一、效果展示
注:此项目纯作者自己原创,创作不易,不经同意不给予搬运权限,转发前请联系我,源码较大需要者评论获取,谢谢配合!
1、未启动飞行模型无人机的目标检测。
DjiTello + YOLOV5抽烟检测
2、启动飞行模型的无人机目标检测。
DjiTello + YOLOV5抽烟检测
二、实现方法和技术
本次抽烟检测采用yolov5s为基础模型进行训练,训练集采用了标注的抽烟人群数据集大约3000-5000张图片(图片均为爬虫获取),尺寸640*640,训练Epoch为300,损失函数采用Adaw,batch_size为64,至此训练完成。然后,最酷的部分来了!我们把训练完成的模型和 PyQT5 结合起来,成功地部署到了 DJITello 无人机上。这就意味着我们的无人机现在可以实时地进行抽烟检测了!想象一下,一个无人机飞过,能够检测到周围是否有人在抽烟。这就是我们这次项目的技术亮点啦!
所采用技术:目标检测、深度学习、QT、Pytorch、djitello无人机编程基础、python爬虫等等。
三、项目涉及难点和优化
1、数据标注较为繁琐
2、各项技术结合起来较为困难,如yolo+tello+qt
3、电脑控制无人机不太方便
4、训练时间较长
5、优化了小目标检测层的细节
6、优化了损失函数
四、基础知识介绍
1、目标检测:
目标检测是一种计算机视觉技术,专注于识别和定位图像或视频中的特定对象。它不仅能够识别图像中的物体,还能够指示这些物体在图像中的位置。
有几种常见的目标检测技术,其中包括:
-
传统方法: 传统的目标检测方法通常使用特征工程和手动设计的算法来识别对象。这些方法包括 Haar 级联、HOG 特征和基于图像分割的技术。
-
深度学习方法: 近年来,深度学习技术,特别是卷积神经网络(CNN),已经成为目标检测领域的主流。著名的深度学习模型如 R-CNN、Fast R-CNN、Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot Multibox Detector)等,大大提升了目标检测的准确性和速度。
这些技术在目标检测中的应用非常广泛,涵盖了许多领域,例如自动驾驶、安防监控、医学图像分析、工业质检和无人机等。目标检测技术的不断进步和优化,使得它在实际应用中变得更加可靠和高效。
2、Djitello:
DJITello是一款小型的无人机,可以通过编程语言控制和操控,通常使用Python进行编程。它的主要特点是易于上手和编程,适合初学者和教育用途。
Python与DJITello结合使用可以通过Tello SDK实现。Tello SDK提供了一组命令和API,允许开发者使用Python编写脚本来控制无人机的动作、飞行和获取无人机状态等操作。
使用Python与DJITello结合可以完成许多任务,例如:
整合Python和DJITello为开发者提供了一种快速而灵活的方式,可以通过编程控制无人机,开发各种类型的应用和项目。
3、PYQT5
PyQt5是一个用于创建图形用户界面(GUI)的Python库,它基于Qt框架,提供了丰富的工具和组件,用于构建跨平台的应用程序。它允许开发者利用Python语言的简洁性和强大性,创建出具有各种功能和外观的用户界面。
一些PyQt5的主要特点包括:
-
跨平台性: PyQt5能够在不同的操作系统上运行,包括Windows、MacOS和Linux等。
