一.使用open()函数
介绍open()函数相关使用方法
==完整的语法格式为:==
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
1.file: 必需,文件路径(相对或者绝对路径)。
2.mode: 可选,文件打开模式
3.buffering: 设置缓冲
4.encoding: 一般使用utf8
5.errors: 报错级别
6.newline: 区分换行符
7.closefd: 传入的file参数类型
8.opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
| 模式 | 描述 |
|---|---|
| r | 只读的方式打开文件,文件会将指针放在文件的开头,是默认模式 |
| r+ | 打开文件用于读写 |
| w | 打开文件只用于写入,如果该文件存在则打开文件,并从头开始编辑,也就是原有的内容会被删除,如果文件不存在,则创建新文件 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
#write方法
f=open('test.txt','w')
f.write("每天哦")#写入数据
f.write("你好")
f.close()#关闭文件
print("写入完成")
#test.txt内容如下:
#每天哦你好
#再一次进行写入操作
f=open('test.txt','w')
f.write("每天都要加油哦!nihao1")#写入数据
f.write("sdhsgfjhkgkj")
f.close()
print("写入完成")
#test.txt内容如下:
#每天都要加油哦!nihao1sdhsgfjhkgkj
writelines() 方法用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要制定换行符 n。
f=open('test.txt','w')
f.writelines(["每天哦","skdhfkjgrfshj"])#写入数据
f.writelines(["每天哦n","skdhfkjgrfshj"])#加入换行符
f.close()
print("写入完成")
#文本结果如下:
#每天哦skdhfkjgrfshj每天哦
#skdhfkjgrfshj
write()里面只可以写入一个字符窜,不然会报错,同样writelines()里面需要时一序列,比如数组
**接下来我们来看看a模式**
#先使用w模式写入10个数
f=open('test.txt','w')
for i in range(10):
f.write(str(i)+'n')
f.close()
print("写入完成")
#文件内容结果如下:
0
1
2
3
4
5
6
7
8
9
#接着把w改写成a
f=open('test.txt','a')
for i in range(10):
f.write(str(i))
f.close()
print("写入完成,改写为a")
#文本内容显然已经在后面添加数字
0
1
2
3
4
5
6
7
8
9
0123456789
我们创建和打开文件还有种书写方式,相比之下比上述更方便,那就是with open
with open可以说是open的优化用法或高级用法,相比open更加简洁、安全。
