本文介绍: Batch Normalization是深度学习中常用的技巧,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Ioffe and Szegedy, 2015) 第一次介绍了这个方法。这个方法的命名,明明是Standardization, 非要叫Normalization, 把本来就混用、意义不明的两个词更加搅得一团糟。
1. 简介
Batch Normalization是深度学习中常用的技巧,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Ioffe and Szegedy, 2015) 第一次介绍了这个方法。
这个方法的命名,明明是Standardization, 非要叫Normalization, 把本来就混用、意义不明的两个词更加搅得一团糟。那standardization 和 Normalization有什么区别呢?
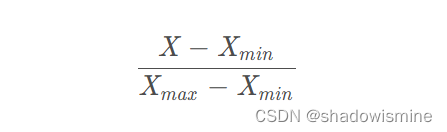
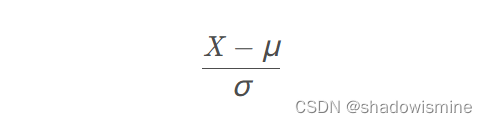
Batch-Norm 是一个网络层,对中间结果作上面说的 standardization 操作。实际上 standardization 也可以叫做 Z-score normalization。所以可以这样理解,standardization 是一种特殊的 normalization。normalization 作为一个 scaling 的大类,包括 min–max scaling,standardization 等。
2. BatchNorm


3. BN 的特点

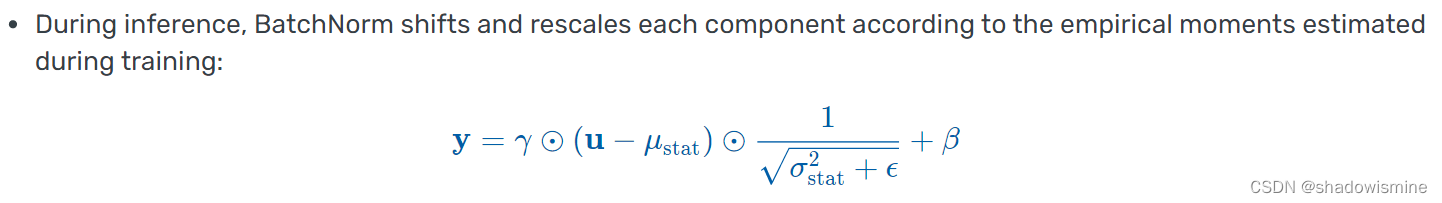
4. BN 的位置
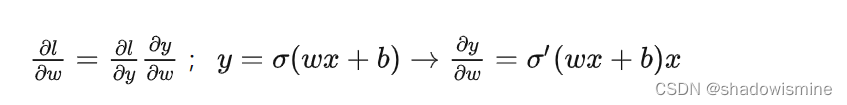
5. BN的理解与延伸
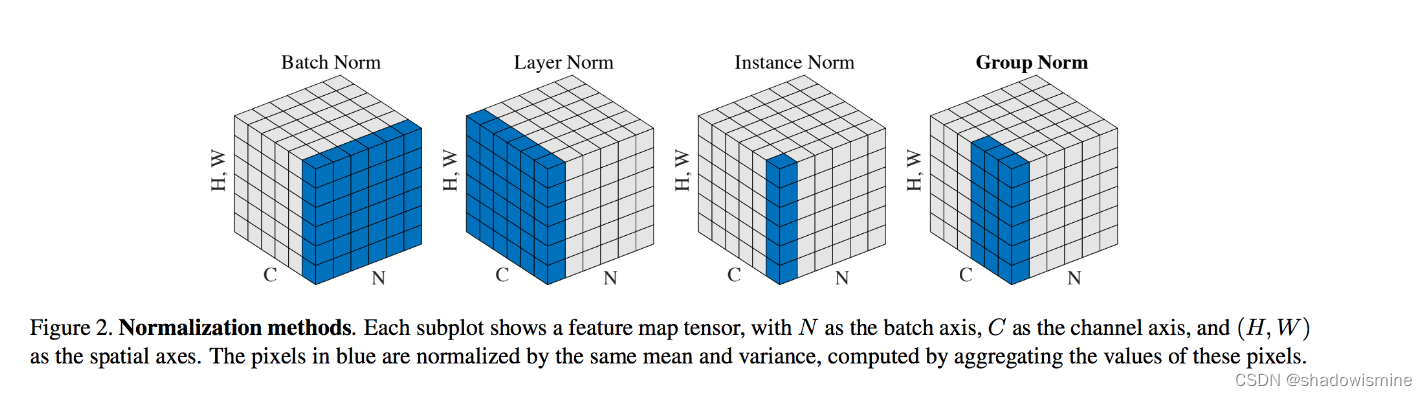
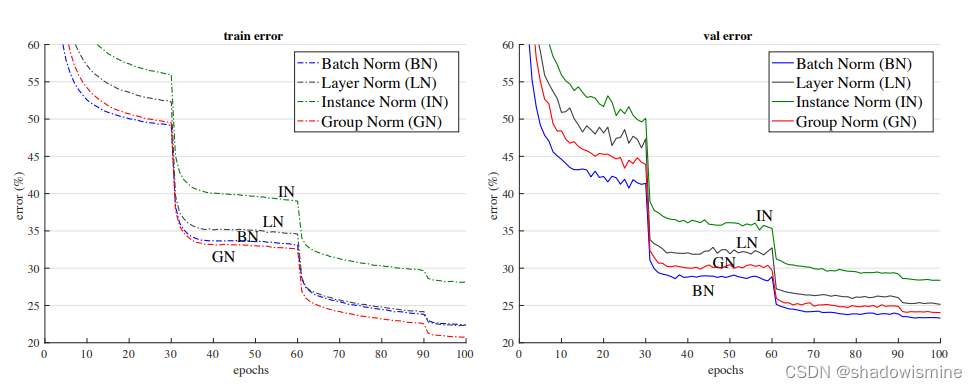
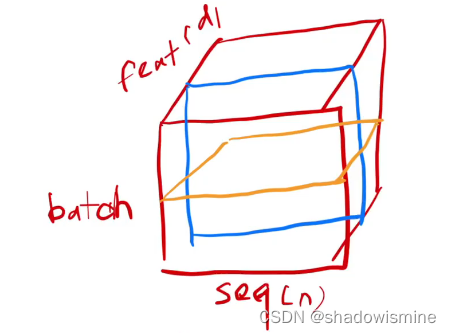
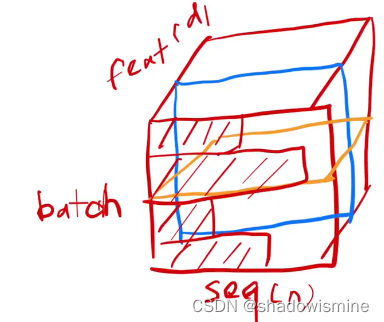
6. BN vs LN

7. BN代码实现
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