-
支持多种编程风格: 可以使用Qt Designer(图形化界面设计工具)创建UI并将其与Python代码相结合,也可以直接使用Python代码编写UI。
-
事件驱动编程: PyQt5是基于事件驱动的,允许通过信号(signal)和槽(slot)的机制来处理用户交互和其他事件。
使用PyQt5,开发者可以创建出具有良好交互性和用户友好界面的应用程序,涵盖了各种领域,包括桌面应用、科学计算、游戏开发等。它提供了丰富的工具和灵活性,让开发者能够根据需求创建出多样化的应用。
4、Python爬虫
Python爬虫技术是利用Python编程语言从互联网上获取信息的一种技术。它可以用来自动化地访问网页、抓取数据、分析网页内容并进行处理。Python拥有许多强大的库和工具,使得编写爬虫变得相对简单。
一些常用的Python库和框架用于爬虫技术包括:
Python爬虫技术的流程一般包括以下步骤:
- 发送HTTP请求:使用Requests库或类似工具向目标网站发送请求,获取页面内容。
- 解析页面:使用Beautiful Soup等工具解析HTML或XML页面,提取需要的数据。
- 数据处理:对提取的数据进行处理、清洗或存储,可以存储到数据库、文件或进行进一步的分析。
- 循环迭代:根据需求,可以设置循环迭代,自动访问多个页面或执行多次爬取过程。
Python爬虫技术在许多领域有广泛的应用,包括数据采集、搜索引擎优化、舆情分析、价格监控等。需要注意的是,合法合规是使用爬虫的重要考虑因素,遵守网站的Robots协议和避免对服务器造成负担是保持良好爬虫行为的重要原则。
五、部分代码和图片展示
1、训练参数展示
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-csv', action='store_true', help='save results in CSV format')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt2、无人机展示

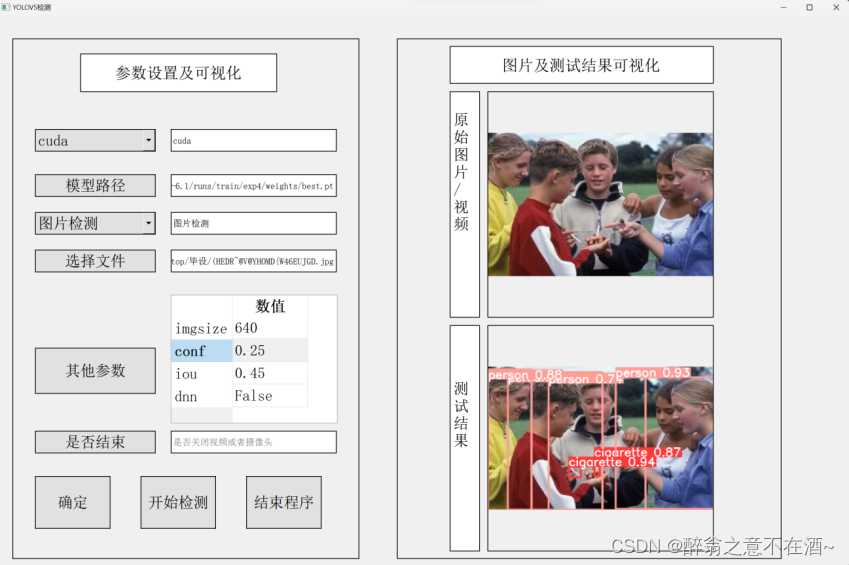
3、QT界面展示

4、检测结果展示
六、总结
深度学习在图像处理和机器视觉等领域广泛应用,其中基于AI的技术如YOLOv5抽烟检测方法,提高了处理效率和准确性。
YOLOv5是一种实时目标检测技术,可识别物体的尺寸、形状、位置和类别。本文改进了YOLOv5网络结构,增加了小目标检测层,采用CIOU损失函数提升模型准确性。结果显示,改进后的模型准确率提高了约6.6%。
然而,传统方法仍然面临挑战。特别是对于大型目标,模型可能出现漏报或误报。抽烟者的移动和不同姿势也增加了检测难度。未来可考虑采用自适应技术和更多数据集,改进损失函数和参数,提高模型的鲁棒性和精确性。
总体而言,该模型能有效检测抽烟者的位置和类型,但仍需进一步改进以提高性能和可靠性。
原文地址:https://blog.csdn.net/qq_58535145/article/details/134638522
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_700.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!