open函数必须搭配.close()方法使用,先用open打开文件,然后进行读写操作,最后用.close()释放文件。with open则无需.close()语句,所以说简洁。如以下例子。虽然只少了一行代码,但也确实是少了。
with open('test.txt','a')as f:
for i in range(10):
f.write(str(i))
print("完成写入")
#with open("D:/learnpy/test.txt",'r')as f: 去掉r,斜杠变成反斜杠也可以
with open(r"D:learnpytest.txt",'r')as f:
l=f.read()
print(l)
print("finish")
#结果:
>>>
========================= RESTART: D:learnpyopen().py ========================
3月14日,英皇电影巡礼活动上,成龙、张学友、谢霆锋、张家辉等台下同框。这次的巡礼阵容十分豪华基本上把英皇的不老男神都请来了。
finish
>>>
1.保存格式为txt
```python
data="3月14日,英皇电影巡礼活动上,成龙、张学友、谢霆锋、张家辉等台下同框。这次的巡礼阵容十分豪华基本上把英皇的不老男神都请来了。"
with open('test.txt','w')as f:
f.write(data)
print("finish")
#其他数据照旧,主要是写入的类型属于字符串就行,建议是最后使用writelines(),这个可以写入多条数据,比较灵活

2.数据保存格式为csv
写入数据到csv文件,需要创建一个writer对象,主要用到两个方法。一个是writerow,这个是写入一行。一个是writerows,这个是写入多行。
import csv
with open("D:/learnpy/test.csv",'w',newline='')as f:
data={'name':'小明','age':'23','sex':'女'}
data1=[('xiao',21),('sdhfsj',89)]
#创建writer对象
writer=csv.writer(f)
#加入表头
writer.writerow(['姓名','年龄'])
writer.writerows(data1)#写入数据
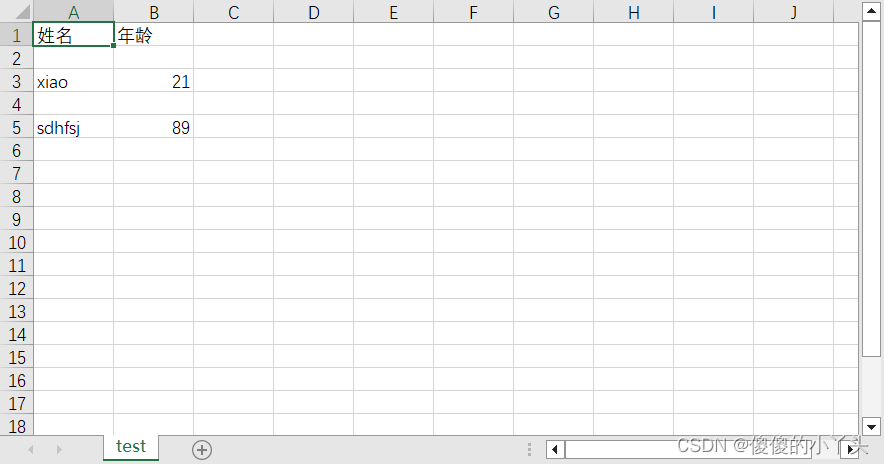
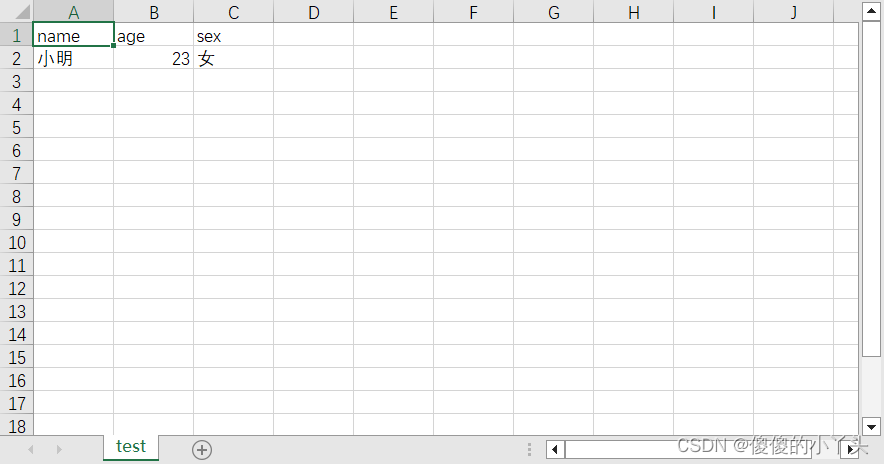
写好打开文件如下:

注意:如果不加newline=’ ‘就可能出现如下情况:
1. 数据为字典类型
import csv
with open("D:/learnpy/test.csv",'w',newline='')as f:
data={'name':'小明','age':'23','sex':'女'}
writer=csv.DictWriter(f,['name','age','sex'])
writer.writeheader()#写入数据表头
writer.writerow(data)
print("finish")
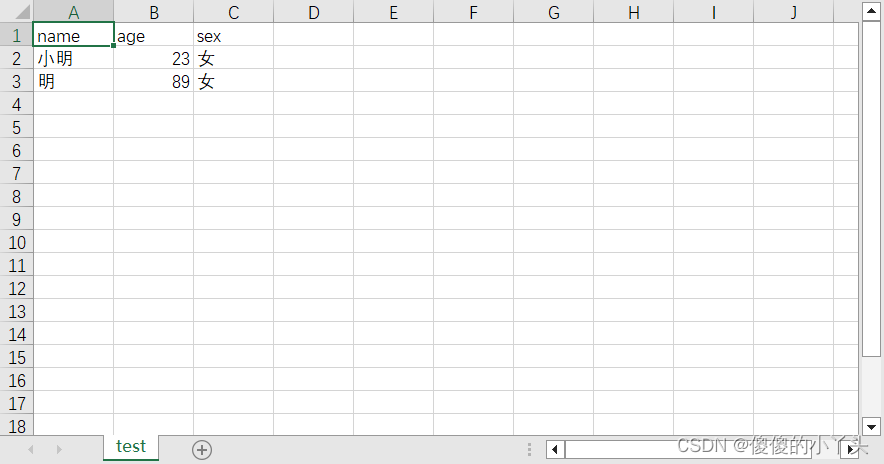
import csv
