‘pandas.core.series.Series’>对象,如果要<class ‘pandas.core.frame.DataFrame’>对象可以改成frame.iloc[[1]]。
frame.iloc[[1]]
要求:取第1、2列的第2与第5行。
frame.iloc[[1,4],[0,1]]
- 2、下标的切片
要求:取第2列的值。
frame.iloc[:,1] #返回的是<class 'pandas.core.series.Series'>对象。

frame.iloc[:,[1]] #返回的是<class 'pandas.core.frame.DataFrame'>对象。
要求:取第2行第3列
frame.iloc[1,2]
要求:读取dataframe某个区域,比如第3列的第2到第5行。
frame.iloc[1:5,2] #返回的是<class 'pandas.core.series.Series'>对象。
frame.iloc[1:5,[2]] #返回的是<class 'pandas.core.frame.DataFrame'>对象。
要求:取第1、2列的第2到第5行。
frame.iloc[1:5,0:2] #因为是.iloc[]中用:表示从第几行/列到第几行/列是左闭右开的的方式,因此这里下标3表示第四行与第四列是取不到的。
frame.iloc[[1,2,3,4],[0,1]] #第二种写法
要求:当DataFrame的index是整数,取index为偶数的记录。
import pandas as pd
data={'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=pd.DataFrame(data)
frame
frame.iloc[lambda x: x.index % 2 == 0]

总结
共同点
- 两者都接收两个参数,第一个参数是行的范围,第二个参数是列的范围。
- 两者都可以有行索引值没有列索引值,但有列索引值前必须得有行索引值,但loc[]行索引值只能为名称形式来取,不能按下标形式来取。iloc[]则相反。
取第三列,无论使用loc[]函数还是iloc[]函数,如果没有行索引都会报错。
frame.loc['pop']
frame.loc[,'pop']
frame.iloc[,3]
不同点
参考文章:
https://blog.csdn.net/weixin_43298886/article/details/112632237
https://blog.csdn.net/Leon_Kbl/article/details/97492966
原文地址:https://blog.csdn.net/sodaloveer/article/details/133032337
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6925.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!