本文介绍: redis持久化有两种方式:RDB和AOFRDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point–in–time snapshot)。实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。这个快照文件就称为RDB文件(dump.rdb),其中,RDB就是Redis DataBase的缩写。AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据
RDB 持久化


1、修改配置文件:redis.conf

2、RDB模式自动触发保存快照

3、RDB模式手动触发保存快照


4、RDB的优缺点

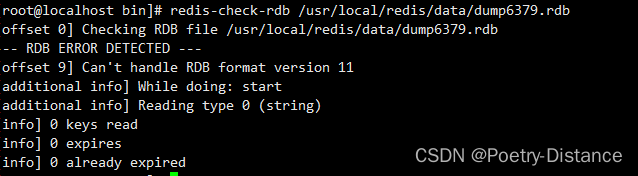





AOF持久化
1、AOF持久化工作流程
2、修改配置文件开启AOF



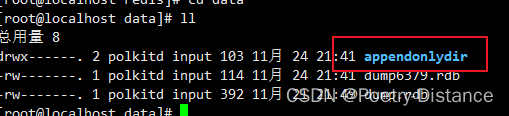



3、AOF优缺点
4、AOF的重写机制原理
RDB+AOF混合模式
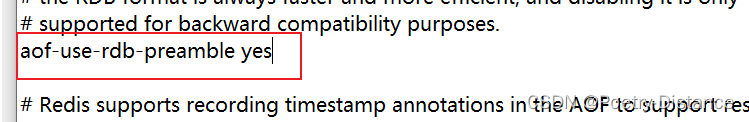
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