with open("D:/learnpy/test.csv",'w',newline='')as f:
data={'name':'小明','age':'23','sex':'女'}
data1={'name':'明','age':'89','sex':'女'}
writer=csv.DictWriter(f,['name','age','sex'])
writer.writeheader()#写入数据表头
writer.writerows([data,data1])
print("finish")
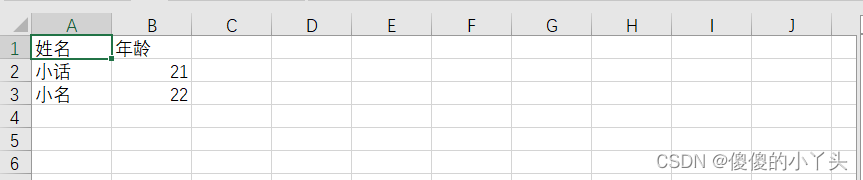
2. 数据为数组类型
import csv
with open("D:/learnpy/test.csv",'w',newline='')as f:
'''data={'name':'小明','age':'23','sex':'女'}
data1={'name':'明','age':'89','sex':'女'}
writer=csv.DictWriter(f,['name','age','sex'])
writer.writeheader()#写入数据表头'''
l1=['小话','21']
l2=['小名','22']
writer=csv.writer(f)
writer.writerow(['姓名','年龄'])#添加表头
writer.writerows([l1,l2])
print("finish")
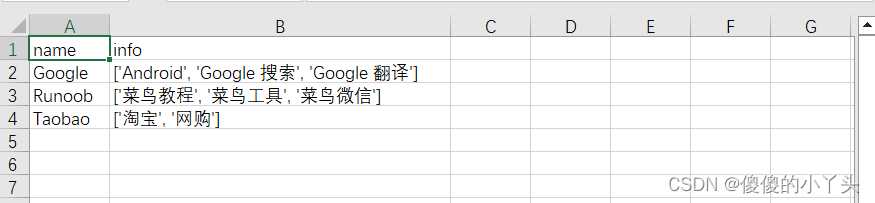
3. 数据格式为JSON格式
import csv
import json
with open("D:/learnpy/test.csv",'w',newline='')as f:
data=[{ "name":"Google", "info":[ "Android", "Google 搜索", "Google 翻译" ] },{ "name":"Runoob", "info":[ "菜鸟教程", "菜鸟工具", "菜鸟微信" ] },{ "name":"Taobao", "info":[ "淘宝", "网购" ] }]
print(type(data))
headers=data[0].keys()
json_values=[]
for i in data:
json_values.append(i.values())
writer=csv.writer(f)
writer.writerow(headers)#添加表头
writer.writerows(json_values)
print("finish")
4. 注意字典类型与JSON格式区别:
- 字典
字典是一种数据结构,是python中的一种数据类型;以 key:value 的形式存储数据,在一个字典中不允许出现两个相同的key值,如果出现,后面一个key值会覆盖前面的key值。
语法格式:
dic = {‘name’: ‘张’, ‘age’: 11, ‘性别’: ‘男’}
注意:key、value都可以用单引号、双引号引起来。- Json
Json是一种打包的数据格式,本质上是字符串,也是按照 key:value 来存储数据,key 只能是字符串,且可以有序、重复;必须使用双引号作为key或者值的边界符,不能使用单引号.
语法格式:
json = ‘{“name”: “jim”, “languages”: [“Python”, “Java”]}’
注意:key、value 必须用双引号引起来。
参考以下文章链接,详细介绍了两者区别以及相关转换: https://blog.csdn.net/qq_41674508/article/details/127430297
3.保存多媒体文件格式操作
import requests
url='https://gimg3.baidu.com/search/src=http%3A%2F%2Fpics4.baidu.com%2Ffeed%2F50da81cb39dbb6fd6abb732c2b227513962b37ed.jpeg%40f_auto%3Ftoken%3D8b6c38eae63037212d4e6bdbbcac2781&refer=http%3A%2F%2Fwww.baidu.com&app=2021&size=f360,240&n=0&g=0n&q=75&fmt=auto?sec=1678986000&t=347b98cded13deea606b43ecee356eae'
res=requests.get(url)
img=res.content#图片是以二进制方式打开
with open('1.jpg','wb')as f:
f.write(img)
print("下载成功")

2.保存音频
import requests
url='http://vd3.bdstatic.com/mda-mbtq5ugnhbjwzens/v1-cae/mda-mbtq5ugnhbjwzens.mp4?playlist=%5B%22sc%22%2C%221080p%22%2C%22hd%22%5D'
res=requests.get(url)
img=res.content
with open('2.mp4','wb')as f:
f.write(img)
print("下载成功")
4.批量下载保存文件操作
可参考一下这篇:链接: https://blog.csdn.net/qq_52764364/article/details/129602239
其他类型的文件格式类似
二·使用pandas保存文件
1.保存格式为csv
import pandas as pd
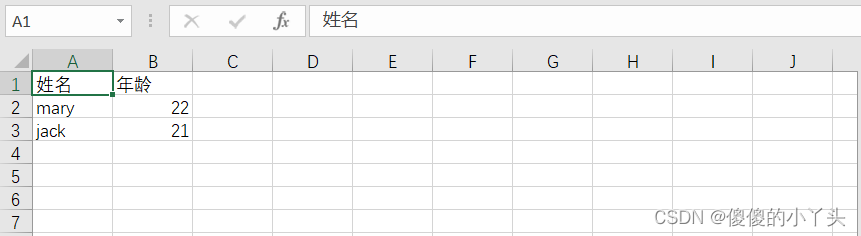
data=pd.DataFrame({"姓名":["mary","jack"],"年龄":[22,21]})
data.to_csv("info.csv",index=False)#默认index为true
print("保存完成")
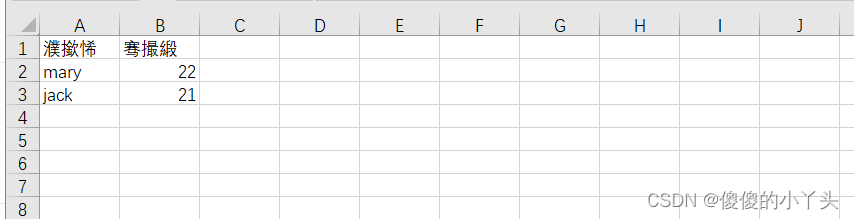
#只需要这样改,把编码方式改成utf-8_sig
data.to_csv("info.csv",index=False,encoding="utf-8_sig")
#结果如下:
2.保存格式为xlsx
header默认参数为True,如果没有设置header参数,它会自动添加列索引,
也可以在header=[“”,“”,“”]方式添加表头
或者不添加索引,如下图代码
import pandas as pd
data=pd.DataFrame([["ni","cjm",32],["你好","fjd",90]])
#data=pd.DataFrame({"姓名":["mary","jack"],"年龄":[22,21]})
data.to_excel("info.xlsx",header=False,index=False,encoding="utf-8_sig")
print("保存完成")

总结
上述内容是python保存数据的一些方法的总结,一些不同数据类型的保存方法选择,以及涉及到pandas的一些使用,其实我主要是为了,在网上爬取数据时,针对爬取的数据进行怎么样的保存处理方法做了一个大致的总结,因为自己每次保存数据都不知道从哪里下手,不过,这次好好地整理了一下,这样下次就以更快的保存数据,还有就是,有时候保存数据或者读取数据,会出现报错的情况或者权限不允许,这建议把保存文件的路径写完整,试一试
原文地址:https://blog.csdn.net/qq_52764364/article/details/129527369
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6935.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!